本文主要是介绍MySQL4 -----事务、索引、权限管理和备份、数据库规范三大范式、JDBC、数据库连接池,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
- 6. 事务
- 6.1 什么是事务?
- 7. 索引
- 7.1 索引的分类
- 7.2 测试索引
- 7.3. 索引原则
- 8 权限管理和备份
- 8.1 用户管理
- 8.2 SQL备份
- 9 规范数据库设计
- 9.1 为什么要有数据库设计
- 9.2 三大范式
- 10 JDBC
- 10.1 数据库驱动
- 10.2 JDBC
- 10.3 第一个JDBC程序
- 10.4 statement 对象
- 10.5 prepareStatement
- 10.6 事务
- 10.7 数据库连接池
6. 事务
6.1 什么是事务?
要么都成功,要么都失败
SQL语句1
.
.
.
SQL语句n
事务的特性:ACID原则,也伴随一些问题(脏读、幻读、)
- 原子性(Atomicity):要么全部执行成功,要么全部执行失败,不会只执行一部分。
- 一致性(Consistency):针对一个事务操作前后的状态保持一致。
- 持久性(Durability):事务结束后的数据不会因为外界原因导致丢失。 事务一旦提交就不可逆。
- 隔离性(Isolation):多个事务同时运行,彼此互不干扰。
隔离导致的问题
事务的隔离级别:
- 脏读:一个事务执行中读取到了另一个事务未提交的数据。
- 不可重复读:事务A在已使用一个数据一次后,这时事务B进行修改该数据,接着事务A再次读取该数据,导致问题,事务A前后读取到的数据不一致。
- 幻读:在查询方面前后搜索出来的结果不一致。
执行事务
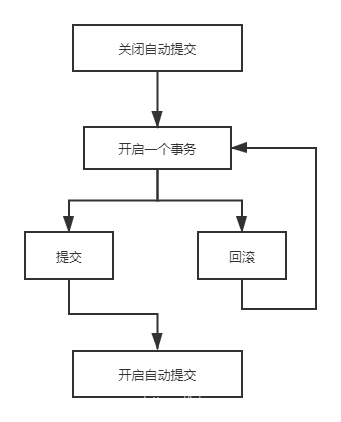
-- ========= 事务 ==========-- MySQL 默认提交事务SET autocommit = 0 -- 关闭自动提交SET autocommit = 1 -- 开启自动提交(默认开启)-- 手动处理事务SET autocommit = 0 -- 关闭自动提交 -- 开启事务START TRANSACTION -- 标记一个事务的开始-- 提交事务,进行持久化COMMIT-- 回滚事务,恢复原样ROLLBACK-- 事务结束SET autocommit = 1 -- 开启自动提交-- 以下为了解SAVEPOINT 保存点名 -- 在事务中可以设置一个保存点ROLLBACK TO SAVEPOINT 保存点名 -- 可以回滚到保存点名RELEASE SAVEPOINT 保存点名 -- 可以删除保存点
模拟场景
-- 模拟
CREATE DATABASE shop CHARACTER SET utf8 COLLATE utf8_general_ci
USE shopINSERT INTO `account`(`name`,`money`) VALUES('小明',2000.00),
('小森',10000.00)-- 模拟 一组转账事务SET autocommit = 0 ; -- 关闭自动提交START TRANSACTION -- 开启事务UPDATE `account` SET money = money - 500 WHERE `name` = 'a'UPDATE `account` SET money = money + 500 WHERE `name` = 'b'COMMIT; -- 提交事务ROLLBACK; -- 回滚事务SET autocommit = 1; -- 开启自动提交
7. 索引
MySQL官方对索引的解释:索引(Index)是帮助MySQL高效获取数据的数据结构。
得出结论:索引是一种数据结构,作用是帮助MySQL高效获取数据。
7.1 索引的分类
- 主键索引(PRIMARY KEY):
- 唯一标识,主键不可重复,只能有一个列作为主键。
- 唯一索引(UNIQUE KEY):
- 避免重复的列 ,一张表里可以有多个唯一索引
- 常规索引 (KEY/INDEX)
- 默认值是KEY,常规值是INDEX ,可以通过key和index关键字来设置
- 全文索引(FULLTEXT)
- 在特定的数据库引擎中才有, 如:MyISAM
- 快速定位数据
7.2 测试索引
-- 创建app用户表
CREATE TABLE `app_user` (
`id` BIGINT(20) UNSIGNED NOT NULL AUTO_INCREMENT,
`name` VARCHAR(50) DEFAULT '' COMMENT '用户昵称',
`email` VARCHAR(50) NOT NULL COMMENT '用户邮箱',
`phone` VARCHAR(20) DEFAULT '' COMMENT '手机号',
`gender` TINYINT(4) UNSIGNED DEFAULT '0' COMMENT '性别(男0,女1)',
`password` VARCHAR(100) NOT NULL DEFAULT '' COMMENT '密码',
`age` TINYINT(4) DEFAULT '0' NULL COMMENT '年龄',
`create_time` DATETIME DEFAULT CURRENT_TIMESTAMP,
`update_time` TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`id`)
)ENGINE=INNODB DEFAULT CHARSET=utf8mb4 COMMENT='app用户表'-- 插入100万数据.
DELIMITER $$ -- 写函数之前必须要写,标志
CREATE FUNCTION mock_data ()
RETURNS INT
BEGINDECLARE num INT DEFAULT 1000000;DECLARE i INT DEFAULT 0;
WHILE i<num DO-- 插入语句INSERT INTO `app_user`(`name`,`email`,`phone`,`gender`,`password`,`age`)VALUES(CONCAT('用户',i),'19224305@qq.com',CONCAT('18',FLOOR(RAND()*(999999999-100000000)+100000000)),FLOOR(RAND()*(2)),UUID(),FLOOR(RAND())*100);SET i=i+1;
END WHILE;
RETURN i;
END;SELECT mock_data() -- 执行此函数 生成一百万条数据-- 不建立索引时,执行时间
SELECT * FROM `app_user` WHERE `name`= '用户19999' -- 执行耗时 : 0.629 sec
EXPLAIN SELECT * FROM `app_user` WHERE `name`= '用户19999'-- 索引命名格式 : id_表名_字段名
-- create index 索引名 on 表(`字段`)
CREATE INDEX `id_appuser_name` ON `app_user`(`name`);-- 建立索引后,执行时间。
SELECT * FROM `app_user` WHERE `name`= '用户19999' -- 执行耗时 : 0.002 secEXPLAIN SELECT * FROM `app_user` WHERE `name`= '用户19999'
索引 在数据量小的时候 效果不明显,在数据量大的时候效果十分明显。
7.3. 索引原则
- 索引不是越多越好
- 不要对经常变动的数据加索引
- 小数据量的表不用加索引
- 索引一般加在常用来查询的字段上
索引的数据类型
InnoDB的默认数据结构是B+树
8 权限管理和备份
8.1 用户管理
SQL命令
存放用户信息的表 : mysql.user
-- 创建用户 CREATE USER 用户名 IDENTIFIED BY '密码'
CREATE USER swrici IDENTIFIED BY '123456'-- 修改当前用户密码
SET PASSWORD = PASSWORD('123456')-- 修改指定用户密码
SET PASSWORD FOR swrici = PASSWORD('111111')-- 重命名 RENAME USER 原名 TO 新名
RENAME USER swrici TO swrici2-- 用户授权 授予全部的权限 GRANT ALL PRIVILEGES
-- 不能给别人授权
GRANT ALL PRIVILEGES ON *.* TO swrici2-- 查看权限
SHOW GRANTS FOR swrici2 -- 查看指定用户的权限
SHOW GRANTS FOR root@localhost-- 撤销权限 revoke 哪些权限 on 哪个库 from 给谁撤销
REVOKE ALL PRIVILEGES ON *.* FROM swrici2-- 删除用户
DROP USER swrici2
8.2 SQL备份
为什么要备份?
- 保证重要的数据不丢失。
- 数据转移
MySQL数据库备份的方式:
- 直接拷贝物理文件
- 在SQL yog 这种可视化工具中 手动导出
- mysqldump 在命令行中使用 ,cmd
--导出 在命令行中
-- mysqldump -h主机 -u用户名 -p密码 库名 表名 >哪个盘:/文件名.sql
mysqldump -hlocalhost -uroot -p123456 school student >D:/a.sql-- mysqldump -h主机 -u用户名 -p密码 库名 表名1 表名2 表名3>哪个盘:/文件名.sql
mysqldump -hlocalhost -uroot -p123456 school student >D:/a.sql-- 导入 在sql中
--source 文件路径
source d:/a.sql
9 规范数据库设计
9.1 为什么要有数据库设计
当数据库比较复杂的时候,我们就需要设计
数据库设计对比:
- 糟糕的数据库设计:
- 数据冗余,浪费空间。
- 数据库插入和删除都很麻烦、异常(屏蔽使用物理外键)
- 程序的性能差
- 良好的数据库设计:
- 节省空间
- 保证了数据库的完整性
- 方便我们开发系统
软件开发中,关于数据库的设计
- 分析需求:分析业务和需要处理的数据库的需求
- 概要设计:设计关系图 E-R图
设计数据库的步骤:(个人博客为例)
- 收集信息,分析需求
- 用户表:(用户的登录注销,用户的个人信息,写博客,创建分类)
- 分类表:(文章分类,谁创建的)
- 文章表:(文章的信息)
- 友链表:(友链信息)
- 自定义表:(系统信息,某个关键的字,或者一些主字段)
- 标识实体 (把需求落实到每个字段)
- 标识实体之间的关系
- 用户写博客:user -> blog
- 用户创建分类:user -> category
- 用户关注用户:user -> user
- 友链:links
- 评论:user->user->blog
9.2 三大范式
为什么需要数据规范化?
- 避免信息重复
- 更新数据可能会导致一些异常
- 插入数据可能会导致一些异常
- 可能会有一些表能没有插入信息
- 删除数据可能会导致一些异常
- 存在一些表删不干净
三大范式
第一范式(1NF)
- 保证每一列不可再分,每一列只能由一个数据,不能一列出现两个数据的情况。
第二范式(2NF)
前提:满足第一范式
每张表只描述一件事。可能存在一个主键对应多类东西的表,但是这几种类之间并没有关系,所以要把这几类东西分别划分成几个表,让他们和主键一一对应。
第三范式(3NF)
前提:满足第二范式
在一个表中不能存在 不依赖该表主键 而去 依赖其他主键 的字段
规范 和性能 的问题
阿里规范,关联查询的表不能超过三张表
- 在考虑商业化的需求和目标,(成本,用户体验),数据库的性能更重要。
- 在规范性能问题的时候,需要适当考虑一下 规范性
- 有时也会故意增加一些冗余的字段,从多表查询变成了单表查询
- 也可能会故意增加一些计算列(从大数据量变成了小数据量的查询,索引)
10 JDBC
10.1 数据库驱动
应用程序要通过数据库驱动才能访问数据库
10.2 JDBC
SUN公司为了简化操作人员(对数据库的统一)操作,提供了一个(Java操作数据库的)规范,俗称JDBC
10.3 第一个JDBC程序
创建测试数据库
CREATE DATABASE jdbcStudy CHARACTER SET utf8 COLLATE utf8_general_ci;USE jdbcStudy;CREATE TABLE `users`(
id INT PRIMARY KEY,
NAME VARCHAR(40),
PASSWORD VARCHAR(40),
email VARCHAR(60),
birthday DATE
);INSERT INTO `users`(id,NAME,PASSWORD,email,birthday)
VALUES(1,'zhansan','123456','zs@sina.com','1980-12-04'),
(2,'lisi','123456','lisi@sina.com','1981-12-04'),
(3,'wangwu','123456','wangwu@sina.com','1979-12-04')
编写Java程序进行连接
public class JDBCTestDemo {public static void main(String[] args) throws ClassNotFoundException, SQLException {//1. 加载驱动Class.forName("com.mysql.jdbc.Driver"); //固定写法,加载驱动//2.链接信息,用户信息和urlString url = "jdbc:mysql://localhost:3306/jdbcstudy?useUnicode=true&characterEncoding=utf8&useSSL=true";String username = "root";String password = "123456";//3.链接成功,获得数据库对象Connection connection = DriverManager.getConnection(url, username, password);//4.执行SQL的对象Statement statement = connection.createStatement();//5. 使用该对象去执行SQLString sql = "select * from users";ResultSet rs = statement.executeQuery(sql);while (rs != null && rs.next()) {System.out.println(rs.getString(1) + ":" + rs.getString(2) + ":" + rs.getString(3));}//6. 释放链接rs.close();statement.close();connection.close();}
}
步骤:
- 加载驱动
- 连接数据库DriverManeger
- 获得连接 Connection
- 获得执行SQL的对象Statement
- 执行SQL获得结果集对象ResultSet
- 依次释放连接(rs,state,connect)
//等同于DriverManager.registerDriver(new com.mysql.jdbc.Driver())
class.forName(“com.mysql.jdbc.Driver”);//固定写法,加载驱动
url
String url = "jdbc:mysql://localhost:3306/jdbcstudy?useUnicode=true&characterEncoding=utf8&useSSL=true";//mysql 默认端口 3306
//jdbc:mysql://主机地址:端口号/数据库名?参数1&参数2//Oracle 默认端口: 1521
//jdbc:oracle:thin:@localhost:1521:sid
获得数据库对象
//connection 代表数据库,设置自动提交,进行提交,进行回滚
Connection connection = DriverManager.getConnection(url, username, password);
connection.commit();
connection.rollback();
connection.setAutoCommit();
Statement 执行SQL的类 prepareStatement
//sql具体要看什么操作
statement.executeQuery(sql);//执行查询操作
statement.execute(sql);//执行所有操作
statement.executeUpdate(sql);//执行更新,增加,删除操作
ResultSet rs结果集对象:分装了所有的查询结果
获得指定的数据类型:
//不知道类型的时候 rs是ResultSet的实例化对象rs.getObject();
//知道具体的类型的时候rs.getString();rs.getInt();rs.getFloat();rs.getArray();
遍历
rs.next()//移动到下一个
rs.previous();//移动到前一个
rs.afterLast();//移动到最后面
rs.beforeFirst();//移动到最前面
rs.absolute(row);//移动到指定行
释放连接,因为连接很耗资源
10.4 statement 对象
jdbc中的statement对象用于向数据库发送SQL语句,对数据库进行增删改查
主要方法:
excuteQuery(),执行查询,返回一个结果集,包含了查询的结果。
exucteUpdate(),执行更新操作,返回一个int值,进行更新的条数。(更新指的是增加、删除、修改)
SQL注入的问题
SQL语句存在漏洞,被攻击
10.5 prepareStatement
prepareStatement 可以防止SQL注入,并且效率更高
- 新增
- 删除
- 修改
- 查询
10.6 事务
package com.swrici.jdbcDemo.transaction;import com.swrici.jdbcDemo.utils.JdbcUtils;import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;public class TransactionDemo {public static void main(String[] args) throws SQLException {Connection connection = null;PreparedStatement preparedStatement = null;ResultSet resultSet = null;try{connection = JdbcUtils.getConnection();//关闭数据库的自动提交,自动开启事务connection.setAutoCommit(false);String sql1 = "update account set money = money - 100 where name = 'A';";preparedStatement = connection.prepareStatement(sql1);preparedStatement.executeUpdate();int a = 1/0;String sql2 = "update account set money = money + 100 where name = 'B';";preparedStatement = connection.prepareStatement(sql2);preparedStatement.executeUpdate();//业务完毕,提交事务connection.commit();System.out.println("成功");} catch (Exception e) {connection.rollback();e.printStackTrace();}finally {JdbcUtils.realase(connection,preparedStatement,resultSet);}}
}
手动执行事务的时候,要先关闭自动提交事务的按钮,然后在事务结束时要提交事务,再开启自动提交事务。
10.7 数据库连接池
数据据库的连接到释放是十分耗费资源的,如果频繁的调用数据库连接释放就会产生大量的系统开销。
池化技术,就是为了解决这样的麻烦,通过预先准备好一些资源让其连接。
最小连接数:
最大连接数:业务最高承载上限,一旦连接数超过,就让多余的进入等待。
等待超时:时间
编写连接池,只需要一个接口DataSource
开源数据库实现(拿来即用)
DBCP,需要用到的jar包
- commons-dbcp-1.4.jar
- commons-pool-1.6.jar
C3P0,需要用到的jar包
- c3p0-0.9.5.2.jar
- mchange-commons-java-0.2.15.jar
Druid:
在使用这些连接池技术之后,项目开发就中就不需要编写连接数据库的代码了。
结论: 都要实现DataSource接口,所以提供的方法不会变,进和出层面的。
这篇关于MySQL4 -----事务、索引、权限管理和备份、数据库规范三大范式、JDBC、数据库连接池的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






