本文主要是介绍【论文阅读】Vlogger: Make Your Dream A Vlog,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Vlogger:把你的梦想变成Vlog
paper:https://arxiv.org/abs/2401.09414
code:https://github.com/zhuangshaobin/vlogger
看起来挺有意思的,有空读一下
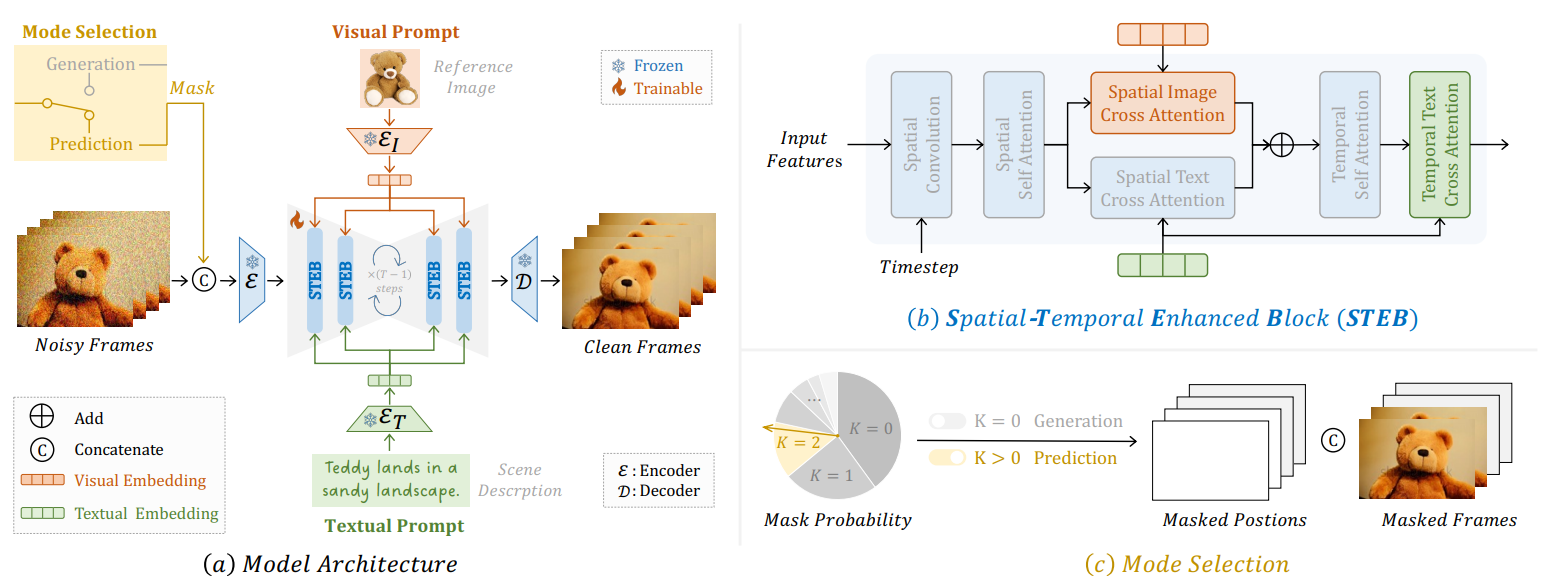
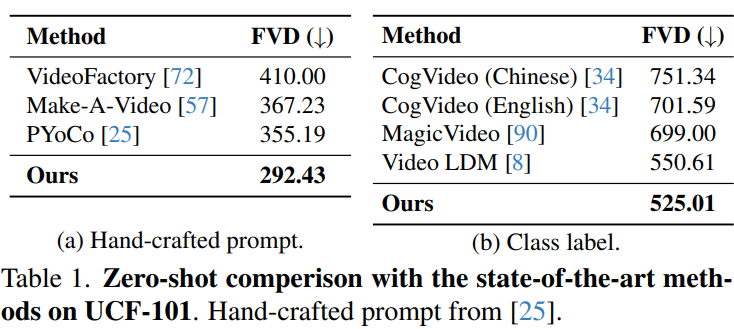
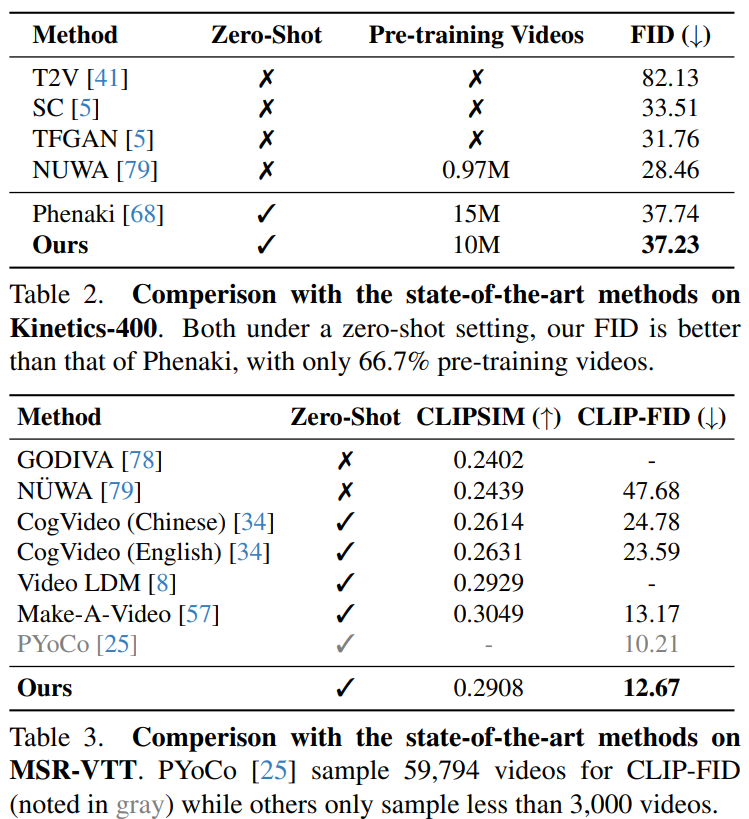
本文提出Vlogger,一种用于生成用户描述的分钟级视频博客(即vlog)的通用人工智能系统。与几秒钟的短视频不同,vlog通常包含复杂的故事情节和多样化的场景,这对大多数现有的视频生成方法来说是一个挑战。为突破这一瓶颈,该Vlogger巧妙地利用大型语言模型(LLM)作为导演,并将vlog的长视频生成任务分解为四个关键阶段,调用各种基础模型来发挥vlog专业人员的关键作用,包括(1)脚本,(2)演员,(3)ShowMaker和(4)Voicer。通过这种模仿人类的设计,我们的Vlogger可以通过自上而下的规划和自下而上的拍摄的可解释的合作来生成vlog。提出了一种新的视频扩散模型ShowMaker,在视频博主中充当摄像师,生成每个拍摄场景的视频片段。通过融合脚本和演员注意力作为文本和视觉提示,可以有效增强片段的时空连贯性。为ShowMaker设计了一种简洁的混合训练范式,提高了其生成T2V和预测的能力。广泛的实验表明,所提出方法在零样本T2V生成和预测任务上取得了最先进的性能。更重要的是,Vlogger可以从开放世界的描述中生成超过5分钟的vlog,而不会损失脚本和演员的视频连贯性。
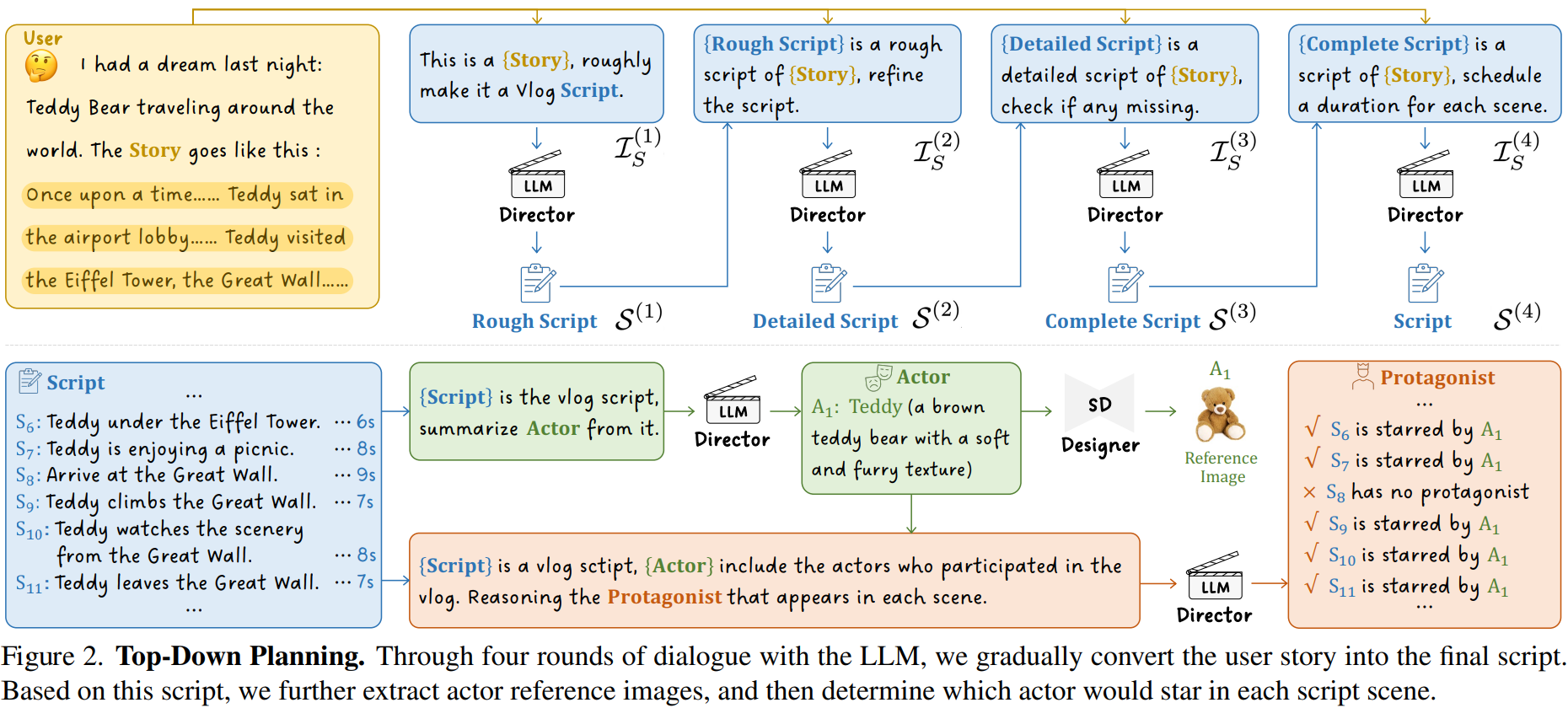
 图1所示。Vlogger概述。基于用户故事,所提出的Vlogger利用大型语言模型(LLM)作为指导,将一分钟长的vlog生成任务分解为四个关键阶段,有剧本,演员,制作人和配音。此外,ShowMaker是一种新的视频扩散模型,用于生成视频片段。每个拍摄场景,与剧本和演员一致。
图1所示。Vlogger概述。基于用户故事,所提出的Vlogger利用大型语言模型(LLM)作为指导,将一分钟长的vlog生成任务分解为四个关键阶段,有剧本,演员,制作人和配音。此外,ShowMaker是一种新的视频扩散模型,用于生成视频片段。每个拍摄场景,与剧本和演员一致。



这篇关于【论文阅读】Vlogger: Make Your Dream A Vlog的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)