本文主要是介绍基于CNN的图像增强之去模糊,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
图像模糊产生的原因非常多, 主要如下:
(1)相机抖动. □ 拍摄时相机不稳. □ 全部画面被模糊.
(2)物体的运动. □ 部分物体运动. □ 不同区域模糊不同.
(3) 镜头失焦. □ 大光圈小景深时的效果. 等等。
今天在看Learning Deep CNN Denoiser Prior for Image Restoration (CVPR, 2017) 的文章,里面涵盖的内容非常全,其中模糊也是其中主要工作之一,这工作挺有意思的,因此对其进行复现。
1、论文原理
论文为图像恢复,主要包括图像去噪、图像去模糊和图像超分辨率重建。本博客主要关注的是模糊。
论文将图像恢复统一为一个操作,如论文所述:即目标要还原出干净的x.

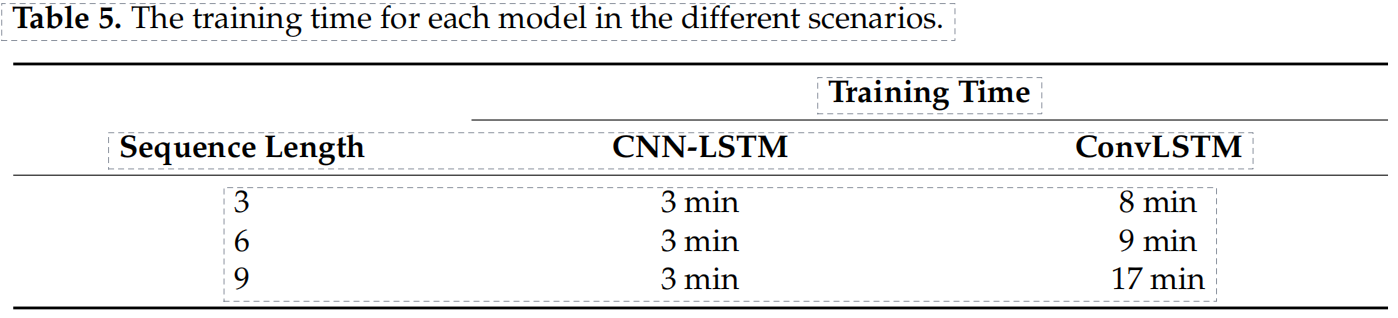
其采用模型框架如下:由七层组成,含三种blocks,分别是:第一个“dilated Convolution+Relu”,中间五个“dilated Convolution+BN+Relu”,最后一层“dilated Convolution”。其中空洞因子(dilated factors,3×3)被依次设置为,1,2,3,4,3,2,1。每一个中间层的feature maps个数均为64.
论文的主要核心环节:
(1)Using Dilated Filter to Enlarge Receptive Field. 使用dilated filter扩大感受野。
(2)Using Batch Normalization and Residual Learning to Accelerate Training. 使用批标准化BN和残差学习加速训练。
(3)Using Training Samples with Small Size to Help Avoid Boundary Artifacts 使用小尺寸训练样本避免边界效应。
(4)Learning Specific Denoiser Model with Small Interval Noise Levels. 学习噪声水平间隔较小的特定的去噪模型。
2、论文实践复现效果如下图所示:






不过比较难的程序输入是需要同时指定其模糊矩阵图,这个在实际应用中还有等于进一步细化。
这篇关于基于CNN的图像增强之去模糊的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!