本文主要是介绍基于Redis的高可用分布式锁——RedLock,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
RedLock简介
RedLock工作流程
获取锁
释放锁
RedLock简介
- Redis作者提出来的高可用分布式锁
- 由多个完全独立的Redis节点组成,注意是完全独立,而不是主从关系或者集群关系,并且一般是要求分开机器部署的
- 利用分布式高可以系统中大多数存活即可用的原则来保证锁的高可用
- 针对每个单独的节点,获取锁和释放锁的操作,完全采用我们上面描述的单机版的方式
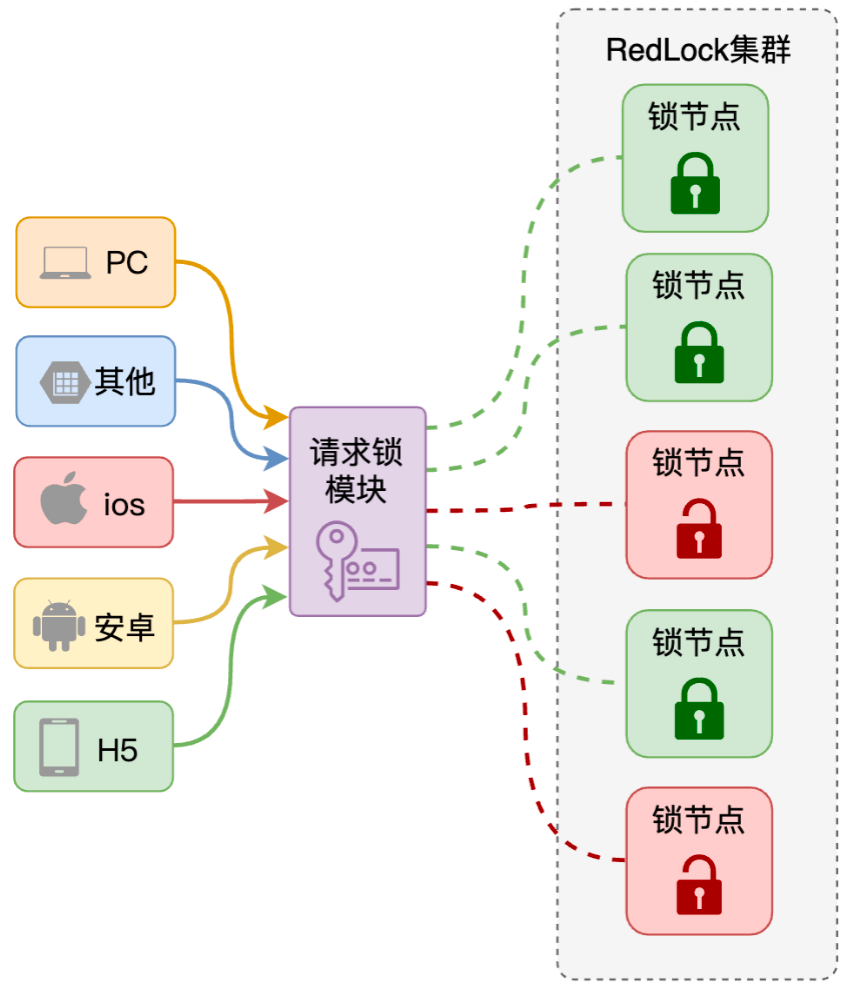
RedLock工作流程
获取锁
- 获取当前时间T1,作为后续的计时依据;
- 按顺序地,依次向5个独立的节点来尝试获取锁
- (SET resource_name my_random_value NX PX 30000)
- 计算获取锁总共花了多少时间,判断获取锁成功与否
-
时间:T2-T1
-
多数节点的锁(N/2+1)
-
当获取锁成功后的有效时间,要从初始的时间减去第三步算出来的消耗时间
-
如果没能获取锁成功,尽快释放掉锁。
这里需要注意两点:
-
为什么要顺序地向节点发起命令,那么我们反过来想,假如不顺序地发起命令会产生什么问题?
假如有3个客户端同时来抢锁,客户端A先获取到1号和2号节点,客户端B先获取到3号4号节点,客户端C先获取到5号节点,那么这时候就满足不了多数原则,5个节点的情况下,最少需要3个节点都获取到锁,才可以满足。 -
客户端在向每个节点尝试获取锁的时候,有一个超时时间限制,而且这个时间远小于锁的有效期,比如说几毫秒到几十毫秒之间,这样的机制是为了防止在向某一个节点获取锁的时候,等待的时间过长,从而导致获取锁的整体时间过长。比如说在获取锁的时候,有的节点会出现问题导致连接不上,那么这个时候就应该尽快地转移到下一个节点继续尝试,因为最终的结果我们只需要满足多数可用原则即可
释放锁
向所有节点发起释放锁的操作,不管这些节点有没有成功设置过.
正常情况下RedLock的运行状态
client1和client2,对Redis节点A-E进行抢锁操作,如图,client1先抢到节点ABC,超过半数,因此持有分布式锁,在持有锁期间,client2抢锁都是失败的,当时序=6时,client1才处理完业务流程释放分布式锁,这时候client2才有可能抢锁成功。

那么RedLock的主要流程就是这样,获取锁和释放锁,那么这个号称是真正的分布式锁,相比前面单机版的锁,很明显的一个点就是它不再是单点的,所以在高可用性上面,它是比单机版的锁有提升的。
但是,RedLock 是否就是一个很完美的解决方案呢?在一些特殊场景下会不会存在什么不足的地方?
此外,除了redis以外 ,其实我们可以用ZooKeeper来实现分布式锁。
实际上Redis实现分布式锁的方式虽然性能比较高,但是在一些特殊场景下,它还是不够健壮,相比之下,ZooKeeper它的设计定位就是用来做分布式协调的工作,更加注重一致性,非常适合用来做分布式锁,总的来说使用ZooKeeper去实现分布式锁相比Redis的话会更加健壮一些。
这篇关于基于Redis的高可用分布式锁——RedLock的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




