本文主要是介绍南京观海微电子----DDR的工作原理——DDR接口专栏(一),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

DDR的发展历程
SDRAM从发展到现在已经经历了四代,分别是:第一代SDR SDRAM,第二代DDR SDRAM,第三代DDR2 SDRAM,第四代DDR3 SDRAM,现在已经发展到DDR5 SDRAM。
-
DDR SDRAM是Double Data Rate Synchronous Dynamic Random Access Memory(双数据率同步动态随机存储器)的简称,为第二代SDRAM标准。其常见标准有DDR 266、DDR 333和DDR 400。其对于SDRAM,主要它允许在时钟脉冲的上升沿和下降沿传输数据,这样不需要提高时钟的频率就能实现双倍的SDRAM速度,例如DDR266内存与PC133 SDRAM内存相比,工作频率同样是133MHz,但在内存带宽上前者比后者高一倍。这种做法相当于把单车道更换为双车道,内存的数据传输性能自然可以翻倍。
-
DDR2(Double Data Rate 2)SDRAM是由JEDEC(电子设备工程联合委员会)开发的第三代SDRAM内存技术标准,1.8v工作电压,240线接口,提供了相较于DDR SDRAM更高的运行效能与更低的电压,同样采用在时钟的上升/下降延同时进行数据传输的基本方式,但拥有两倍于上一代DDR内存预读取能力(即4bit数据读预取能力),其常见的频率规范有DDR2 400\533\667\800\1066\1333等,总线频率553MHz的DDR2内存只需133MHz的工作频率
-
DDR3 SDRAM相比起DDR2具备更低的工作电压(1.5v),240线接口,支持8bit预读,只需133MHz的工作频率便可实现1066MHz的总线频率。其频率从800MHz起跳,常见频率有DDR3 800\1066\1333\1600\1866\2133等。DDR3是当前流行的内存标准,Intel酷睿i系列(如LGA1156处理器平台)、AMD AM3主板及处理器的平台都是其“支持者”。
-
DDR4相比DDR3最大的区别有三点:16bit预取机制(DDR3为8bit),同样内核频率下理论速度是DDR3的两倍;更可靠的传输规范,数据可靠性进一步提升;工作电压降为1.2V,更节能。
DDR到DDR5的主要变化,我们可以看到,为了配合整体行业对于性能,容量和省电的不断追求,规范的工作电压越来越低,芯片容量越来越大,IO的速率也越来越高。
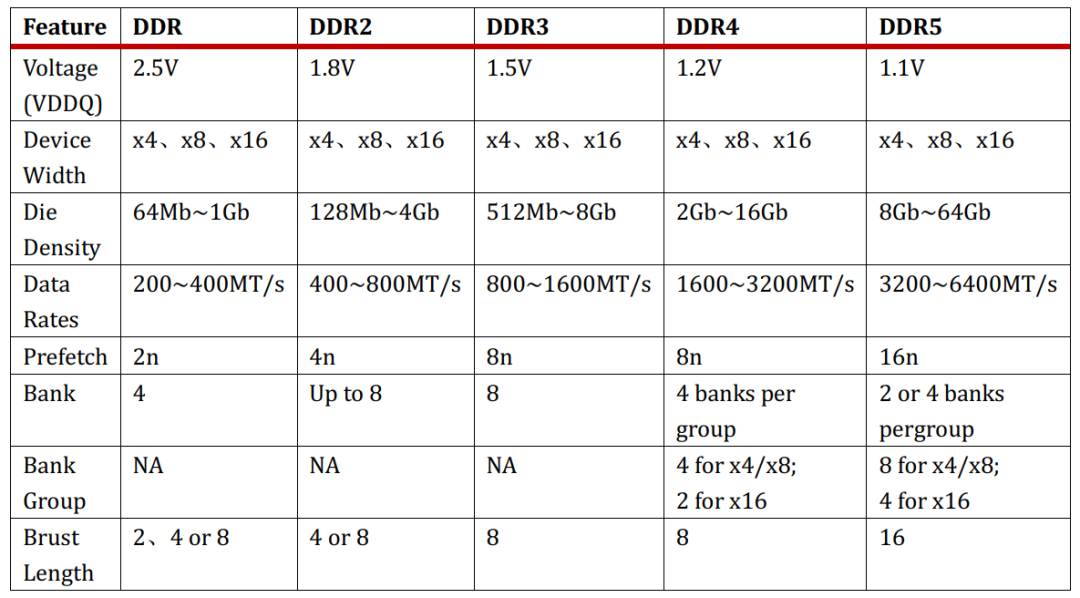
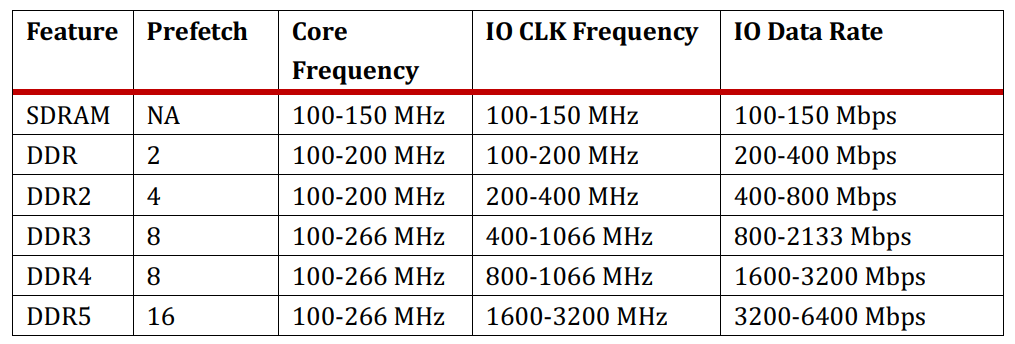
除了电压,容量和IO的速率变化之外,上表还列出了Bank,Bank Group,Prefetch和Burst Length的演进,bank数越来越多,到DDR4出现bank group,prefetch也从2n增加到4n,8n。虽然我们说现在DDR4的最大速率是3200MT/s, 但是这是指的DDR4的IO频率,即DDR4和memroy controller之间的接口数据传输速率。那么DRAM是怎么实现用比较低的核心传输频率来满足日益高涨的高速IO传输速率的需求呢?这就是靠prefetch来实现的。
-
从DDR开始到DDR3很好理解,Prefetch相当于DRAM core同时修了多条高速公路连到外面的IO口,来解决IO速率比内部核心速率快的问题,IO数据速率跟核心频率的倍数关系就是prefetch。
-
burst length的长度跟CPU的cache line大小有关。Burst length的长度有可能大于或者等于prefetch。但是如果prefetch的长度大于burst length的长度,就有可能造成数据浪费,因为CPU一次用不了那么多。所以从DDR3到DDR4,如果在保持DDR4内存data lane还是64的前提下,继续采用增加prefetch的方式来提高IO速率的话,一次prefetch取到的数据就会大于一个cache line的大小 (512bits),对于目前的CPU系统,反而会带来性能问题。
-
DDR4出现了Bank Group,这就是DDR4在不改变prefetch的情况下,能继续提升IO速率的秘密武器。DDR4利用Bank group的interleave,实现IO速率在DDR3基础上进一步提升。
3. 内存原理
从外观上就可以看出来小张的内存条由很多内存颗粒组成。

从内存控制器到内存颗粒内部逻辑,笼统上讲从大到小为:channel>DIMM>rank>chip>bank>row/column,如下图:
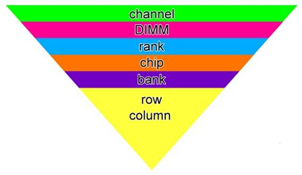
一个现实的例子是:
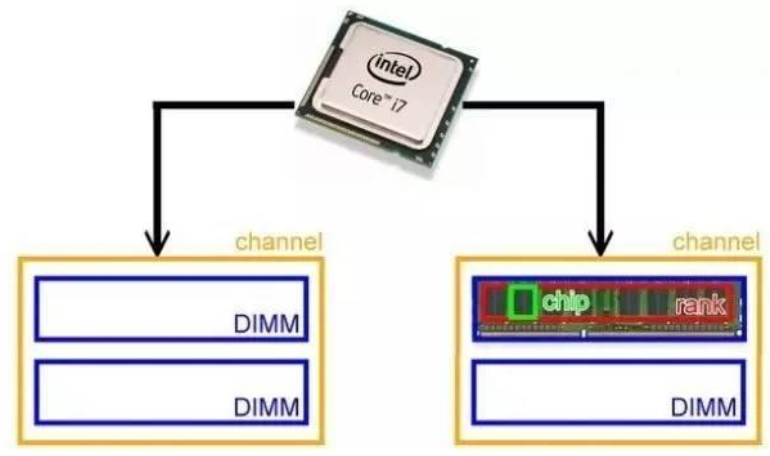
在这个例子中,一个i7 CPU支持两个Channel(双通道),每个Channel上可以插俩个DIMM,而每个DIMM由两个rank构成,8个chip组成一个rank。由于现在多数内存颗粒的位宽是8bit,而CPU带宽是64bit,所以经常是8个颗粒可以组成一个rank。所以小张的内存条2R X 8的意思是由2个rank组成,每个rank八个内存颗粒。由于整个内存是4GB,我们可以算出单个内存颗粒是256MB。
这次我们来看看rank和Chip里面有什么,如下图:
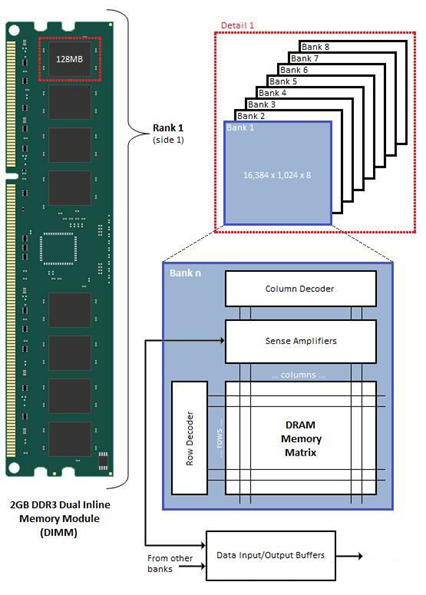
这是个DDR3一个Rank的示意图。我们把左边128MB Chip拆开来看,它是由8个Bank组成,每个Bank核心是个一个存储矩阵,就像一个大方格子阵。这个格子阵有很多列(Column)和很多行(Row),这样我们想存取某个格子,只需要告知是哪一行哪一列就行了,这也是为什么内存可以随机存取而硬盘等则是按块存取的原因。
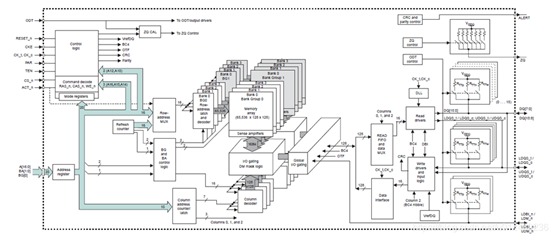
实际上每个格子的存储宽度是内存颗粒(Chip)的位宽,在这里由8个Chip组成一个Rank,而CPU寻址宽度是64bit,所以64/8=8bit,即每个格子是1个字节。选择每个格子也不是简单的两组信号,是由一系列信号组成,以这个2GB DDR3为例:
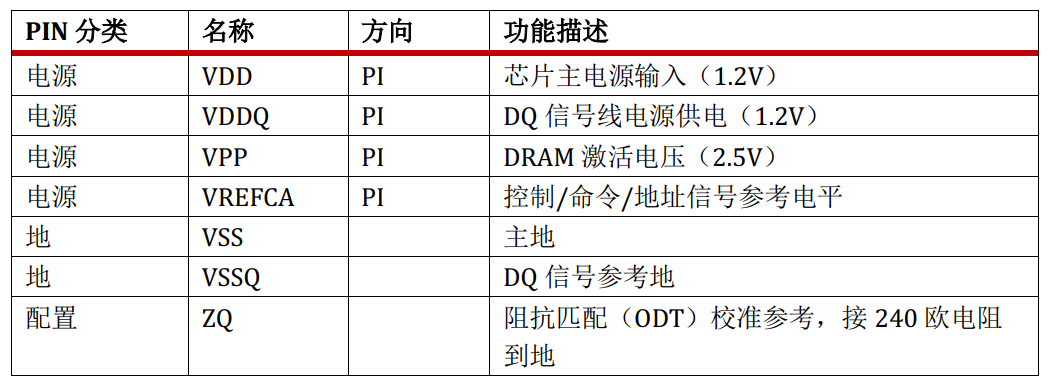
其引脚按照功能可以分为7类:前3类为电源、地、配置
后4类为:控制信号、时钟信号、地址信号、数据信号
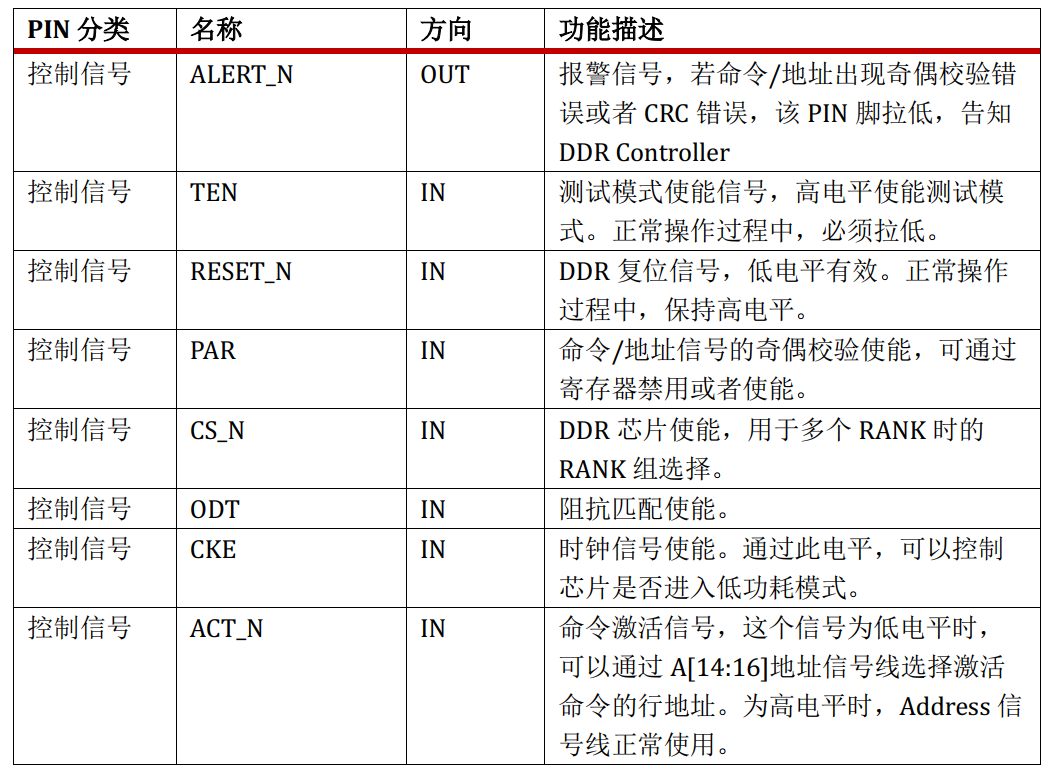
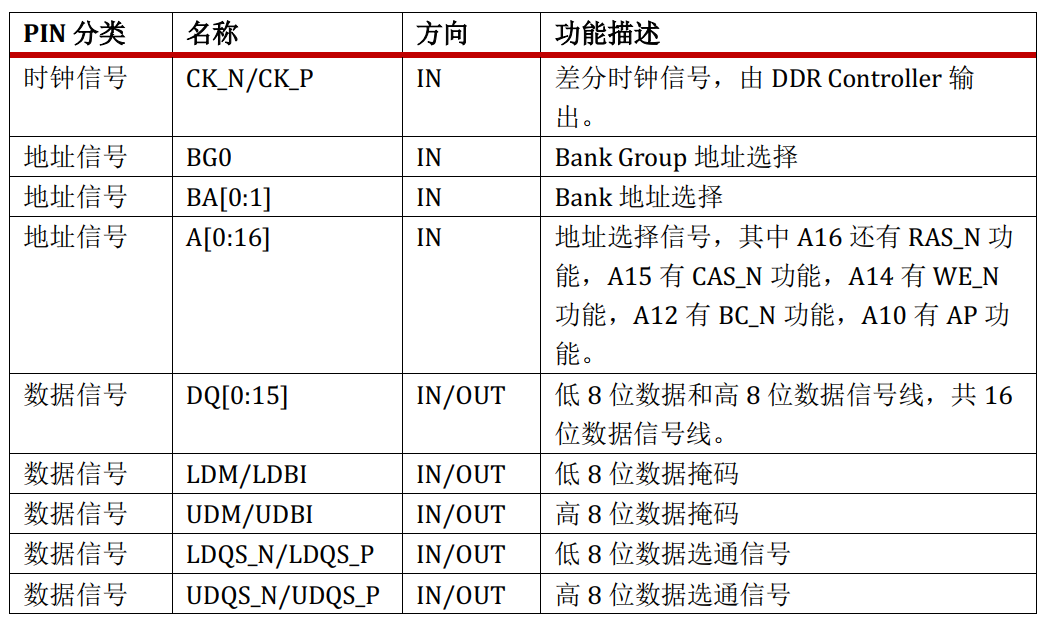
电源、地、配置信号的功能很简单,在此不赘述。DDR4中最重要的信号就是地址信号和数据信号。
如上DDR4芯片有20根地址线(17根Address、2根BA、1根BG),16根数据线。在搞清楚这些信号线的作用以及地址信号为何还有复用功能之前,我们先抛出1个问题。假如我们用20根地址线,16根数据线,设计一款DDR,我们能设计出的DDR寻址容量有多大?
Size(max)=(2^20) * 16 = 2048 KB =2 MB。但是事实上,该DDR最大容量可以做到1GB,比传统的单线编码寻址容量大了整整512倍,它是如何做到的呢?答案很简单,分时复用。我们把DDR存储空间可以设计成如下样式:
首先将存储空间分成两个大块,分别为BANK GROUP0和BANK GROUP1,再用1根地址线(还剩19根),命名为BG,进行编码。若BG拉高选择BANK GROUP0,拉低选择BANK GROUP1。(当然你也可以划分成4个大块,用2根线进行编码)。
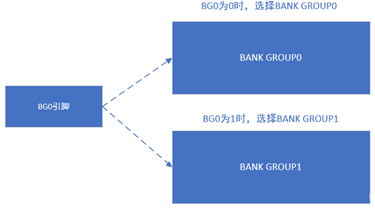
再将1个BANK GROUP区域分成4个BANK小区域,分别命名为BANK0、BANK1、BANK2、BANK3。然后我们挑出2根地址线(还剩余17根)命名为BA0和BA1,为4个小BANK进行地址编码。
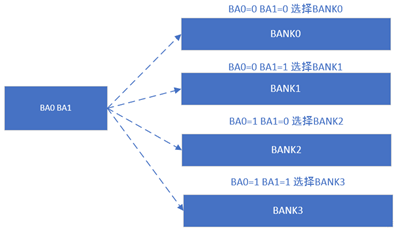
此时,我们将DDR内存颗粒划分成了2个BANK GROUP,每个BANK GROUP又分成了4个BANK,共8个BANK区域,分配了3根地址线,分别命名为BG0,BA0,BA1。然后我们还剩余17根信号线,每个BANK又该怎么设计呢?这时候,就要用到分时复用的设计理念了。
剩下的17根线,第一次用来表示行地址,第二次用来表示列地址。即传输2次地址,再传输1次数据,寻址范围最多被扩展为2GB。虽然数据传输速度降低了一半,但是存储空间被扩展了很多倍。这就是改善空间。所以,剩下的17根地址线,留1根用来表示传输地址是否为行地址。过程如下:
-
在第1次传输时,行地址选择使能,剩下16根地址线,可以表示行地址范围,可以轻松算出行地址范围为2^16=65536个=64K个。
-
在第2次传输时,行地址选择禁用,剩下16根地址线,留10根列地址线表示列地址范围,可以轻松表示的列地址范围为2^10=1024个=1K个,剩下6根用来表示读写状态/刷新状态/行使能、等等复用功能。
-
这样,我们可以把1个BANK划分成64K*1K个=64M个地址编号。
-
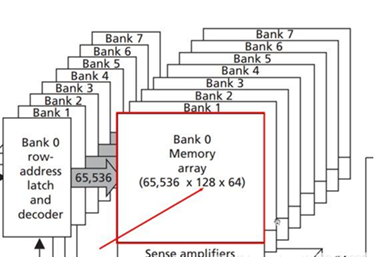
所以1个BANK可以分成64K行,每行1K列,每个存储单元16bit。
最后理一下:
每行可以存储1K *16bit=2KB。每行的存储的容量称为Page Size。
单个BANK共64K行,所以每个BANK存储容量为64K *2KB=128MB。
单个BANK GROUP共4个BANK,每个BANK GROUP存储容量为512MB。
单个DDR4芯片有2个BANK GROUP,故单个DDR4芯片的存储容量为1024MB=1GB。
至此,20根地址线和16根数据线全部分配完成,我们用正向设计的思维方式,为大家讲解了DDR4的存储原理以及接口定义和寻址方式。
但是细心的同学发现一个问题,对于每一个bank,按照正常的10位数据,那么col应该是1024,而现在是128,是什么原因呢?
那么问题又来了,为什么Column Address的寻址能力只有128呢?请继续看下图
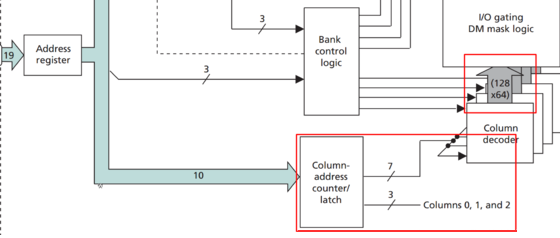
在上图中,可以清晰地发现,10bits的Column Address只有7bits用于列地址译码,列地址0,1,2并没有用!列地址0,1,2,这3bits被用于什么功能了?或者是DDR的设计者脑残,故意浪费了这三个bits?在JESD79-3规范中有如下的这个表格:
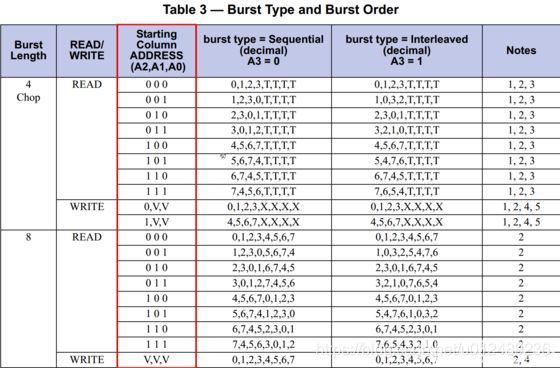
可以发现,Column Address的A2,A1,A0三位被用于Burst Order功能,并且A3也被用于Burst Type功能。由于一般情况,我们采用的都是顺序读写模式(即{A2,A1,A0}={0,0,0}),所以此时的A3的取值并无直接影响,CA[2:0]的值决定了一次Burst sequence的读写地址顺序。
比如一次Burst Read的时候如果CA[2:0]=3’b001表示低三位从地址1开始读取,CA3=0的时候按顺序读取1,2,3,0,5,6,7,4,CA3=1的时候交错读取1,0,3,2,5,4,7,6。
对于Prefetch而言,正好是8N Prefetch,对于Burst而言对应BL8。BC4其实也是一次BL8的操作,只是丢弃了后一半的数据。
更形象地理解就是对于一个Bank里面的Memory Array,每个Memory Cell可以看作是一个Byte的集合体。CA[9:3]选中一行中的一个特定Byte,再由CA[2:0]选择从这个Byte的哪个位置开始操作。CA3既参与了列地址译码,也决定Burst是连续读取还是交错读取。Prefetch也决定了I/O Frequency和SDRAM Core Frequency之间的关系。
这篇关于南京观海微电子----DDR的工作原理——DDR接口专栏(一)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





