本文主要是介绍论文阅读《thanking frequency fordeepfake detection》,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
这篇论文从频域的角度出发,提出了频域感知模型用于deepfake检测的模型
整体架构图:

1.FAD:
频域感知分解,其实就是利用DCT变换,将空间域转换为频域,变换后的图像低频信息在左上角,高频信息在右下角,同时高频表示细粒度的伪造痕迹,因为进过DCT变换后的图像不再具有尺度不变性和局部相关性的RGB图像特性,故需要对其进行IDCT变换为RGB域。
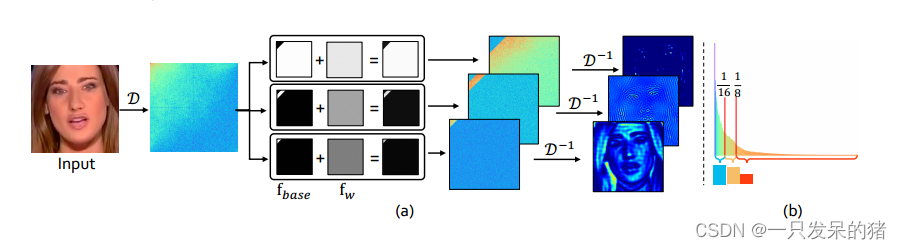
图3(b)展示了DCT功率谱的分布。通过将2D功率谱展平为1D表示,通过对每个频率带的振幅求和。
根据自然图像的DCT功率谱特性,我们观察到大部分能量集中在低频区域。为了在频率感知分解中适应地捕捉到不同频率的信息,我们将频谱分为几个能量相等的频带,并使用基本滤波器来定义这些频带。通过添加可学习滤波器,我们可以更灵活地选择感兴趣的频率范围。在这里,作者选择了3个频带,其中低频带占整个频谱的1/16,中频带占1/16到1/8,高频带占剩下的7/8。
这样的频率划分方式有助于在频率感知图像分解中捕捉到不同频率范围内的信息,特别是对于处理与压缩伪影相关的伪造模式而言。通过将频谱分解为不同的频带,方法可以更好地适应不同频率范围内的信号特性,从而提高对压缩伪影的描述和处理能力。
---------------------------------------------------
与传统手工设置的滤波器不同的是,作者在论文中提出了一个基础滤波器和可学习滤波器相结合的滤波器,使得模型的学习能力更强同时解决传统手工滤波器无法完全覆盖频率域的问题。
a.作者提出了一种新颖的频率感知分解(FAD)方法,根据一组可学习的频率滤波器在频率域上自适应地对输入图像进行分割。
b.分解的频率分量可以逆变换到空间域,得到一系列频率感知图像分量。
c.这些分量沿通道轴堆叠,并输入到卷积神经网络中.
DCT的两个特点:
a.DCT被广泛应用于图像压缩、去噪、特征提取等领域,因为它能够将信号分解为频率成分,并且能够以较高的能量集中在较少的系数上。
b.其频率分布的布局使得低频成分主要集中在左上角,而高频成分主要集中在右下角,这种布局有助于对图像中的频率信息进行分析和处理。
2.LFS
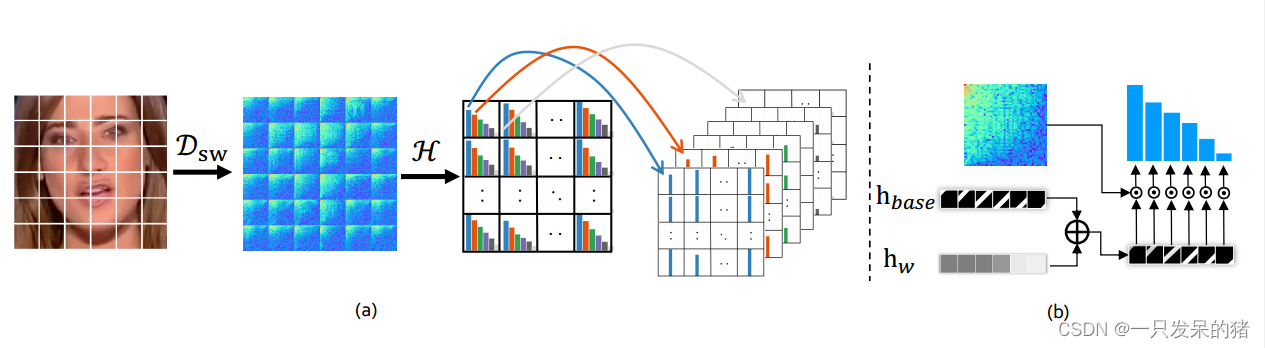
频率感知分解(FAD)提供了与卷积神经网络(CNNs)兼容的频率感知表示,但它必须将频率感知线索重新表示到空间域中,因此无法直接利用频率信息。同时,由于直接从频谱表示中提取CNN特征通常是不可行的,作者提出估计局部频率统计(Local Frequency Statistics,LFS),不仅可以明确地呈现频率统计信息,还可以匹配天然RGB图像所具有的平移不变性和局部一致性。然后,将这些特征输入到卷积神经网络(例如Xception [12])中,以发现高级的伪造模式。
如图4(a)所示,我们首先对输入的RGB图像应用滑动窗口离散余弦变换(Sliding Window DCT,SWDCT),即在图像的滑动窗口上密集地进行离散余弦变换,以提取局部的频率响应。然后,在一系列可学习的频率带上计算平均频率响应。这些频率统计信息重新组合成一个多通道的空间映射,与输入图像具有相同的布局。这种局部频率统计提供了一个定位的窗口,用于检测详细的异常频率分布。在一组频率带内计算统计信息可以减少统计表示的复杂性,同时产生一个更平滑的分布,不受异常值的干扰。
简而言之,这段话说明了作者提出的方法。作者建议使用局部频率统计(LFS)来明确地呈现频率统计信息,并且与自然RGB图像所具有的平移不变性和局部一致性相匹配。通过应用滑动窗口离散余弦变换和计算频率统计信息,将频率感知线索重新表示到空间域中,并输入到卷积神经网络中,以发现高级的伪造模式。这种方法可以提供更详细的异常频率分布,并减少统计表示的复杂性。
3.融合
通过交叉注意力模块逐渐融合两个流的FAD和LFS特征。
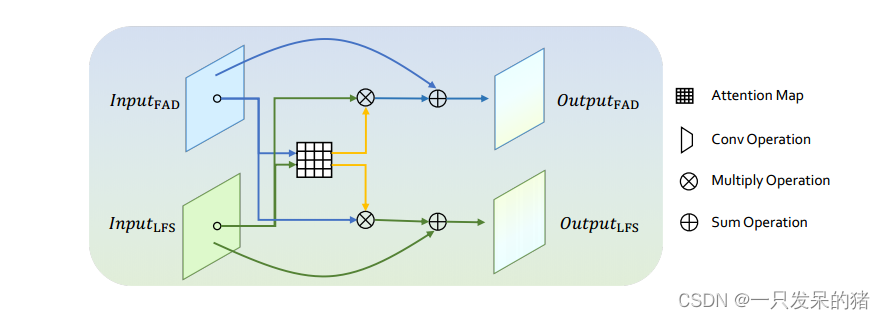
F3-Net的整个网络架构由两个分支组成,每个分支都配备了Xception块,一个用于由FAD生成的分解图像组件,另一个用于由LFS生成的局部频率统计,如图2所示。
我们提出了一个交叉注意力融合模块,用于特征交互和信息传递,每隔几个Xception块进行一次。与先前方法中广泛使用的简单连接不同,作者首先使用来自两个分支的特征图计算交叉注意力权重。
交叉注意力矩阵被用来增强一个流的关注特征到另一个流中。
预训练的Xception网络作为两个分支的基础网络,每个分支都有12个块。根据中等级别和高级别语义,在第7个块和第12个块之后采用MixBlock来融合两种类型的频率感知线索。
---------------------------------------------------------
如何理解经过DCT变换之后,图像不再具有尺度不变性和局部一致性。
2.LFS:局部频域统计
是将图像进行划分成小的patch块,然后使用滑动窗口依次在每个patch快上进行DCT变换
我的理解:
DCT变换是将图像在空间域上的表示转换到频域上的表示,表示每个频域的分布多少,当尺度发生变化时,频域上的表示会有所改变,同时对于局部不变性也会发生改变,因为相邻域在频域上的关系并不是与RGB域是的邻域是对应的关系,总之两者是图像的不同表现形式
官方解答:
DCT(离散余弦变换)是一种常用的图像变换方法,它将图像从空域转换到频域。DCT变换通常用于图像压缩和信号处理领域。
1.DCT变换,通过计算不同频率的分量来表示图像的频域特征。
每个频域分量表示了在图像中特定频率的振幅信息。当图像的尺度发生变化时,图像的频域表示会相应地改变。
较小尺度的细节可能在高频分量中表示,而较大尺度的结构可能在低频分量中表示。
2.此外,DCT变换后的频域表示可能会破坏图像中相邻像素的空间关系。在空域中,相邻像素具有空间上的局部一致性,但在频域中,相邻像素的频域表示可能相差较大,并不直接对应于空域中的邻域关系。。
这篇关于论文阅读《thanking frequency fordeepfake detection》的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)