本文主要是介绍企业著作权数据的价值:探索企业作品著作权API的应用,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
引言
随着知识经济的崛起,企业的知识产权和著作权保护变得愈发重要。企业拥有大量的著作权作品,包括文档、软件、设计、创意和更多。这些作品代表了企业的创新和核心价值。为了更好地保护和管理这些资产,企业可以探索企业作品著作权API的应用。本文将探讨企业著作权数据的价值以及如何利用API提高知识产权管理。
企业著作权数据的重要性
企业著作权数据包括了企业内部创作的各种作品,如文档、软件、图像、音频和视频等。这些作品反映了企业的独特性和竞争优势,是企业成功的重要组成部分。保护这些著作权不仅有助于维护企业的知识产权,还能够加强品牌形象,吸引投资者和客户。
企业作品著作权API的应用
1.知识产权管理
企业可以使用API来查询其作品的著作权状态,以确保这些作品的合法性和保护。这对于保护知识产权资产非常关键,尤其是在创意产业中。
2.版权管理
出版商、媒体公司和创意机构可以使用API来验证其出版物、电影、音乐等作品的版权状态。这有助于确保作品的合法使用和授权。
3.版权许可和授权
企业可以使用API来查询其他企业或创作者的作品著作权信息,以获取授权或许可,以便使用这些作品在商业活动中。
4.法律和咨询服务
律师事务所和知识产权顾问可以为客户提供定制的著作权查询服务,以支持法律诉讼或合规性审查。
如何使用企业作品著作权API
1.注册和获取API密钥
首先,企业需要注册并获得企业作品著作权API密钥,这通常需要在第三方接口平台申请接口使用。APISpace 的 企业作品著作权API,通过公司名称/公司ID/注册号或社会统一信用代码获取作品著作权的有关信息,包括作品名称、登记号、登记类别等字段的详细信息。
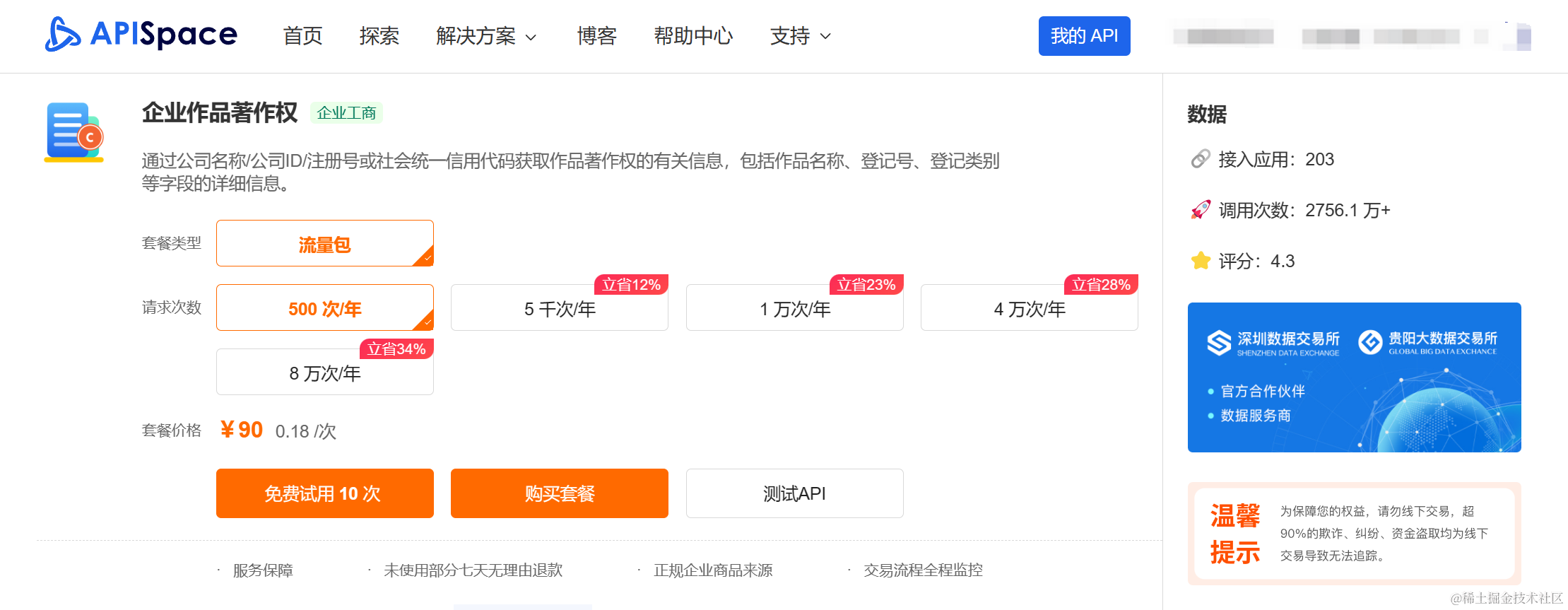
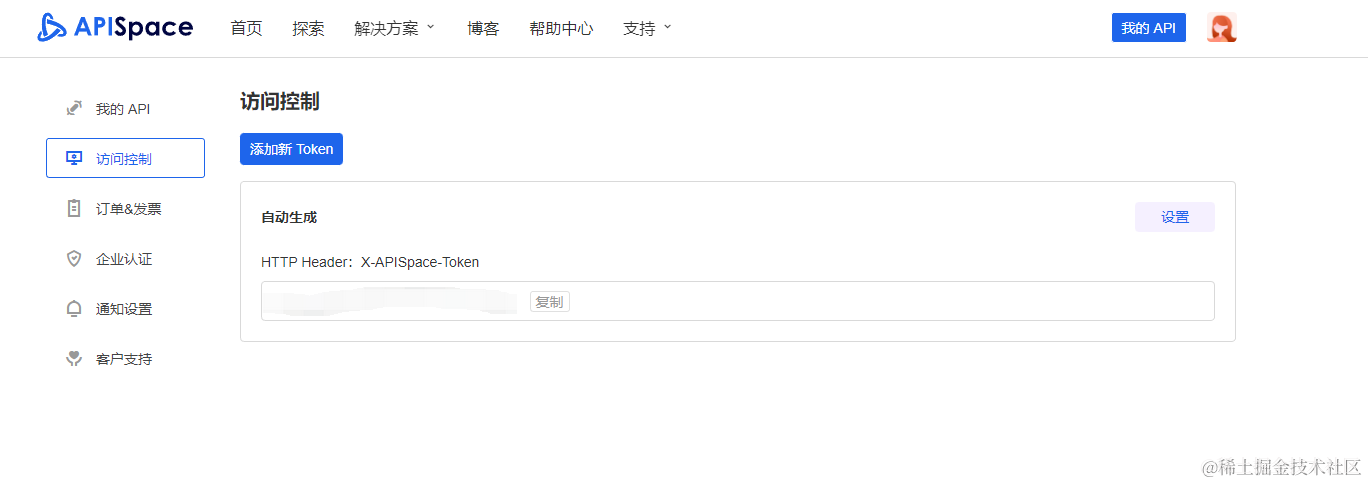
注册成功后,我们在页面导航菜单点击 【我的 API】进入 【访问控制】页面,即可看到平台提供的密钥。
2.集成API
将API密钥集成到企业的管理系统或工作流程中,以便可以随时查询著作权数据。APISpace 为了方便开发者们可以快速的将API集成到自己的代码当中,提供了各个语言的接入代码示例,如下:
OkHttpClient client = new OkHttpClient().newBuilder().build();
MediaType mediaType = MediaType.parse("application/x-www-form-urlencoded");
Request request = new Request.Builder().url("https://eolink.o.apispace.com/copyregworks/info?keyword=&pageNum=&pageSize=").method("GET",null).addHeader("X-APISpace-Token","替换成自己的API密钥").addHeader("Authorization-Type","apikey").build();Response response = client.newCall(request).execute();
System.out.println(response.body().string());
3. 查询信息
使用API进行查询,获取有关著作权数据的信息,包括版权状态、维权记录等。
4.制定策略
根据API提供的数据,企业可以制定更有针对性的知识产权保护策略,以降低风险并提高价值。
结论
企业著作权数据的价值不可低估,它代表了企业的核心资产。利用企业作品著作权API,企业可以更好地管理和保护这些数据,确保知识产权得到充分的保障。通过实时监测、维权、数据分析和管理集中,企业能够提高知识产权管理的效率,降低风险,推动创新,为未来的成功打下坚实的基础。因此,企业应积极探索并应用企业作品著作权API,以提高知识产权管理的水平。
这篇关于企业著作权数据的价值:探索企业作品著作权API的应用的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







