本文主要是介绍DETR解读,将Transformer带入CV,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
论文出处
[2005.12872] End-to-End Object Detection with Transformers (arxiv.org)
一个前置知识
匈牙利算法:来源于二部图匹配,计算最小或最大匹配
算法操作:在n*n的矩阵中
-
减去行列最小值,更新矩阵(此时行或者列最少一个0)
-
最少的横线来覆盖有0的行列,横线数量等于n结束算法,否则进入循环
-
循环操作:取未被横线覆盖的最小值k,所有未被覆盖的数都减去k(这个步骤至少增加一个0),横线的交点加上k,再次画横线判断
匈牙利算法在CV中用于对目标检测结果的匹配,前后帧之间相同目标的匹配,实现框随目标的运动。
具体的在CV任务中匈牙利算法的匹配代价用框中点之间欧式距离, 也可以是IoU(即框之间的重合度)
DETR:Transformer实现的端到端检测算法
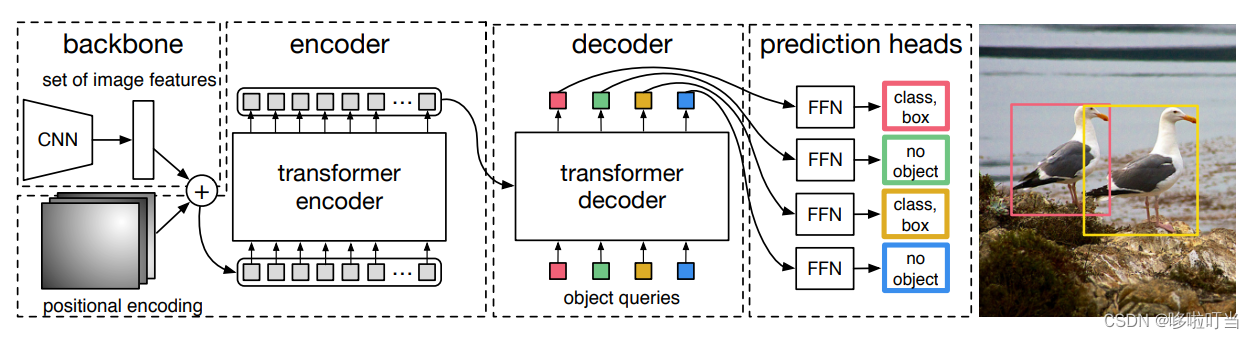

模型训练思路
提前用超参数设置一些预测框,然后根据图像标注的信息得知图像中的物体正确的框选。预测框要和真实的那几个框一一对应,例如图中原本只标注了2个框,但是预测了100个,是从100个中选两个对应上。然后匈牙利算法计算匹配损失,反向传播
测试阶段
计算预测框的类别置信度,达到阈值则可以保留
Transformer先编码图像信息,然后解码,自注意力机制学习图像信息
object query查询图像中是否有物体
这里和NLP任务有明显的不同点。即当前输出是不依赖前一个输出,虽然是用decoder但是多目标的检测是可以并行的
具体操作步骤
-
backbone卷积提取特征,
-
Encoder,特征结合位置编码,两者相加生成Q,K。做多头注意力。每次编解码都使用位置编码
-
Decoder:可以看做两层,先query初始为0,object query这两个query是学习anchor特征,两者相加生成Q,K。再加入图像特征(上一层输出再叠加object query为Q,Encoder输出加上位置编码生成K),学习预测物体类别,坐标,预测框信息等
-
输出:预测类别的标签,预测框的坐标
再介绍几个改进
Deformable DETR
文章出处:[2010.04159] Deformable DETR: Deformable Transformers for End-to-End Object Detection (arxiv.org)
提出可变注意力,这个改进对DETR来说十分关键。不再做全局注意力,只对关键部份做注意力。不仅仅是解决普通DETR计算量大和收敛慢的问题,做局部的注意力使得模型更能学习到关键特征,而不是无用的信息

在这个模型中,查询的Q还是来自特征提取和位置编码。但是K的查询几个点是由用户指定的,而且点的位置是由网络学习得到的。可以理解为最终值是一个点和图中的几个关键点做多头注意力得到。

先对输入Z分别做位置编码得到查询位置的偏移量和Attention Weight,还要对Z做线性变换得到Value。通过位置偏移量就能得到要查询位置的坐标,进一步去除对应位置的Value
Multi-scale Deformable Attention:
多尺度是为了在不同的尺度都能够学习到特征,大尺度对小物体的特征学习有效,小尺度学习大物体特征有效,使用多个尺度做注意力机制模型学习到更多的东西。先分别提取多张不同尺度的feature map,转换成线性之后连接起来,当做一个token,做注意力
RT-DERT
论文出处:
[2304.08069] DETRs Beat YOLOs on Real-time Object Detection (arxiv.org)
RT DETR的提出使得DETR路线的可用性和落地的可能性更进一步。这篇文章提出的实时端到端目标检测器,出发点就是提高模型训练和推理速度。
作者提到他发现模型执行时间取决于:预测框的数量,score threshold类别阈值,IoU threshold冗余框阈值
于是针对这些问题他做了几点创新:
- 只对最小尺度的特征图做可变注意力,其他的尺度做特征融合
- 基于IoU的查询选择,提高性能
- 推理加速,直接使用前几个decoder的输出
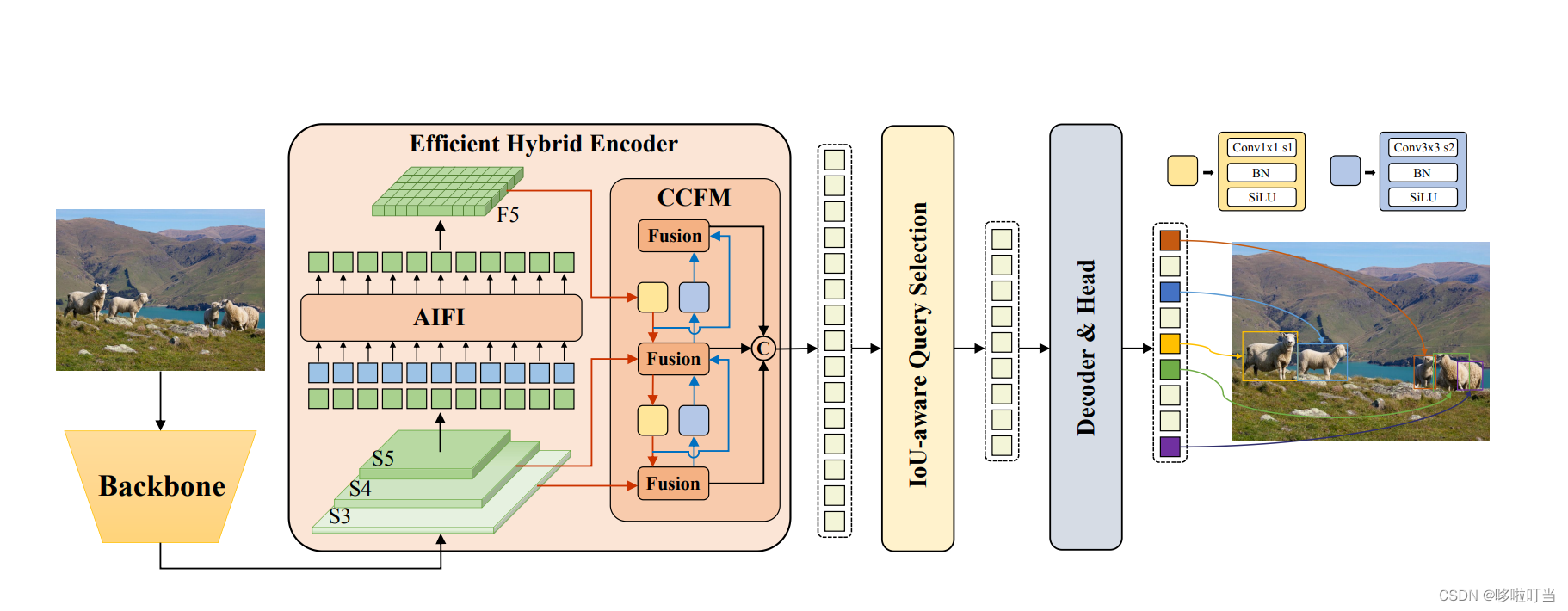
AIFI
对于最小尺度的一个特征图做Transformer encoder,以往是多个尺度的特征拉长成一个很长的一维token,这里减少了计算量。而且小尺度的语义特征更加丰富。
CCFM
每个尺寸两两之间都做特征的融合,做上采样或下采样匹配尺寸,最终拼接成一个列表
这篇关于DETR解读,将Transformer带入CV的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








