本文主要是介绍Pandas—resample重采样,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
重采样指的是将时间序列从一个频率转换到另一个频率的处理过程。
时间序列基础
pandas对象都带有一个resample方法,它是各种频率转换工作的主力函数。
调用resample可以分组数据,然后会调用一个聚合函数(mean,max,min等)
import pandas as pd
import numpy as np
rng = pd.date_range('2000-01-01', periods=12, freq='T')
ts = pd.Series(np.arange(12), index=rng)
ts
2000-01-01 00:00:00 0
2000-01-01 00:01:00 1
2000-01-01 00:02:00 2
2000-01-01 00:03:00 3
2000-01-01 00:04:00 4
2000-01-01 00:05:00 5
2000-01-01 00:06:00 6
2000-01-01 00:07:00 7
2000-01-01 00:08:00 8
2000-01-01 00:09:00 9
2000-01-01 00:10:00 10
2000-01-01 00:11:00 11
Freq: T, dtype: int32
降采样
在用resample对数据进行降采样时,需要考虑两样东西:
1.各区间哪边是闭合的。
2.如何标记各个聚合面元,用区间的开头还是末尾。
# 通过求和的方式将这些数据聚合到“5分钟”块中
ts.resample('5min', closed='right').sum()
1999-12-31 23:55:00 0
2000-01-01 00:00:00 15
2000-01-01 00:05:00 40
2000-01-01 00:10:00 11
Freq: 5T, dtype: int32
#传入label='right'即可用面元的邮编界对其进行标记:
ts.resample('5min', closed='right', label='right').sum()
2000-01-01 00:00:00 0
2000-01-01 00:05:00 15
2000-01-01 00:10:00 40
2000-01-01 00:15:00 11
Freq: 5T, dtype: int32
升采样和插值
注意,新的日期索引完全没必要跟旧的重叠
frame = pd.DataFrame(np.random.randn(2, 4),index=pd.date_range('1/1/2000', periods=2,freq='W-WED'),columns=['Colorado', 'Texas', 'New York', 'Ohio'])
frame
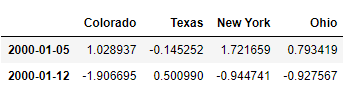
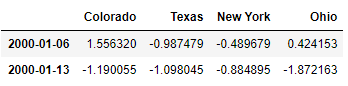
frame.resample('D').ffill(limit=2)

frame.resample('W-THU').ffill()
通过时期进行重采样
由于时期指的是时间区间,所以升采样和降采样的规则就比较严格:
在降采样中,目标频率必须是源频率的子时期(subperiod)。
在升采样中,目标频率必须是源频率的超时期(superperiod)。
这主要影响的是按季、年、周计算的频率。
frame = pd.DataFrame(np.random.randn(24, 4),index=pd.period_range('1-2000', '12-2001',freq='M'),columns=['Colorado', 'Texas', 'New York', 'Ohio'])
# Q-DEC: Quarterly, year ending in December
frame.resample('Q-DEC').mean()

这篇关于Pandas—resample重采样的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







