本文主要是介绍C语言数据结构(4)——线性表其三(双向链表),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
欢迎来到博主的专栏——C语言数据结构
博主ID:代码小豪
文章目录
- 链表的种类
- 头结点
- 循环链表
- 双向链表
- 带头双向循环链表
- 带头双向循环链表的定义与初始化
- 空链表
- 尾插法
- 打印双向链表
- 头插法
- 查找指定数据项的节点
- 在指定位置之后插入节点
- 指定位置的删除
- 双向链表的销毁
- 顺序表与链表的对比
链表的种类
前面介绍了链表的种类之一——单链表,单链表的全称为不带头不循环单向链表
根据链表的性质,我们将链表分为以下几种:
(1)带头节点or不带头节点
(2)单向or双向
(3)循环与不循环
根据这些性质进行排列组合得出的链表共有八种
| 带头 | 不带头 | |
|---|---|---|
| 单向循环 | 带头单向循环链表 | 不带头单向循环链表 |
| 双向循环 | 带头双向循环链表 | 不带头双向循环链表 |
| 双向不循环 | 带头双向不循环链表 | 不带头双向不循环链表 |
| 单向不循环 | 带头单向不循环链表 | 不带头单向不循环链表 |
头结点
将有头结点的链表称为带头链表,没有头结点的链表称为不带头链表。
前面提到了指向第一个节点的指针被称为头指针,而头指针常常作为链表的函数返回值,如果出现了头指针需要不断修改的情况,可能会导致代码的繁冗。
比如写一个将多个链表进行合并的代码,头指针根据要求会有多种可能性,如果将这些可能性都进行判断的话,难免会让导致代码冗余。
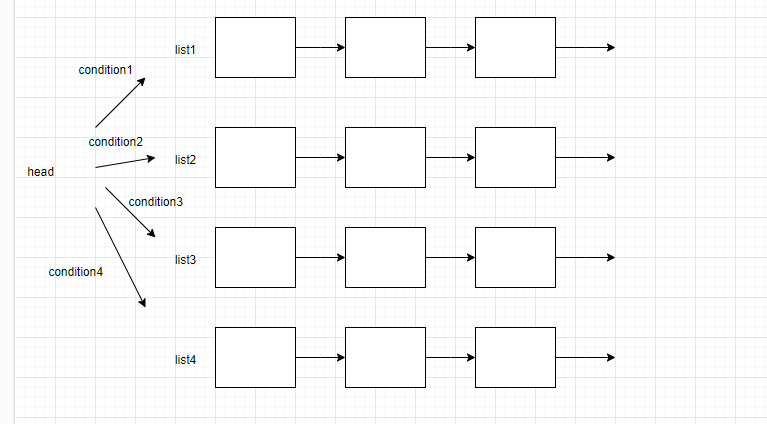
那我们直接定义一个头结点,这个头结点的作用是当做一个链表的表头,但是不记录有效数据,只纪录指向合并后的链表的第一个节点。
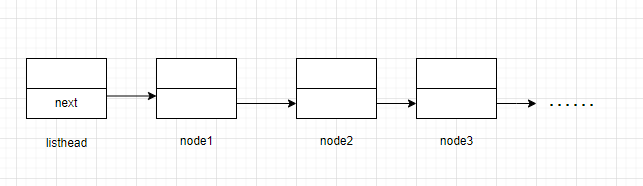
可以发现,如果不带头结点,那么合并的链表需要区分头指针到底是list1或者其他,而带了头结点,只需要将listhead->next指向合并好的链表就行了。
即将
if(condition1)
return list1;
if(condition2)
return list2;
if(condition3)
return list3;
if(condition4)
return list4;
省略成
return listhead->next;
总结一下头指针的作用
头结点最主要的作用就是统一链表的操作。
(1)比如头指针为空的时候不能使用phead->next,但是头结点不会为空,所以可以使用listhead->next。
(2)有了头结点之后,删除和插入结点的时候不再需要判断头指针的指向问题,将任意位置的插入或删除节点的操作统一起来。(前面写的任意位置的插入节点的函数由于没有头节点,所以插入第一个节点前的位置需要用到头插法,进而导致代码冗余)
循环链表
将链表的最后一个结点的后继置为NULL的链表被称为不循环链表
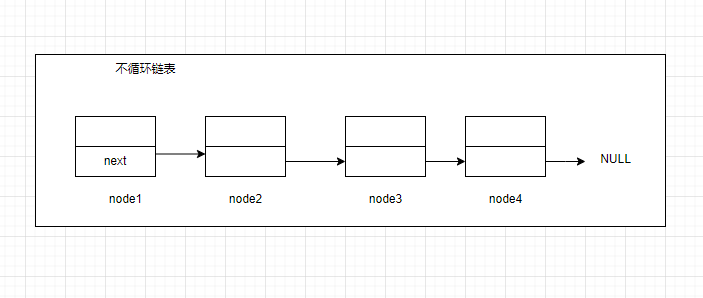
如果我们要将链表实现多次遍历的操作时,不循环链表显然不满足要求,因为不循环链表遍历到表尾的时候就会停止遍历,无法进行多次遍历链表。
如果将表尾节点与表头节点连接起来,就能实现遍历表尾之后回到表头,重新遍历一次
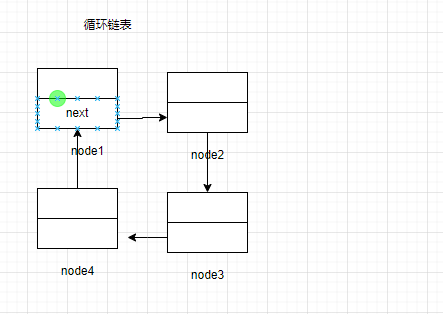
循环链表的实现也非常简单,将表尾的next指向表头即可
ptail->next=phead;
双向链表
单链表的节点存储的只有一个指向后继元素的指针,这就会导致当节点来到下一个节点时,丢失上一个节点的地址,导致无法对当前节点的前驱节点进行操作。
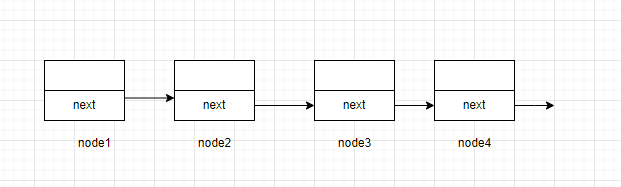
为了解决这个问题,我们在定义链表的节点类型时可以加入一个指向前驱元素的指针,使得节点的前驱元素也被记录,这样子就能实现回退的操作。
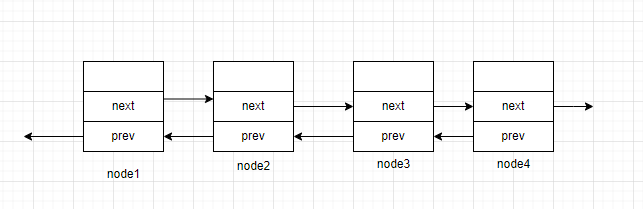
带头双向循环链表
前篇文章讲了不带头单向不循环链表(单链表),已经了解了其中的三个特性,剩下的三个特性将通过讲解带头双向循环链表带着大家了解。
带头双向循环链表的定义与初始化
先来定义带头双向循环链表(后面简称双向链表)的节点数据类型。
双向链表的节点需要三个数据存储,分别是节点的数据,后继节点的指针,以及前驱节点的指针。
节点类型的定义如下:
typedef int LTData;
typedef struct ListNode
{LTData data;struct ListNode* next;struct ListNode* prev;
}Node;
由于双向链表具有头结点,因此需要对头结点进行创建与初始化。
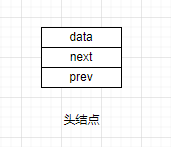
前面提到了双向链表需要具备以下结构:
(1)带头
(2)循环
(3)双向
而头结点作为双向链表的一部分,在初始化的的时候也要满足以上要求,所以头结点应该初始化成这样:
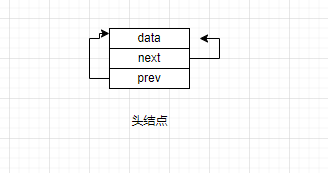
头结点的初始化函数如下:
Node* HeadNodeInit(void)
{Node* head = (Node*)malloc(sizeof(Node));if (!head){perror("Headinit fail");exit(EXIT_FAILURE);}head->data = -1;head->next = head;head->prev = head;return head;
}
使用这个函数将会生成一个头结点,并将该头节点返回。函数的调用方式如下:
Node* plist = HeadNodeInit();
空链表
不带头的链表如果为空,就将头指针置为NULL,或者将头指针为NULL的链表视为空链表。
而带头的链表如果为空链表,就说明链表当中只有一个头结点,将只有头结点的链表视为空链表。
比如上一章的单链表,如果要创造一个空链表,只需要声明一个头指针,并将头指针置为空即可
phead=NULL;
而若是创建带头的空链表,则需要创建并初始化头结点。
plist=HeadNodeInit();
尾插法
将头结点传入函数,通过头结点来对链表进行操作
void ListDataPushBack(Node*headnode,SLData n);
先来讲讲尾插的原理,假设当前链表中有多个节点
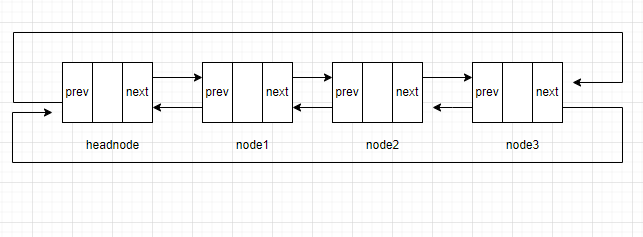
如果在表尾插入新的节点,首先要找到表尾,由上图可见,由于链表是循环的,只需要访问头结点的前驱节点即可找到尾结点。
ptail=headnode->prev;
接着便是将新的节点插入表尾。方法如下:
(1)将新的节点的前驱节点设为表尾
(2)将新节点的后继节点设为头结点
(3)将表尾的后继设为新节点
(4)将头结点的前驱设为新节点
完成后新的节点将会插入至链表的末尾部分
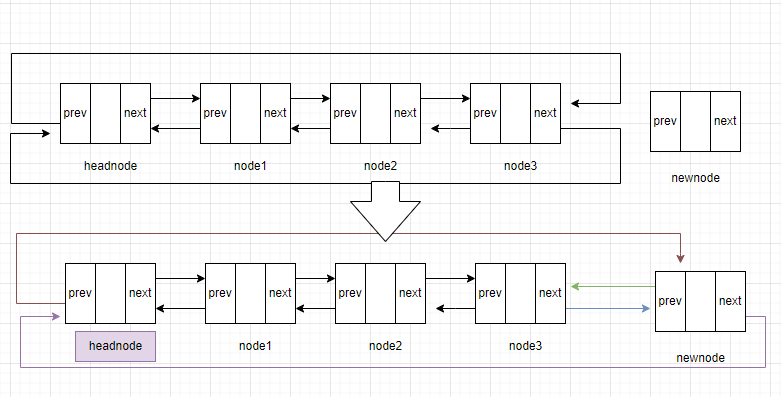
避免代码冗余,将生成新节点的代码封装成函数,后续生成新节点的操作,都会通过调用这个函数实现
Node* CreateNewNode(LTData n)
{Node* newnode = (Node*)malloc(sizeof(Node));if (newnode == NULL) {perror("newnode malloc fail");exit(EXIT_FAILURE);}newnode->data = n;newnode->next = NULL;newnode->prev = NULL;return newnode;
}
尾插法的函数实现如下:
void ListDataPushBack(Node* headnode,LTData n)
{Node* newnode = CreateNewNode(n);Node* ptail = headnode->prev;newnode->next = headnode;newnode->prev = ptail;ptail->next = newnode;headnode->prev = newnode;
}
打印双向链表
为了便于调式,可以封装一个打印双向链表的函数。
打印的方法如下:
通过遍历链表,将链表中除了头结点以外的所有节点的数据打印至屏幕。由于双向链表具有循环的性质,因此从第一个节点开始遍历至头结点为止。
void printlist(Node* headnode)
{Node* pcur = headnode->next;while (pcur!= headnode){printf("%d->", pcur->data);pcur = pcur->next;}printf("headnode\n");
}
可以用打印的方式测试尾插法是否符合要求,测试方法如下:
Node* plist = HeadNodeInit();ListDataPushBack(plist, 1);ListDataPushBack(plist, 2);ListDataPushBack(plist, 3);ListDataPushBack(plist, 4);printlist(plist);
打印结果如下,测试结果为尾插法符合要求。

头插法
将节点插入头结点之后,第一个节点之前的方法称为头插法。
头插法的方法如下:
(1)将新节点的后继节点设置为第一个节点
(2)将新节点的前驱节点设置为头结点
(3)将第一个节点的前驱节点设置为新节点
(4)将头结点的后继节点设置为新节点
注意步骤(3)和(4)的顺序不能调换。
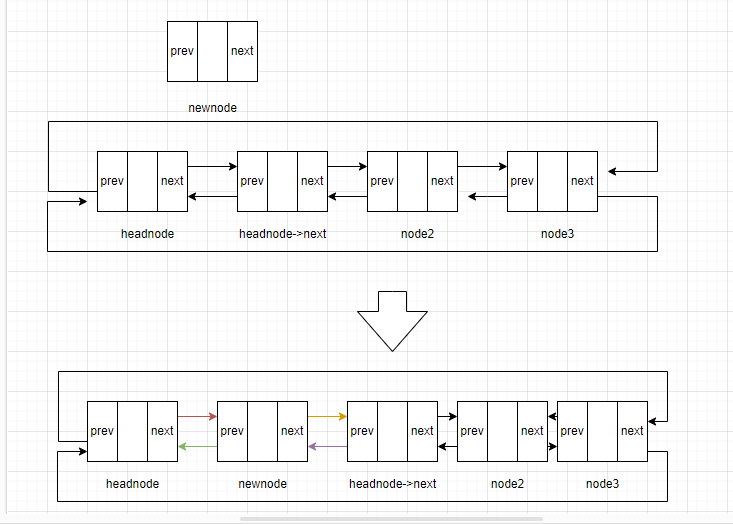
代码如下:`
void ListDataPushFront(Node* headnode, LTData n)
{assert(headnode);Node* newnode = CreateNewNode(n);newnode->next = headnode->next;newnode->prev = headnode;headnode->next->prev = newnode;headnode->next = newnode;
}
查找指定数据项的节点
将整个链表遍历一遍寻找数据项,如果某节点的数据项符合查找的要求,就返回该节点位置。
函数原型如下:
Node* FindListNode(Node* headnode, LTData n)
(1)headnode是待查找的双向链表的头结点
(2)n是指定的数据项
遍历的方式如下:
(1)从头结点的下一个节点开始
(2)依次遍历所有节点,对比数据项
(3)回到头结点后结束遍历
Node* FindListNode(Node* headnode, LTData n)
{assert(headnode);//头结点不为空assert(headnode->next != headnode);//待查找的链表不为空链表Node* pcur = headnode->next;while (pcur != headnode)//循环结束条件为指针回到头结点{if (pcur->data == n)//匹配数据项return pcur;//完成匹配pcur = pcur->next;}return NULL;//未完成匹配
}
在指定位置之后插入节点
前面讲解了如何在查找指定的位置,这里就利用前面查找位置的函数来讲解如何在指定位置之后插入位置。
首先通过前面写的查找数据项的函数确定插入位置。
插入的方法如下:
(1)将新节点的前驱节点设为位置节点
(2)将新节点的后继节点设为位置节点的后一个节点
(3)令位置节点的后一个节点的前驱设为新节点
(4)令位置节点的后继节点设为新节点
注意步骤3和步骤4的位置不能变换
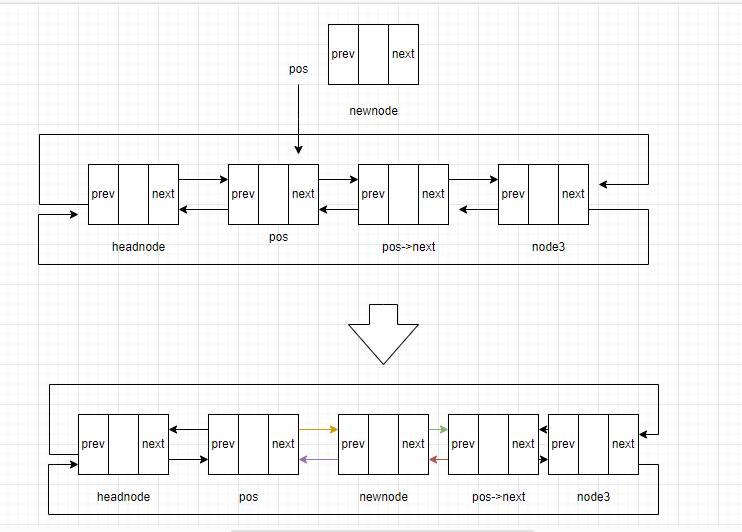
函数原型如下:
void ListNodeInsert(Node* headnode, LTData n, Node* pos);
(1)headnode——待插入链表的头结点
(2)n——节点的数据项
(3)pos——插入的节点位置
函数实现如下:
void ListNodeInsert(Node* headnode, LTData n, Node* pos)
{assert(pos);assert(headnode);Node*newnode=CreateNewNode(n);newnode->next = pos->next;newnode->prev = pos;pos->next->prev = newnode;pos->next = newnode;
}
指定位置的删除
删除指定位置的方法如下:
(1)将待删除的节点的后继节点的前驱设为待删除节点的前驱节点
(2)将待删除的节点的前驱节点的后继设为待删除节点的后继节点
(3)释放待删除节点
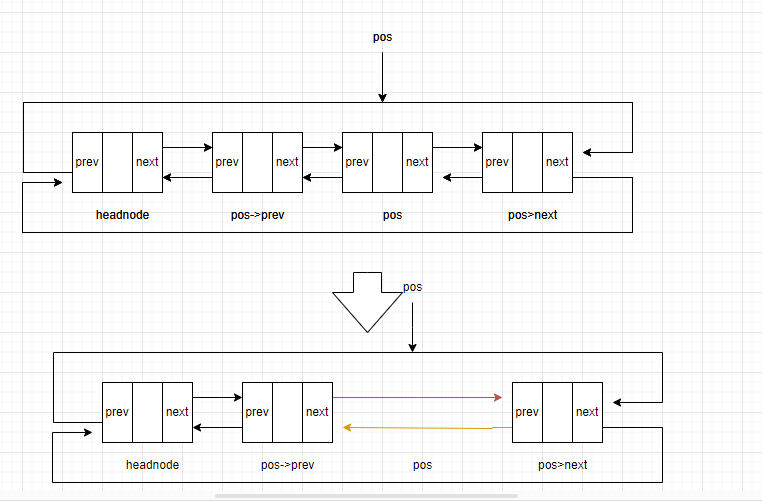
函数的原型如下:
void ListNodeDelete(Node* headnode, Node* pos);
(1)headnode是待删除节点的链表的头结点
(2)pos是待删除节点的位置
函数的实现如下:
void ListNodeDelete(Node* headnode, Node* pos)
{assert(headnode);assert(pos);assert(pos != headnode);//禁止删除头结点pos->next->prev = pos->prev;pos->prev->next = pos->next;free(pos);pos = NULL;
}
双向链表的销毁
将双向链表销毁的方法如下:
从头结点开始往后遍历(也可以往前遍历),将每个遍历的节点进行销毁,最后回到头结点时结束遍历,别忘了头结点也要进行销毁。
函数的代码如下:
void ListDestory(Node* headnode)
{Node* pcur = headnode->next;Node* ptmp = pcur;while (pcur != headnode){ptmp = pcur;pcur = pcur->next;free(ptmp);}free(headnode);
}
顺序表与链表的对比
既然顺序表与链表都是线性表,那么这两种线性表的优劣是什么呢
| 顺序表 | 线性表 | |
|---|---|---|
| 物理结构 | 顺序存储 | 非线性存储 |
| 访问元素 | 时间复杂度O(1) | 时间复杂度O(n) |
| 插入/删除元素 | O(N) | O(1) |
| 空间利用 | 需要扩容(利用程度低) | 不需要扩容(利用程度高) |
| 优势 | 查找元素和访问速度快 | 频繁插入删除的速度快 |
这篇关于C语言数据结构(4)——线性表其三(双向链表)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






