本文主要是介绍帮微软语音助手纠正“阿弥陀佛”“e”字错误发音的技巧,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、前言
微软AI文字转语音助手,现已被大家普便应用。最近在传统文化佛学名词的发音转换应用中,发现了一个致命的错误。那就是“阿弥陀佛”中的“阿”字的“a”发音,被误读为“e”。说起这个重大的错误,佛门大德南怀瑾老师也一再叮嘱,希望后人纠正错误发音。毕竟佛学文化是严谨严肃的民族文化。传错了,真就误导后世子孙了。
其实,究其缘起真不怪微软。毕竟西方人不了解东方文化是很正常的。但是,得知这个错误发音,竟然是被某些热门电视剧误读后,才被大众广泛沿用的,不免让人唏嘘。现在国人编剧们,确实要多恶补传统文化了。不然,这复兴中国文化的重任,情何以担呐。哈哈。
阿字在佛法的经咒中使用很多,含义广泛,是口业的代表。那么,问题来了,如何让语音助手云希改掉错误发音呢?
二、解决方案
1、添加标点符号法:
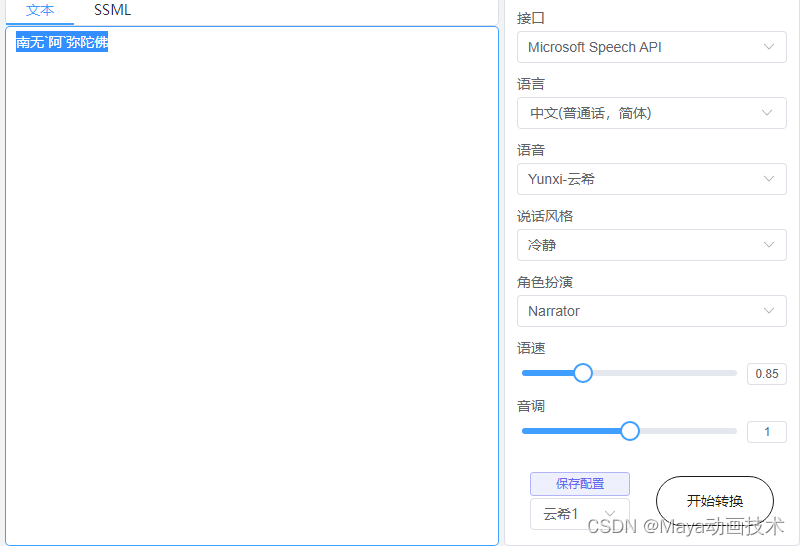
经过反复测试,发现【阿弥陀佛】连读时,一直是错误的e mi tuo fo发音。通过在阿字后加各种分割符测试后。发现,加上一个上斜点【阿`弥陀佛】后,就可以得到语速正常的“a mi tuo fo”发音了。其他的分割符或标点,阿字读音时间过长,不适合连读。好了,这一历史性发音错误,终于解决了。哈哈。
南无阿弥陀佛。
2、微软官方ssml标记法:
以下内容转载自:www.360mb.net/32732.html
前提是软件要支持ssml标记,建议使用开源 tts-vue 软件,gitee和github都有。
1)语法标记说明:
使用微软语音合成 API 进行语音合成时,常用的事件处理包括以下几个方面:
a. 停顿:语音合成会自动根据标点符号以及文本内容进行停顿和语调变换。同时,可以通过添加 SSML 标记来控制停顿的时长和位置,例如使用 <break> 标记来指定停顿的时间长度或调整语调。需要注意的是,停顿时间长度应该适当,过长或过短都不利于语音合成的自然度。
b. 多音:为了避免多音字在语音合成中的发音出现错误,可以通过在相应文字上添加注音或拼音信息来指定正确的读音。例如,可以使用 <phoneme> 标记来指定复杂或罕见的词汇的发音,或使用 <sub> 标记来替换不常用或特殊的词汇。需要注意的是,正确指定多音字的发音对于语音合成的质量具有重要影响。
在使用微软语音合成 API 进行语音合成时,需要注意上述几个方面,并采取相应的措施来保证语音合成的自然度和质量。
2)范例:汉字多音字处理
<phoneme> 标记是 SSML(Speech Synthesis Markup Language)中的一个元素,用于指定特定音素或音序列的发音。在 Microsoft SAPI (Speech API)中,<phoneme> 标记可以使用 alphabet 属性指定音素表类型,使用 ph 属性指定具体的音素或音序列。
中文案例
<speak><s><phoneme alphabet="sapi" ph="a 1">阿</phoneme>弥陀佛。</s><s><phoneme alphabet="sapi" ph="e 1">阿</phoneme>弥陀佛。</s>
</speak>
在 <phoneme alphabet="sapi" ph="shan 4">单</phoneme> 这个例子中,alphabet 属性指定了音素表类型为 Microsoft SAPI,ph 属性指定了要发音的音素或音序列为 “shan 4”,这表示 “单” 这个汉字的第四声音。
因此,当微软语音合成 API 遇到这个 <phoneme> 标记时,会根据指定的音素进行发音,从而可以实现更准确的语音合成效果。
其它案例:
<speak version="1.0" xmlns="http://www.w3.org/2001/10/synthesis" xml:lang="en-US"><voice name="en-US-JennyNeural"><phoneme alphabet="ipa" ph="tə.ˈmeɪ.toʊ"> tomato </phoneme></voice>
</speak>
<speak version="1.0" xmlns="http://www.w3.org/2001/10/synthesis" xml:lang="en-US"><voice name="en-US-JennyNeural"><phoneme alphabet="ipa" ph="təmeɪˈtoʊ"> tomato </phoneme></voice>
</speak>
<speak version="1.0" xmlns="https://www.w3.org/2001/10/synthesis" xml:lang="en-US"><voice name="en-US-JennyNeural"><phoneme alphabet="sapi" ph="iy eh n y uw eh s"> en-US </phoneme></voice>
</speak>
<speak version="1.0" xmlns="http://www.w3.org/2001/10/synthesis" xml:lang="en-US"><voice name="en-US-JennyNeural"><s>His name is Mike <phoneme alphabet="ups" ph="JH AU"> Zhou </phoneme></s></voice>
</speak>
<speak version="1.0" xmlns="http://www.w3.org/2001/10/synthesis" xml:lang="en-US"><voice name="en-US-JennyNeural"><phoneme alphabet='x-sampa' ph='he."lou'>hello</phoneme></voice>
</speak>
停顿处理
在使用微软文字转语音 API 进行 SSML 播放时,可以使用 标签来控制语音合成的停顿或延迟时间。 标签有一个 time 属性,用于指定停顿或延迟的时间长度,单位为毫秒。
例如,下面的代码片段表示在播放语音过程中间隔 2 秒钟的时间:
<speak>
<s>这是一个示例句子。</s>
<break time="2000ms" />
<s>这是下一个示例句子。</s>
</speak>
在这段代码中,通过在两个语音段之间插入 标签,并设置 time属性为“2000ms”,就实现了两个语音段之间停顿 2 秒钟的效果。
需要注意的是,标签的 time属性值不宜过长或过短,过长可能会使语音合成显得拖沓生硬,而过短则可能导致语音合成不太自然。因此,在使用标签时,需要根据实际情况选择合适的停顿或延迟时间。其中2000ms=2s也就是2000毫秒等于2秒,这里的事停顿事件可按需自行处理。
南无阿弥陀佛
这篇关于帮微软语音助手纠正“阿弥陀佛”“e”字错误发音的技巧的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







