本文主要是介绍pytorch学习笔记 (visdom可视化、正则化、动量、学习率衰减、BN),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、visdom可视化工具
安装: pip install visdom
启动: 命令行直接运行visdom

打开WEB: 在浏览器使用http://localhost:8097打开visdom界面
二、使用visdom
# 导入Visdom类
from visdom import Visdom
# 定义一个env叫Mnist的board,如果不指定,则默认归于main
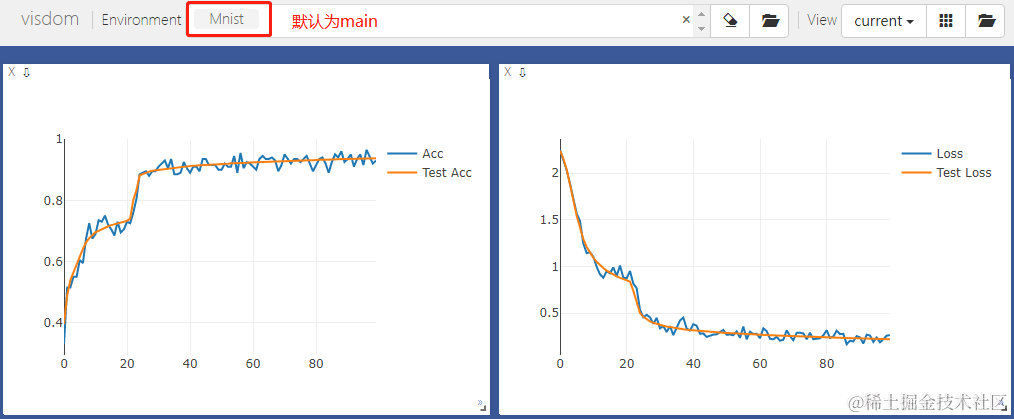
viz = Visdom(env='Mnist')# 在window Accuracy中画train acc和test acc,x坐标都是epoch
viz.line(Y=np.column_stack((acc, test_acc)),X=np.column_stack((epoch, epoch)),win='Accuracy',update='append',opts=dict(markers=False, legend=['Acc', 'Test Acc']))
# 在window Loss中画train loss和test loss,x坐标都是epoch
viz.line(Y=np.column_stack((loss.cpu().item(), test_loss.cpu().item())),X=np.column_stack((epoch, epoch)),win='Loss',update='append',opts=dict(markers=False, legend=['Loss', 'Test Loss']))
三、使用正则化
正则化也叫权重衰减(Weight Decay)
L1和L2正则化可以参考:https://blog.csdn.net/red_stone1/article/details/80755144
在代码中,我们只需要在优化器中使用weight_decay参数就可以启用L2正则化
# 选择一个优化器,指定需要优化的参数,学习率,以及正则化参数
optimizer = torch.optim.SGD(net.parameters(), lr=learning_rate, weight_decay=0.01)
由于在Pytorch中没有纳入L1正则化,我们可以通过手工实现:
# 正则化超参数lambda
lambd = 0.01
# 所有参数的绝对值的和
regularization_loss = 0for param in model.parameters():regularization_loss += torch.sum(torch.abs(param))# 自己手动在loss函数后添加L1正则项 lambda * sum(abs)
loss = F.cross_entropy(z, target) + lambd * regularization_loss
optimizer.zero_grad()
loss.backward()
四、使用Momentum动量
使用Momentum,即在使用SGD时指定momentum参数,如果不指定,默认为0,即不开启动量优化模式。
# 选择一个优化器,指定需要优化的参数,学习率,以及正则化参数,是否使用momentum
optimizer = torch.optim.SGD(net.parameters(), lr=learning_rate, momentum=0.9, weight_decay=0.01)
使用Adam时,由于Adam包含了Monmentum,所以他自己指定了Momentum参数的大小,无需我们指定。
五、学习率衰减 Learning rate decay

当学习率太小时,梯度下降很慢。当学习率太大时,可以在某个狭窄区间震荡,难以收敛。
学习率衰减就是为了解决学习率多大这种情况。
当我们在训练一个模型时,发现Loss在某个时间不发生变化(在一个平坦区),则我们要考虑是否是在一个狭窄区间震荡,导致的难以收敛。
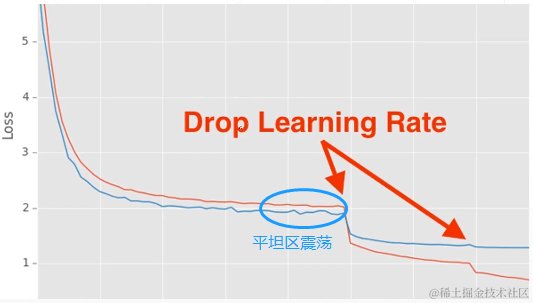
我们在pytorch中可以使用ReducelROnPlateau(optimizer,‘min’)来监控loss的值:
from torch.optim.lr_scheduler import ReduceLROnPlateau# 选择一个优化器,指定需要优化的参数,学习率,以及正则化参数,是否使用momentum
optimizer = torch.optim.SGD(net.parameters(), lr=learning_rate, momentum=0.9, weight_decay=0.01)# 使用一个高原监控器,将optimizer交给他管理,LR衰减参数默认0.1即一次缩小10倍,patience是监控10次loss看是否变化
scheduler = ReduceLROnPlateau(optimizer, mode='min', factor=0.1, patience=10)# 后面的optimizer.step()使用scheduler.step(loss)来代替,每次step都会监控一下loss
# 当loss在10次(可以设置)都未变化,则会使LR衰减一定的比例
另外,除了上述使用ReducelROnPlateau,还可以使用更为粗暴的StepLR函数,我们可以直接指定在多少step后下降一次LR的值:
from torch.optim.lr_scheduler import StepLR# 选择一个优化器,指定需要优化的参数,学习率,以及正则化参数,是否使用momentum
optimizer = torch.optim.SGD(net.parameters(), lr=learning_rate, momentum=0.9, weight_decay=0.01)# 使用StepLR,指定step_size即每多少步衰减一次,gamma为衰减率,0.1代表除以10
scheduler = StepLR(optimizer, step_size = 10000, gamma=0.1)# 后面的optimizer.step()使用scheduler.step()
六、在全连接层使用batchnorm
# -*- coding:utf-8 -*-
__author__ = 'Leo.Z'import torch
from visdom import Visdom
import numpy as npimport torch.nn.functional as F
from torch.nn import Module, Sequential, Linear, LeakyReLU, BatchNorm1d
from torchvision import datasets, transforms
from torch.utils.data import DataLoaderbatch_size = 200
learning_rate = 0.001
epochs = 100train_data = datasets.MNIST('../data', train=True, download=True,transform=transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.1307,), (0.3081,))]))test_data = datasets.MNIST('../data', train=False,transform=transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.1307,), (0.3081,))]))train_db, val_db = torch.utils.data.random_split(train_data, [50000, 10000])train_loader = DataLoader(train_db,batch_size=100, shuffle=True)
val_loader = DataLoader(val_db,batch_size=10000, shuffle=True)
test_loader = DataLoader(test_data,batch_size=10000, shuffle=True)# 网络结构
class MLP(Module):def __init__(self):super(MLP, self).__init__()self.model = Sequential(Linear(784, 200),#===================== BN-start ======================# 这里对第一层全连接层使用BN1d,在多个样本上对每一个神经元做归一化BatchNorm1d(200, eps=1e-8),# ===================== BN-end =======================LeakyReLU(inplace=True),Linear(200, 200),#===================== BN-start ======================# 这里对第二层全连接层使用BN1d,在多个样本上对每一个神经元做归一化BatchNorm1d(200, eps=1e-8),# ===================== BN-end =======================LeakyReLU(inplace=True),Linear(200, 10),LeakyReLU(inplace=True))def forward(self, x):x = self.model(x)return x# 定义一个env叫Mnist的board,如果不指定,则默认归于main
viz = Visdom(env='TestBN')# 定义GPU设备
device = torch.device('cuda')
# model放到GPU
net = MLP().to(device)# 选择一个优化器,指定需要优化的参数,学习率,以及正则化参数,是否使用momentum
optimizer = torch.optim.SGD(net.parameters(), lr=learning_rate, momentum=0.9, weight_decay=0.01)for idx, (val_data, val_target) in enumerate(val_loader):val_data = val_data.view(-1, 28 * 28)val_data, val_target = val_data.to(device), val_target.to(device)for epoch in range(epochs):for batch_idx, (data, target) in enumerate(train_loader):# data转换维度为[200,784],target的维度为[200]data = data.view(-1, 28 * 28)# 将data和target放到GPUdata, target = data.to(device), target.to(device)# data为输入,net()直接执行forward# 跑一次网络,得到z,维度为[200,10],200是batch_size,10是类别# 由于net在GPU,data也在GPU,计算出的z就在GPU# 调用net(data)的时候相当于调用Module类的__call__方法z = net(data).to(device)# 将loss放到GPUloss = F.cross_entropy(z, target).to(device)# 每次迭代前将梯度置0optimizer.zero_grad()# 反向传播,计算梯度loss.backward()# 相当于执行w = w - dw,也就是更新权值optimizer.step()### 每一轮epoch,以下代码是使用分割出的val dataset来做测试# 先计算在train dataset上的准确率eq_mat = torch.eq(z.argmax(dim=1), target)acc = torch.sum(eq_mat).float().item() / eq_mat.size()[0]print('Loss:', loss)print('Accuracy:', acc)# 用val跑一遍网络,并计算在val dataset上的准确率# ===================== BN-start =====================# 跑网络之前,先将BN层设置为validation模式# BN层会自动使用在训练时累计的running_mean和running_varnet.eval()#net.model[1].eval()#net.model[4].eval()# ===================== BN-end =======================val_z = net(val_data).to(device)val_loss = F.cross_entropy(val_z, val_target).to(device)val_eq_mat = torch.eq(val_z.argmax(dim=1), val_target)val_acc = torch.sum(val_eq_mat).float().item() / val_eq_mat.size()[0]print('Val Loss:', val_loss)print('Val Accuracy:', val_acc)# 将loss和acc画到visdom中viz.line(Y=np.column_stack((acc, val_acc)),X=np.column_stack((epoch, epoch)),win='Accuracy',update='append',opts=dict(markers=False, legend=['Acc', 'Val Acc']))# 将val loss和val acc画到visdom中viz.line(Y=np.column_stack((loss.cpu().item(), val_loss.cpu().item())),X=np.column_stack((epoch, epoch)),win='Loss',update='append',opts=dict(markers=False, legend=['Loss', 'Val Loss']))
使用BN时的ACC和LOSS:
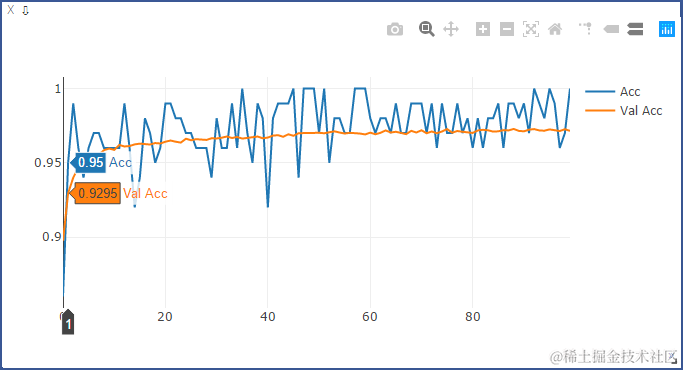
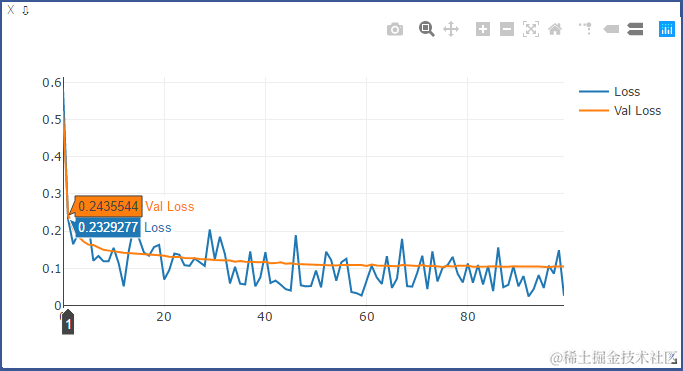
未使用BN时的ACC和LOSS:

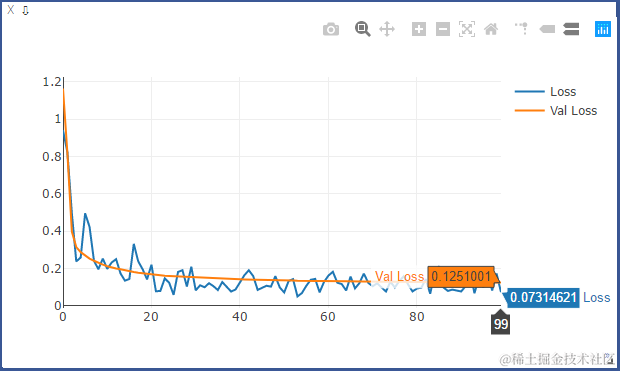
从上述结果可以看出,使用BN后,收敛速度变快。
这篇关于pytorch学习笔记 (visdom可视化、正则化、动量、学习率衰减、BN)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





