本文主要是介绍机器阅读理解Machine Reading Comprehension(MRC)基本介绍,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- NLP相关任务的基本流程
- MRC四大任务
- 各任务相关数据集
- 机器阅读理解架构及方法
- 总体架构
- 评测指标
NLP相关任务的基本流程
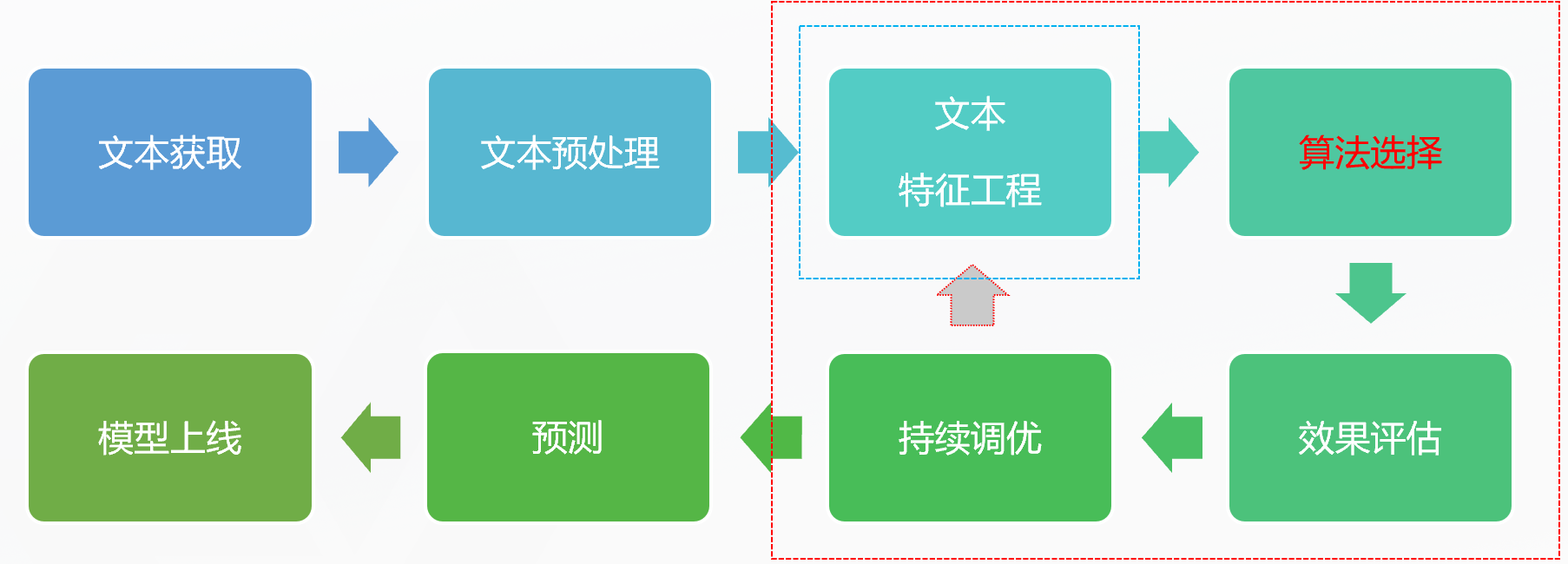
文本预处理:
- 去除冗余字符标记(正则表达式)
- 分词(jieba)
- 单词处理(英文:大写->小写,单词还原,同义词扩展)
- 去除停用词
- 保护词应用于分词模块:开课吧,后厂理工学院
- 同义词用于分词后的语料扩展:扩展->扩充
- 停止词用于去除干扰信息,提取主要信息:的, 么, 了……
MRC四大任务
完形填空:原文中除去若干关键词,需要模型填入正确的单词或短语。
多项选择:模型需要从给定的若干选项中选出正确答案
答案抽取:回答限定是文章的一个子句,需要模型在文章中标注正确答案的起始和终止位置。
自由回答:不限定模型生成答案的形式,允许模型自由生产数据
各任务相关数据集
-
完形填空:
- CNN&Daily Mail
- CBT
-
单项选择
- MC Test
- RACE
-
答案抽取:
- SQuAD
- NewsQA
-
自由回答:
- MS MARCO
- DuReader2.0(10w可回答问题 +5w无答案问题)数据集在设计无答案的问题,就是看模型是否真的理解了问题,而不是单纯的匹配。
- http://ai.baidu.com/broad/download?dataset=dureader
- https://aistudio.baidu.com/aistudio/competition/detail/28
机器阅读理解架构及方法
-
特征+传统机器学习
-
BERT以前:各种神奇的QA架构
-
BERT以后:预训练+微调+trick
总体架构
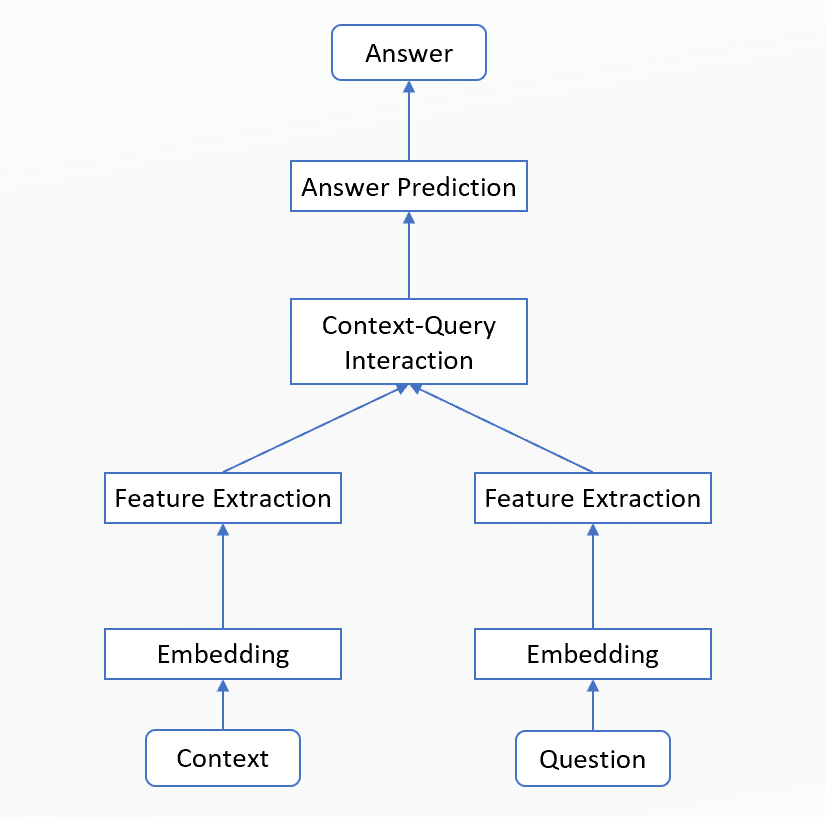
最重要的模块是:Context-Query Interaction
评测指标
Accuracy:一共m个问题答对了n个
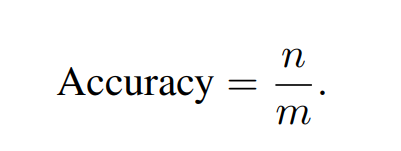
F1


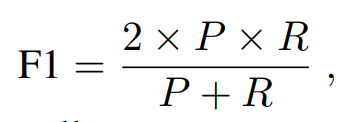
Rouge-L:
最长公共子序列LCS,X为目标,Y为模型,m为标准答案的单词个数,n为模型答案的单词个数。 β \beta β一般取无穷大。所以F=R。
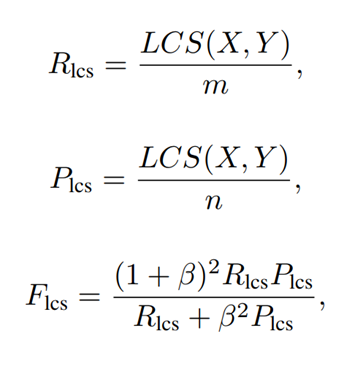
BLEU
示例:
candidate: the cat sat on the mat
reference: the cat is on the mat
就 b l e u 2 bleu_2 bleu2对 candidate中的5个词,{the cat,cat sat,sat on,on the,the mat} ,查找是否在reference中,发现有3个词在reference中,所以占比就是0.6
b l e y 1 = 5 6 = 0.83 bley_1= \frac{5}{6} = 0.83 bley1=65=0.83
b l e y 3 = 3 5 = 0.60 bley_3= \frac{3}{5} = 0.60 bley3=53=0.60
b l e y 3 = 1 4 = 0.25 bley_3= \frac{1}{4} = 0.25 bley3=41=0.25
b l e y 4 = 0 3 = 0 bley_4= \frac{0}{3} = 0 bley4=30=0
改进后的BLEU
https://blog.csdn.net/guolindonggld/article/details/56966200
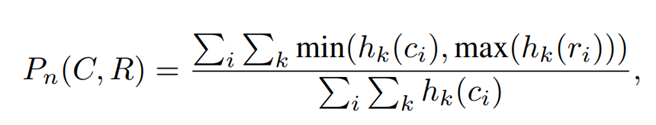
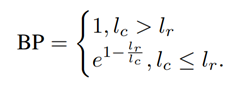
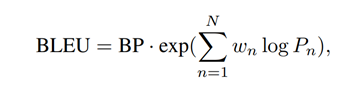
这篇关于机器阅读理解Machine Reading Comprehension(MRC)基本介绍的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





