|
接着上一次爬虫我们继续研究BeautifulSoup
Python简单爬虫入门一
上一次我们爬虫我们已经成功的爬下了网页的源代码,那么这一次我们将继续来写怎么抓去具体想要的元素
首先回顾以下我们BeautifulSoup的基本结构如下

#!/usr/bin/env python
# -*-coding:utf-8 -*-from bs4 import BeautifulSoup
import requestsheaders = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36',
}url = "爬取网页的地址"web_data = requests.get(url,headers=headers)
soup = BeautifulSoup(web_data.text,"lxml") 重要事情再次强调这是我们开始爬取网页的一个基本结构,如同建楼的一个地基。
首先导入所需的工具也就是模块方法 from import
伪装浏览器headers向浏览器发出请求requests.get拿到返回结果在用BeautifulSoup以lxml格式解析网页代码
那么到这我们就开始取网页中我们想要的数据例如图片(一般都会放到标签img下的src内),标题(一般以title命名或者放入h3或a标签里),在就是内容也会放入和标题一样的
标签中怎么区分一般会通过CSS命名结构来区分。
1.先来抓去最直观的图片地址:
操作先鼠标右键也就是俗称反键--下一步点审查元素据可以找到你选取位置的元素地址:

是不是显示了图片的地址以及标签img src="这里放的连接就是图片地址"
那么我们接着我们上面的程序写如下代码来抓去图片地址标签:
from bs4 import BeautifulSoup
import requestsheaders = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36',
}url = "http://www.lotour.com/guoneiyou/"web_data = requests.get(url,headers=headers)
soup = BeautifulSoup(web_data.text,"lxml")
imgs = soup.select("img")
for img in imgs:print img 大家其实只用在结构代码改变url地址,然后加入imgs = soup.select("img") 这写法就等于 变量名 = 赋值这个值是什么类型之类的
select是一个选择获取的方法如果大家用过mysql select * from table 是不是可以查看表内容一样的效果("img")就是获取哪标签,和mysql选取位置where类似
由于select是一次性获取返回列表,所以看起来很费劲再次我就用for循环去除每一个元素这样可以看到多行数据效果图如下:
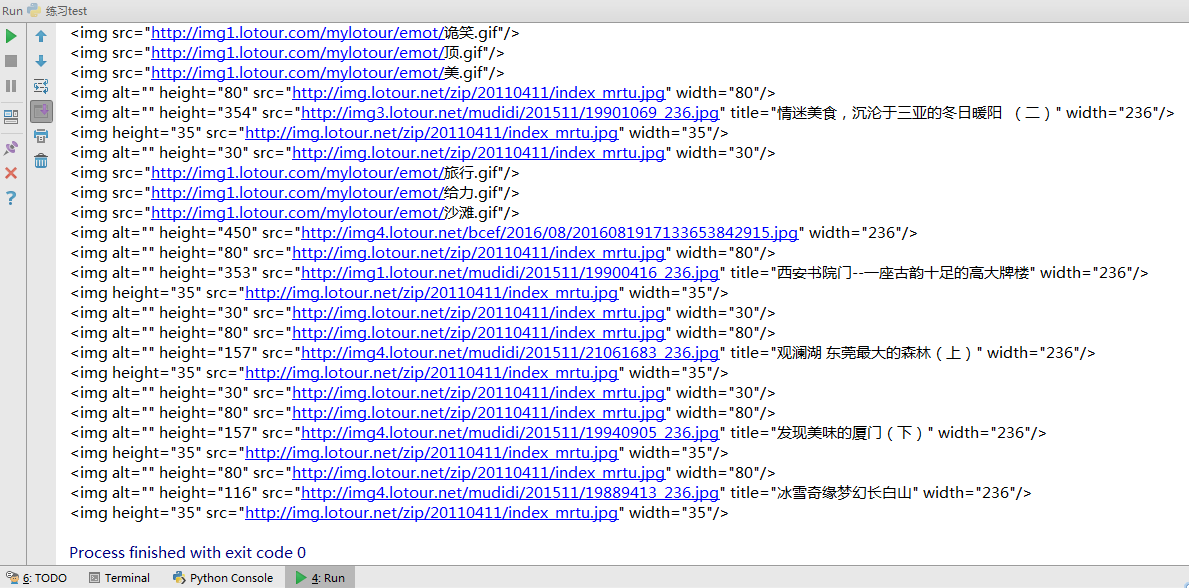
如何去除中间src方法有很几种其中例如正则匹配,不过我们有简单的内置方法想听结果如何下回分解。
无论工具多好用,得多用你才能熟练,现在我们继续抓去标题也可能是内容的当然还是一步步来熟练操作,
鼠标右键点击标题处或者是内容--点击审查元素效果如下:

这里一一对应了网页上的小标题以及源代码的位置及其标签 最后细心的朋友会发现html body div #container....div.auther p a这一行肯定会疑惑这是什么
其实这里就是网页标签的层级关系以及内容的定位作用想了解的去看我的HTML的基本组成结构与标签就会有所了解这里就不多介绍了
那么我们还是以基础结构添加以下代码来抓去网页的小标题,提醒网页的其它内容也同此原理,大家多练多想多总结很快就上手了。
titles = soup.select(" div.auther > p > a")
for title in titles:print title 老规矩用select来选择获取的内容("div.auther > p > a")这就是网页定位标题的位置意思:在div标签CSS是auther中间用.点连接下的p标签下的a标签内
由于标签有层级结构我们要告诉代码去哪里找东西,打个比方BOSS要你去资料室,A柜里面的第三行中的马总公司资料拿来一样。
这里如过还是模糊我建议你试着去多练习抓去其它的元素多练习几次可能就有自己的理解见地,掩饰效果如下:

那么接下来就是大家自由发挥的事件了,是去爬各大购物网站的妹子也好,还是爬各大电影网站的电影名也好,只要多练习就熟练了,最后要提醒的是很多网站爬出来会
出现乱码当然这不是程序问题是网站的编码结构不一样需要去解码,对于解码不推荐小白去学,还是看了基础在研究,来叫大家怎么看网页的编码
还是右键-审查元素(有的网站会屏蔽此功能和查看源代码)查看网页中charset = "编码格式" 如果是标准utf-8还好 如果是gb2312或其它可能你抓的信息就会出现乱码
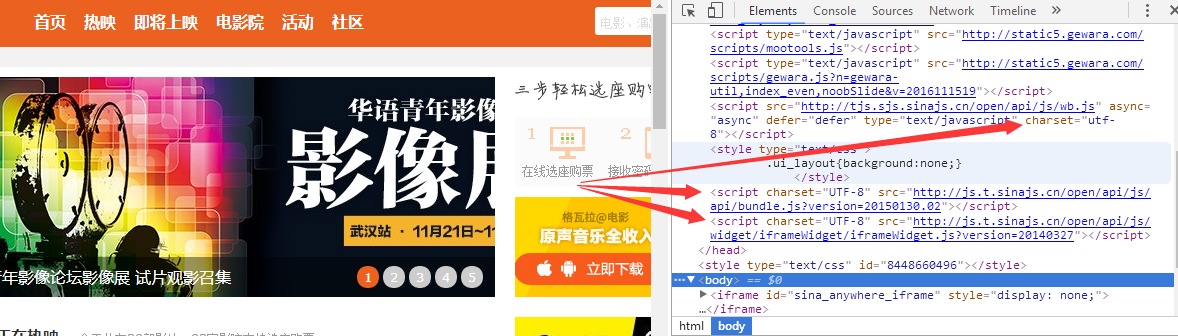
所以碰到此内问题 请小白绕道吧 因为如果你不学深入点很难解释,有基础的百度解决,我也会在以后专门写一次关于程序代码的标题(尽请期待)
最后你能独到这我只能说谢谢观看下次再会。。!




