本文主要是介绍GEE数据集——MOD13A1.006Terra星搭载的中分辨率成像光谱仪获取的L3级植被指数产品,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
数据名称:
MOD13A1.006
Modis
16天
Terra
500m
数据来源:
NASA
时空范围:
2000-2022年
空间范围:
全国
波段
| 名称 | 波段 | 单位 | 最小值 | 最大值 | 比例因子 | 波长 | 描述 |
|---|---|---|---|---|---|---|---|
| NDVI | B1 | NDVI | -2000 | 10000 | 0.0001 | Normalized Difference Vegetation Index | |
| EVI | B2 | EVI | -2000 | 10000 | 0.0001 | Enhanced Vegetation Index | |
| VIQ | B3 | Bit Field | VI quality indicators | ||||
| RR | B4 | 0 | 10000 | 0.0001 | 645nm | Red surface reflectance | |
| NIRR | B5 | 0 | 10000 | 0.0001 | 858nm | NIR surface reflectance | |
| BR | B6 | 0 | 10000 | 0.0001 | 469nm | Blue surface reflectance | |
| MIRR | B7 | 0 | 10000 | 0.0001 | 2130nm/2105-2155nm | MIR surface reflectance | |
| VZA | B8 | Degree | 0 | 18000 | 0.01 | View zenith angle | |
| SZA | B9 | 0 | 18000 | 0.01 | Solar zenith angle | ||
| RAA | B10 | -18000 | 18000 | 0.01 | Relative azimuth angle | ||
| CDOY | B11 | Julian day | 1 | 366 | Julian day of year | ||
| PR | B12 | Rank | Quality reliability of VI pixel |
数据简介:
MOD13A1 V6数据集是由Terra星搭载的中分辨率成像光谱仪获取的L3级植被指数产品,空间分辨率为500米,具备两个主要的植被层,分别是栅格归一化植被指数(NDVI)和增强型植被指数(EVI)。产品遵循低云、低视角和最高NDVI/EVI值的原则,从获取的16天数据中选择最佳值作为影像的像素值。可用于检测植被状态和土地覆盖利用变化,并且,能够进一步用于生物化学、水循环过程和全球及区域性的气候研究,还有LAI、GPP等参数的反演。前言 – 人工智能教程
V6Terra星搭载的中分辨率成像光谱仪(MOD13A1)是一种用于获取地球植被指数的传感器。该传感器通过对地球表面的光谱信息进行观测和记录,能够提供高质量的L3级植被指数产品,为地球科学研究和生态环境监测提供了重要的数据支持。
L3级植被指数产品是通过对MODIS传感器获取的遥感数据进行处理和分析得到的。MOD13A1产品主要包括三个指标:归一化差异植被指数(NDVI)、归一化差异水体指数(NDWI)和归一化差异建筑物指数(NDWI)。
其中,归一化差异植被指数(NDVI)是衡量地表植被覆盖程度和活力的重要指标。NDVI的计算公式为(NIR - RED)/ (NIR + RED),其中NIR表示近红外波段的反射率,RED表示红光波段的反射率。NDVI的数值范围在-1到1之间,数值越高表示地表植被覆盖越多,数值越低表示植被覆盖越少。通过监测NDVI的变化,可以提供有关植被开花、叶片生长和植物胁迫状况的信息。
归一化差异水体指数(NDWI)是用于评估地表水体分布的指标。NDWI的计算公式为(NIR - SWIR)/ (NIR + SWIR),其中NIR表示近红外波段的反射率,SWIR表示短波红外波段的反射率。NDWI的数值范围从-1到1,数值越高表示地表水体分布越密集,数值越低表示水体分布越稀疏。通过监测NDWI的变化,可以提供有关水体资源分布和蓄水情况的信息。
归一化差异建筑物指数(NDBI)是用于评估建筑物分布密度的指标。NDBI的计算公式为(SWIR - NIR)/ (SWIR + NIR),其中SWIR表示短波红外波段的反射率,NIR表示近红外波段的反射率。NDBI的数值范围从-1到1,数值越高表示建筑物分布越密集,数值越低表示建筑物分布越稀疏。通过监测NDBI的变化,可以提供有关城市建设和土地利用的信息。
V6Terra星搭载的中分辨率成像光谱仪获取的L3级植被指数产品具有以下特点:
-
高时空分辨率:MOD13A1产品提供的植被指数数据具有250米的空间分辨率和16天的时间分辨率,可以提供详细的植被覆盖和水体分布的信息,适用于不同尺度的研究和监测需求。
-
高质量数据:V6Terra星搭载的中分辨率成像光谱仪通过高精度的光谱观测和数据处理算法,可以提供高质量的植被指数产品。这些产品经过严格的校正和验证,能够准确反映地表植被、水体和建筑物的分布情况。
-
多指标综合分析:MOD13A1产品包括了归一化差异植被指数(NDVI)、归一化差异水体指数(NDWI)和归一化差异建筑物指数(NDWI)三个指标,能够提供多层次、多维度的地表信息。这些指标可以综合分析,为地球科学研究和生态环境监测提供全面的数据支持。
总之,V6Terra星搭载的中分辨率成像光谱仪获取的L3级植被指数产品是一项重要的遥感技术应用。这些产品能够提供高质量、高时空分辨率的植被、水体和建筑物信息,为地球科学研究和生态环境监测提供了重要的数据支持。
引用代码:
MODIS/006/MOD13A1
代码
/*** @File : MOD13A1.006* @Time : 2023/06/06* @Author : GEOVIS Earth Brain* @Version : 0.1.0* @Contact : 中国(安徽)自由贸易试验区合肥市高新区望江西路900号中安创谷科技园一期A1楼36层* @License : (C)Copyright 中科星图数字地球合肥有限公司 版权所有* @Desc : 数据集key为MODIS/006/MOD13A1的MOD13A1.006类数据集 * @Name : MOD13A1.006数据集
*/
//指定检索数据集,可设置检索的空间和时间范围,以及属性过滤条件
var imageCollection = gve.ImageCollection("MODIS/006/MOD13A1").filterDate('2021-01-16','2021-01-31').select(['NDVI']).limit(10);print("imageCollection",imageCollection);var img = imageCollection.first();print("first", img);var visParams = {
// gamma: 1,
// brightness: 1,min: 0,max: 9000,palette: {"band_rendering": {"pseudocolor": {"colormap": ['#FCD163','#66A000','#3E8601','#004C00','#023B01']}}}
};Map.centerObject(img);
Map.addLayer(img,visParams);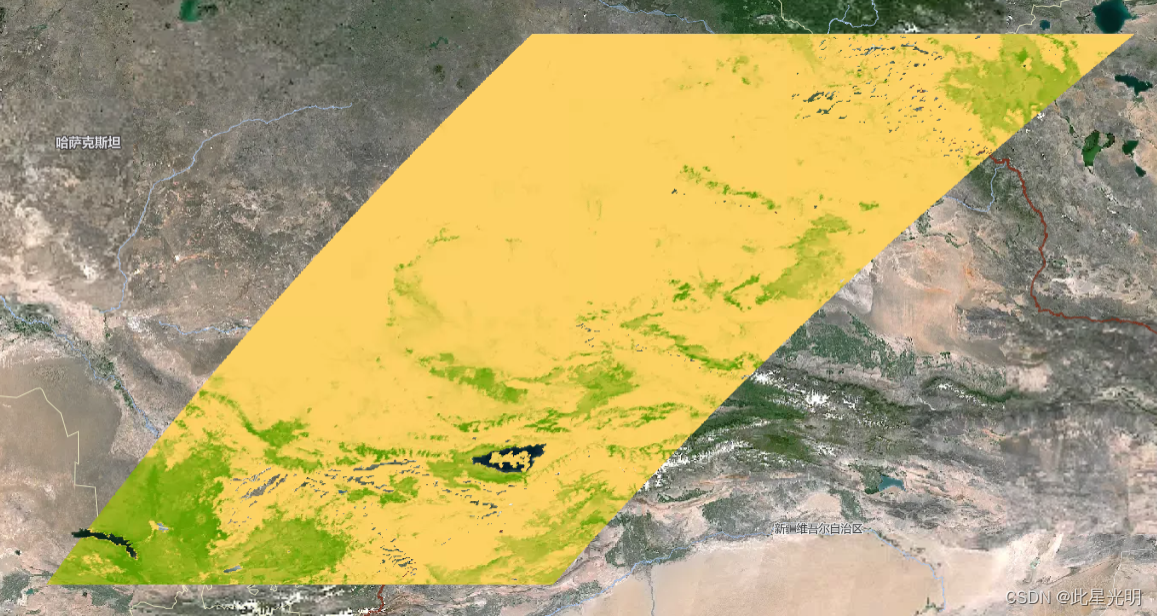
通过LP DAAC获得的MODIS数据和产品在后续使用,销售或再分发没有任何限制,具体请参阅https://lpdaac.usgs.gov/data/data-citation-and-policies/
这篇关于GEE数据集——MOD13A1.006Terra星搭载的中分辨率成像光谱仪获取的L3级植被指数产品的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




