本文主要是介绍Oracle 知识精要汇总,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
oracle语句,需要了解一下~
oracle知识的总结
一、主要数据类型
1.字符型
varchar(10):定长的字符型数据char(2):定长的字符型数据varchar2(20):变长的字符串数据long :变长度的字符串,最大字节数可达2GBBLOB:二进制数据,最大字节数4GBFILE:二进制数据外部存储,最大字节数4G
2.数据型
number(4):不带小数点的数据number(8,2):数据的总长度是8位,小数点后占两位
3.日期型
date
二、SQL语句分类
DML语句(数据操纵语言)
insert 添加/update 修改/delete 删除/merge 合并
DDL语句(数据定义语言)
create 创建/drop 删除/truncate
DCL语句(数据控制语言)
grant/revoke
事务控制语句
commit / rollback/savepoint
三、表操作
~创建
--创建数据表
1.在建表的时候,先建立父表,后建立子表;2.先添加父表数据,后添加子表数据3.删除数据的时候,先删除子表数据,后删除父表数据4.删除表的时候,先删除子表,后删除父表
--创建表
create table card(cid number(4) primary key,pname varchar2(20)
);
create table perscn(pid number(4) primary key,pname varchar2(20),cid number(4),--添加外键,给表添加外键,指定哪个表constraints FK_Per_crad foreign key(cid) references card(cid),constraint cid_uni unique (cid)
)--查看表结构,只能在命令行模式下
desc users;
--删除表
drop table "表名";/*没有 if exists字段*/
-
在建表的时候使用子查询
create table user as select name ,age from user where id=5; --创建表和查询的字段一样 create table user_a("名字","性别","住址") as select * from user; -
同义词
就是数据库对象的一个别名,可以简化访问其他用户的数据库兑现那个select name from user_table; --创建user_table表名的别名user,方便使用 create or repalce synonym user for user_table
~Alter修改表(表结构)
alter table 表名 add 字段 数据类型
/*添加单行*/alter table user add score varchar2(3);/*添加多行*/alter table user add (score varchar2(3),disth varchat2(100))
-
修改字段
--在改字段没有数据的时候,字段的类型和长度都是可以修改的 alter table user modify tel number(11);--对于缺省值的修改,不会影响已经存在的数据,只会对以后插入的数据产生影响 --不会改变表中的性别,但对新插入的数据的性别会有影响 alter table user modify sex default '女';--当该字段有数据的时候,字段的类型是不能修改的;字段的长度是可以修改的,增大总是可以的,减少要看数据的实际长度; alter table user modify name varchar2(20); -
删除字段
--有无数据都可以删除 alter table user drop column name; -
修改列名,用to连接(mysql不用)
--将user中addre列名改为address alter table user rename addre to address; -
修改列类型(有数据时不可修改,mysql可以)
--将user中的score列类型修改 alter table user modify (score varchar2(3));
~insert插入
--一次性插入多条数据,复制表中的数据,把插入结果当作数据插入到表中insert into user select * from user1;
~update更新
--使用update语句的时候,在事务没有结束之前,该条数据会被锁住,其他的用户无法修改这条数据--事务结束之后,该条数据的锁放开,其他的用户可以操作这条数据update user set ename='xiaoming',eage=3,eaddre='pingyao' where empid=5;
~delete删除
delete from user where sal > 5000;
比较,删除表truncate table删除表的数据,truncate table 比delete的删除速度快,但是改命令一定要慎重使用
清空users表
truncate table users;--回滚是不可能的
~改变对象的名称
--改变表的名字
rename user to users;
用 ‘||’ 可以把两列或者多列查询结果合并到一起- 任何类型都支持null
~给表列加注释
--给表userTable的name字段加注释
comment on column userTable.name is '用户名';
--给表userTable加注释
comment on table userTable is '用户信息表';
参考图

·四、去除重复的数值distinct
--去除单列重复的数据
select distinct deptno from emp;
--去除多列重复的数据
select distinct job,deptno from emp
·五、where子句过滤
-
对字符型的数据和日期型的数据必须要使用单引号 ‘’
-
对于日期型的数据,格式是敏感的,使用日期型的数据的格式是DD-MM-YYYY(日-月-年)
--查询emp表时间为'20-02-1981'的数据
select * from emp where date='20-02-1981'
- 改变当前会话中的日期格式
--改变会话session的日期格式为"YYYY-MM-DD HH:MI:SS"
alter session set date = "YYYY-MM-DD HH:MI:SS"
- 在查询条件中使用其他的比较运算符
用 and 代替 &&
用 or 代替 ||
·六、like模糊查询
--名字带%号的,相当于转义符;即,‘\’为转移字符,第二个‘%’为普通字符,第一第三个是通配符
select * from emp where ename like '%\%%' escape '\';
·七、单行函数和多行函数
- 单行函数:每次取一条记录,作为函数的参数,得到这条记录对应的单个结果
分类:字符函数、其他函数、转换函数、日期函数、数字函数、三角函数
--查询emp表中名字和名字的长度
select name,length(name) from emp;
- 多行函数:一次性把多条记录当作参数输入给函数,得到多条记录对应的单个结果
select max(sal) from emp;
①字符函数
- 转换小写 用lower
--查询emp表并将名字是‘smith’的转换成小写
select * from emp where lower(ename)='smith';
- 转换大写 用upper
--查询emp表并将名字是‘smith’的转换成大写
select * from emp where ename=upper('smith');
- 转换驼峰式 用initcap
--查询emp表并将名字是‘smith’转换成驼峰式写法
select ename,initcap(ename) from emp where initcap(ename)='Smith';
- 连接字符用concat
concat(x,s1,s2,s3…),和concat一样,只不过每个字符串之间要加x
--concat 只能连接两个字符,而 “||” 可以连接多个字符。
select concat('aa','bb') from test; --得aabb
- 截取字符串 用substr
--截取字符串 用substr
--截取ename从第一个字符到第二个字符(没有第0个)
select ename,substr(ename,1,2) from emp;
- 返回下标位置 用instr
--打印字符出现的位置 instr
--名字中有A的位置(从左下标第1位开始,A在第几位就返回第几位,如果没有A这个字符就会返回的是0)
select ename ,instr(ename,'A') from emp;
- 补充 用lpad,rpad
--补充字符 lpad,rpad
--把sal字段的内容扩展成8位,左边(lpad)不够用*代替,右边(rpad)不够用#代替
select sal ,lpad(sal,8,'*'),rpad(sal,8,'#') from emp;
- 替换 用replace
--替换 replace
--将名字中的有A的找到,将其替换成a,没有的话就不动
select ename.replace(ename,'A','a') from emp;
- ASCII(s) :返回字符串s中第一个字符的ASCII码值
- CHAR_LENGTH(S):返回字符串s的字符数,作用和CHARACTER_LENGTH(S)相同
- length(s):返回字符串s的字节数,和字符集有关
- left(str,n):返回字符串str最左边的n个字符
- right(str,n):返回字符串str最右边的n个字符
- LTRIM(S):去掉字符串s左侧的空格
- RTRIM(S):去掉字符串s右侧的空格
- TRIM(S):去掉字符串s开始与结尾的空格
- TRIM(S1 FROM S):去掉字符串s开始与结尾的s1
- TRIM(LENDING S1 FROM S):去掉s开始处的s1
- TRIM(TRAILING S1 FROM S):去掉s结尾处的s1
- REPEAT(STR,N):返回str重复n次的结果
- SPACE(N):返回n个空格
- STRCMP(s1,s2):比较字符串s1和s2的ASCII码值的大小
- LOCATE(substr,str):返回字符串substr在str字符串中首次出现的位置
- FIELD(S,S1,S2,S3…):返回字符串s在字符串列表中第一次出现的位置
②数值函数
- 四舍五入 用round
--得45.26,45,41
select round(45.2568,2) "小数点后两位",
round(45.2568,0) "个位",
round(45.2568,-1) "十位"
from NUMTable;
- 截取数值,不进行四舍五入 用trunc
select trunc(45.2568,2) "小数点后两位",
trunc(45.2568,0) "个位",
trunc(45.2568,-1) "十位"
from NUMTable;
- 求余数 用mod
select ename,sal,mod(sal,300)
from emp where empno=7369
查询编号为7369的人的工资除以300的余数
| 函数总结 | 用法 |
|---|---|
| ABS(x) | 返回x的绝对值 |
| SIGN(x) | 返回x的符号。正数返回1,负数返回-1,0返回0 |
| PI() | 返回圆周率的值 |
| CEIL(x),CEILING(x) | 返回大于或者等于某个值的最小整数 |
| FLOOR(x) | 返回小于或者等于某个值的最大整数 |
| LEAST(e1,e2,e3…) | 返回列表中的最小值 |
| GREATEST(e1,e2,e3) | 返回列表中的最大值 |
| MOD(x,y) | 返回x除以y后的余数 |
| rand() | 返回0~1的随机值 |
| rand(x) | 返回0~1的随机值,其中x的值用作种子值,相同的x值会产生相同的随机数 |
| round(x) | 返回一个对x的值进行四舍五入后,最接近x的值 |
| round(x,y) | 返回一个对x的值进行四四舍五入后最接近x的值,并保留小数点后面的y位 |
| truncate(x,y) | 返回数字x截断为y位小数的结果 |
| sqrt(x) | 返回x的平方根。当x为负数时,返回null |
三角函数
| 函数 | 用法 |
|---|---|
| sin(x) | 返回x的正弦值,其中,参数x为弧度值 |
| asin(x) | 返回x的反正弦值。如果x值不在-1 到 1 之间,则返回null |
| cos(x) | 返回x的余弦值,其中,参数x为弧度值 |
| acos(x) | 返回x的反余弦值,即获取余弦为x的值;如果x的值不在 -1 到 1 之间,则返回null |
| tan(x) | 返回x的正切值,其中,参数x为正切值 |
| atan(x) | 返回x的反正切值,即返回正切值为x的值 |
| atan2(x,y) | 返回两个参数的反正切值 |
| cot(x) | 返回x的余切值,其中x为弧度值 |
③日期函数
对于日期型的数值可以使用+,-运算符
1.一个日期+- 一个数值(就是+-一个天数),得到一个新的日期2.两个日期型的数据相减,得到的是两者之间相差的天数3.两个日期型的数据不能相加,日期型的数据不能进行乘除运算
- 相减精确日期 用mouths_between
--查询编号,今日,给定日期,相减日期除以365的值;粗糙日期
select empno, sysdate ,birthdate,(sysdate-birthdate)/365 from emp
--查询编号,今日,给定日期,相减日期除以365的值;精确日期,相差多少月
select empno, sysdate ,birthdate,(sysdate-birthdate)/365,mouths_between(sysdate,birthdate) from emp
- 相加精确日期 用add_mouths
select empno ,birthdate "雇佣日期",(birthdate+90) "粗略的转正日期",add_mouths(birthdate,3) "精确的转正日期" from emp;
- 下一个星期 用next_day
select sysdate "当前日期",next_day(sysday,'星期一') 下周星期一 from emp;
- 最后一天 用next_day
--所在月份的最后一天
select ename , birthdate,last_day(birthdate) from emp;
- 最近日子 round
select sysdate 当时日期,round(sysdate) 最近0点日期,round(sysdate,'day') 最近星期日,round(sysdate,'mouth') 最近月初,round(sysdate,'q') 最近季初日期,round(sysdate,'year') 最近年初日期from numTable;
获取10分钟前的日期
select sysdate,sysdate-interval '10' minute from dual;
获取一周前的日期
select sysdate, sysdate - interval '7' day from dual
获取一个月前的日期
select sysdate,sysdate-interval '1' month from dual;
获取一年前的日期
select sysdate,sysdate-interval '1' year from dual;
获取当月的总天数
select to_number(to_char(last_day(sysdate),'dd')) from dual;
获取某一个月的总天数
select to_number(to_char(last_day(to_date('2018-09','yyyy-mm')),'dd')) from dual;
查询某一个月的全部日期
SELECT TO_CHAR(TRUNC(to_date('2018-09','yyyy-MM'), 'MM') + ROWNUM - 1,'yyyy-MM-dd') someday FROM DUALCONNECT BY ROWNUM <= TO_NUMBER(TO_CHAR(LAST_DAY(to_date('2018-09','yyyy-MM')), 'dd'));
- 返回当前日期,只包含年月日
CURDATE(),CURRENT_DATE()
- 返回当前时间,只包含时分秒
CURTIME(),CURRENT_TIME()```
- 返回当前系统日期和时间
NOW()/SYSDATE()/CURRENT_TIMESTAMP()/LOCALTIME()/LOCALTIMESTAMP()
- 返回UTC(世界标准时间)日期
UTC_DATE()
- 返回UTC(世界标准时间)时间
UTC_TIME()
- 时间和时间戳的转换
SELECT UNIX_TIMESTAMP(‘2021-10-01 12:12:32’),FROM_UNIXTIME(1635173853) FORM DUAL;
- YEAR()返回年,MONTH()返回月,DAY()返回日,HOUR()返回时,MINUTE()返回分,SECOND()返回秒
- 返回月份,July
MONTHNAME(DATE)
- 返回星期几:MONDAY
DAYNAME(DATE)
- 返回周几:注意周1是0
WEEKDAY(DATE)
- 返回日期对应的季度,范围为1~4
QUARTER(date)
- 返回一年中的第几周
WEEK(DATE),WEEKOFYEAR(DATE)
- 返回日期是一年中的第几天
DAYOFYEAR(DATE)
- 返回日期位于所在月份的第几天
DAYOFMONTH(DATE)
- 返回time1减去time2的时间,当time2为数字时,代表为秒,可以为负数
SUBTIME(time1,time2)
- 返回date1-date2的日期间隔天数
DATEDIFF(date1-date2)
- 返回time1-time2的时间间隔
TIMEDIFF(time,time2)
- 返回0000年1月1日起,n天以后的日期
FROM_DAYS(N)
- 返回日期date距离0000年1月1日的天数
TO_DAY(date)
- 返回date所在月份的最后一天的日期
LAST_DAY (date)
- 将给定的小时、分钟和秒组合成时间并返回
MARKTIME(hour,minute,second)
- 返回time加上n后的时间
PERIOD_ADD(TIME,N)
④转换函数
转换有两种方式:隐式转换,手动转换
- 数值转字符——to_char( )
--要查日期,而这个日期是字符串,所以要将日期转化成字符串
select empno,ename from emp where birthdate = '2020-02-03';
--转换
select empno,ename from emp where to_char(birthdate,'YYYY-MM-DD') = '2020-02-03';--数值转换成字符
select sal, to_char(sal,'$999,999.00'),to_char(sal,'L000,000.00') from emo where id='5'
/*
9:代表一个数字(有数字就显示,没有就不显示)0:强制显示0$:放置一个$符L:放置一个本地货币符. :(点)显示小数点,:(逗号)显示千位指示符
*/
- 字符转日期——to_date( )
select * from emp where birthdate=to_date('1999-12-25','YYYY-MM-DD');- 字符转数值——to_number( )
--字符的格式和模板的格式必须要一致,相当于都必须用¥ 或者 $
select to_number('$800,00','$999,99.00') from numTable;
- 日期转字符——to_char( )
--日期转字符串
select sysdate,to_char(sysdate,'YYYY-MM-DD HH24:MI:SS AM DAY') from numTable;⑤其他函数
- nvl(字段,返回的值);
若是null就设置成0
#模糊查询在mybatis中
select nvl(x.ZHS,0) zhs from xq x
where
<if test="name!= null and name!= ''">x.name like concat(#{name},'%')
</if>select ename,nvl(gongzuo,'还没有找到工作') from user;
- nvl2(字段,不是空返回的值,是空返回的值)
--查询id为5的人如果不是null则返回job,如果式null返回‘没工作’
select nvl2(job,job,'没工作') from user where id=5
-
NULLIF(值1,值2);比较两个表达式,如果相等返回空值,如果不等返回第一个表达式
--举例,第一个相等返回空值,第二个不相等,返回第一个 select ename,eaddre, nullif(length(ename),length(ename)) num1,nullif(length(ename),length(eaddre)) num2 from emp; -
CASE实现 if…else if…else的功能
select ename,job,sal,case jobwhen '经理' then0.90 * salwhen '主管' then0.80 * salwhen '队长' then0.50 * salelse '员工' 0.30 * salend as '工资捐赠数'
from emp where ename='小明';例2:(case QYLX when '地质灾害高易发区' then 1when '地质灾害中易发区' then 2when '地质灾害低易发区' then 3when '地质灾害不易发区' then 4 end ) as NUM
- DECODE 实现if…else if…else的功能
eg1:
select ename,job,sal,decode(job'经理',0.90 * sal,'主管' ,0.80 * sal,'队长',0.50 * sal,0.30 * sal) as '工资捐赠数'
from emp where ename='小明';
eg2:
decode(X,A,B,C,D,E)
//这个函数运行的结果是,当X = A,函数返回B;
//当X != A 且 X = C,函数返回D;
//当X != A 且 X != C,函数返回E。
//其中,X、A、B、C、D、E都可以是表达式,这个函数使得某些sql语句简单了许多
- is not null不为空,is null是空
筛选不为空的值
select y.name, nvl(y.age,0) age ,nvl(y.score,0) score,y.nf
from user y
where y.name='xiaoming' is not null
and y.nf is not null;--不在20-30之间
not between 20 and 30
NULL值与空值区别
空值长度为0,不占空间,NULL值得长度为null,占用空间is null无法判断空值空值使用"=“或者”<>"来处理(!=)count()计算时,NULL会忽略,空值会加入计算注:NULL是占用内存空间的,而空值则不占用内存空间
- Extract()函数
--截取年份从PZRQ表的字段中extract(year from rqDate) as NF--截取月份从PZRQ表的字段中extract(month from rqDate) as NF--截取日期从PZRQ表的字段中extract(day from rqDate) as NF
用于截取年、月、日、时、分、秒
⑥嵌套函数
要想嵌套,必须使用嵌套函数;
-
分组函数
max( ),min( ),avg( ),sum( ),count( )
avg,sum只能针对数值型的数据
max,min,count可以针对任何类型的数据
--求名字的最大值A为最小值,Z为最大值
select max(ename) Z,min(ename) A from emp;
count有两种用法
1.count( * ) 查询数据的总条数
2.count( 字段 ) ,这种情况下忽略空值
select count(*) from emp;
select count(comm) from emp;
- Having
eg:求出各部门中平均工资大于6000的部门,以及其平均工资
select id,avg(salary)salary
from username
having avg(salary)>6000
group by id;
--having avg(salary)>6000,也可以发在后面
-
组函数
- 对数据进行分组后,使用组函数
- 出现在查询列表中的字段,要么出现在组函数中,要么出现在group by子句中
- 也可以只出现在group by中
--根据部门分组,查询工资 select max(sal) from emp group by bumenId;--根据部门分组,查询工资和部门 select bumenId,max(sal) from emp group by bumenId;--按照多个字段进行分组;部门和工作分组 select bumenId,job,max(sal) from emp group by bumenId,job order by bumenId--查询部门分组后,并且部门编号不为空的工资最大值 的最大值 select max(max(sal)) from emp where bumenId is not null group by bumenId; - 对数据进行分组后,使用组函数
-
分组聚合函数
row number() over partition by
分组聚合:就是先分组再排序,可以的话顺手标个排名;如果不想分组也可以排名;如果不想分组同时再去重排名也可以。
--按salary排序,rank给排个名
SELECT *, Row_Number() OVER (partition by deptid ORDER BY salary desc) rank FROM employee
·八、SQL注入攻击 admin’ or ‘x’='x
- 运算顺序 not ,and, or
状况:select * from users where name='admin' or 'x'='x' and password = 'xxxxxxx';
--上面情况会被攻击,以下解决
解决:select * from users where name='admin' or ('x'='x' and password = 'xxxxxxx');
·九、GROUP BY、order by
分组,对哪个字段分组必须也要加上查询这个字段;
排序,排序+字段+排序方式,asc升序,desc降序
select t.nf ,sum(score) score
from user t
WHERE t.name='语文'
and t.NF is not null GROUP BY t.NF
order by t.nf asc
·十、索引
主键索引
primary key
不能为空索引
not null unique
默认索引
default '默认的值';/*!注意要用单引号*/
创建索引,由两种方式
- 1.自动创建:oracle会自动为主键和唯一键创建索引
自动创建的索引是无法手动删除的,但是在删除主键约束,唯一约束的时候,对应的索引会被自动删除
--添加名字为ename_uni的唯一索引
alter table emp
add constraints ename_uni unique (ename);
--删除名字为ename_uni的索引
alter table emp
drop constraints ename_uni;
- 2.可以手动的创建约束,表中什么样的字段应该添加索引,
-----在查询的时候,经常被用来作为查询添加的字段,应该添加索引
创建索引
-- 给表emp的字段ename创建名为ename_index的索引
create index ename_index on emp(ename);
删除索引
--删除名为indexName的索引
drop index indexName;
查看索引
select index_name, table_name, column_name from user_ind_columns where table_name='tableName' ;
查询索引是否生效:前面加explain
explain select s.* from stu s where name = '小强';
·十一、视图
视图介绍
- 视图是一种虚表
- 视图建立在已有表的基础上,视图赖以建立的这些表称为基表
- 可以将视图理解为存储起来的select语句
- 视图向用户提供基表数据的另一种方式
创建视图
create view Hr_view as select empno,ename,job,mgr,deptno from emp;
--创建物化视图
create materialized view Hr_viewrefresh force on demand
as select empno,ename,job,mgr,deptno from emp
--可以加只读
with read only;
视图重置
--创建视图,如果没视图则创建,如果有则重置
create or replace view Hr_view as select empno,ename,job,mgr,deptno from emp;
--起别名
create or replace view Hr_view (员工编号,员工姓名,薪水,佣金) as select empno,ename,sal,comn from emp;
删除视图
--删除视图,不会影响原来的数据
drop view users;
插入视图
视图就是一个(虚)表,我们可以对表插入数据,也可以对视图插入数据
--将工资大于2000的做一个视图表
create or replace view Emp_num as select * from emp where sal>2000;
--对视图插入数据,数据会被插入到源表中
insert into Emp_num values (8000,'刘','软件工程师',005);
--创建只读的视图,不能执行DML操作
create or replace view Emp_num as select * from emp where sal>2000 with read only;
行内视图
就是出现在from后面的子查询,也就是一个视图,但是该视图没有命名,不会在数据库中保存
--查询工资最大的三个员工;rownum是适用于<=的情况,是按照插入的顺序给记录排号
select rownum,E.* from (select * from emp order by sal desc) E where rownum <=3
--如何才可以拿到第二个数据
select * from (select rownum no, id,name,sal,job from emp) where no=2
--可以使用rowid来获取数据的修改权限
select rowid ,e.* from emp e;
拿取表数据做成视图sql
--查询user_after表中将nd转换为字符作为nd,bhnum截取六位作为bhnum,计算(当dlh为‘NC’的时候为DHJ,否则为0,作为NC),
--依次;并对nd,bhnum,dwmc分组;nd,xzqdm排序
selectdistinct to_char(nd) nd,to_char(substr(bhnum,0,6)) as bhnum,dwmc as xzqmc,sum(case when dlh ='NC' THEN DHJ else 0 END ) AS NC,sum(case when dlh ='NM' THEN DHJ else 0 END ) AS NM,sum(case when dlh ='N+' THEN DHJ else 0 END ) AS NZJ,sum(case when dlh ='N-' THEN DHJ else 0 END ) AS NJS
from user_after
group by to_char(nd),to_char(substr(bhnum,0,6)),dwmc
order by nd,xzqdm;
·十二、多表查询
· 非等值查询
两个表之间没有父子关系,用 != 来链接两个表
--查询两张表,emp表的id,名字,工资,saldengji表的等级,低值,高值;emp表某人的工资在saldengji表中的工资等级和范围
select e.empId,e.ename,e.esal,s.grade,s.losal,s.hisal
from emp e,saldengji s where e.esal between s.losal and s.hisal;
· 自查询(自连接)
通过别名,将一个表虚拟成两个表,然后在这两个表上做等值查询
select e.empId,e.name,m.bumenId,m.ename
from emp e,emp m where e.empId = m.bumenId
· 外连接
在等值查询的基础之上 ,可以查询不满足等值条件的数据;
**左外连接**:可以把右边不满足等值条件的数据查询出来 left join
**右外连接**:可以把左边表不满足等值条件的数据查出来 right join
SQL92语法实现外连接,使用 + ——MySQL不支持SQL92语法中外连接
- 左外连接
//第一种方式
select t.tbbh,w.xmwz
from tdgy t,wpxg w
where t.objectid = w.objectid(+);
//第二种方式
select t.tbbh,w.xmwz
from tdgy t
left join wpxg w on t.objectid = w.objectid
- 右外连接
//第一种方式
select t.tbbh,w.xmwz
from tdgy t,wpxg w
where t.objectid(+) = w.objectid;
//第二种方式
select t.tbbh,w.xmwz
from tdgy t
right join wpxg w on t.objectid = w.objectid
满外连接
select t.tbbh,w.xmwz
from tdgy t
full outer join wpxg w on t.objectid = w.objectid
· 交叉连接
新标准:就相当于老标准等值查询的时候没有给出争取的等值条件,会产生笛卡尔效应
select e.*,d.* from emp e cross join dept d;
· 自然连接natural join
-
在父子表关系上,自动的匹配两个表中列名完整相同的字段(称为参照列),在这些相同名称的字段上做等值查询
-
参照列上不能使用前缀
-
自然连接的缺陷:1.会把所有的参照列都作为等值条件;2.如果参照列的类型不同,查询会报错;
-
当两个表中没有参照列的时候,自然查询会产生笛卡尔乘积
select u.name,u.age,r.addre from user1 u natural join user2 r;
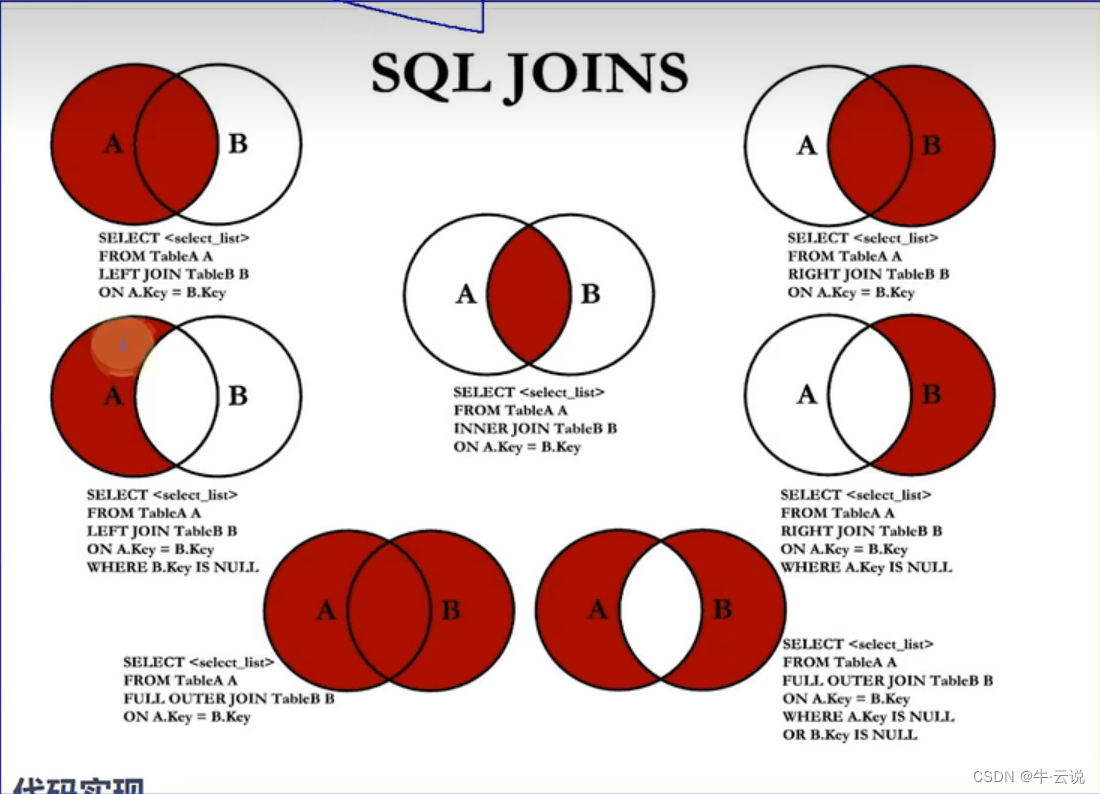
· join …using
对自然连接的改造
在自然连接的基础上,加以连接,使用指定的参照列来作为等值条件;
--using(指定的参照列)
select u.name,u.id,addre,r.name from user u natural join user1 r using(addre) where u.id=5;
· 合并表查询
并集:union和union all
**union,去除重复**eg:select adName,id,age,sorce,addre from aSchoolunion select adName,id,age,sorce,addre from bSchool;若两张表有重复会去除一个**union all,不去重复(推荐)**
eg:select adName,id,age,sorce,addre from aSchoolunion allselect adName,id,age,sorce,addre from bSchool;若两张表有重复不会去除字段名字必须一致

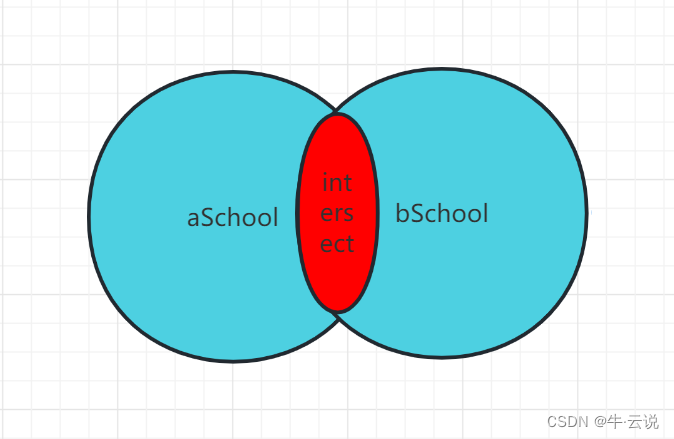
交集:intersect
--取出两张表共同的内容
select adName,id,age,sorce,addre from aSchool
intersect
select adName,id,age,sorce,addre from bSchool;
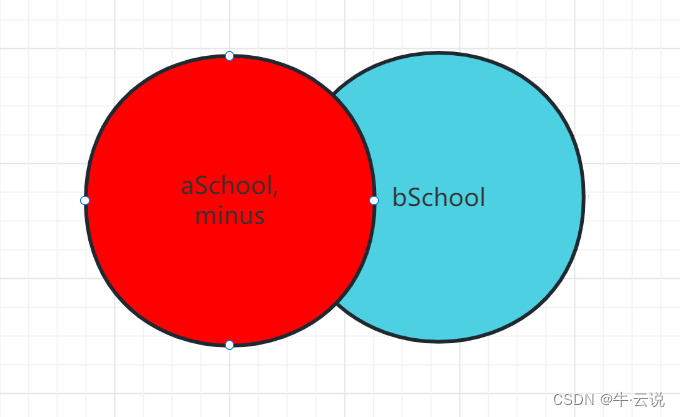
差集:minus
--取出aSchool的内容以及和bSchool中相同的内容,反之select adName,id,age,sorce,addre from aSchool
minus
select adName,id,age,sorce,addre from bSchool;
· 子查询
-
子查询没有结果,主查询也不会报错,就是没有查询结果而已
-
多行单列子查询,要使用多行比较运算符,IN,ANY,ALL
1》使用IN运算符
--查询表中工资大于3000的数据 select job, fromm, emp, where sal>3000; --使用 in;查询emp表工资大于3000工资的数据(当查询另一张表中的员工工资,存在和本张表工资大于3000的工资一样的员工的数据时比较方便) select e.empId,e.ename,e.job,e.sal from emp e where e.job in (select job fromm emp where sal>3000);2》使用ALL运算符
--查询表中大于id为5的部门的工资数据,如果是<号:则小于满足子查询条件的所有数据的最小值,如果是>号:则大于满足子查询条件的所有数据的最大值 select e.* from emp e where e.sal > ALL(select sal from emp where empId=5);3》使用ANY运算符
--查询工资数据大于某个部门编号为20的工资;如果是<号,则小于满足子查询条件的所有数据的最大值;如果是>号,则大于满足子查询条件的所有数据的最小值 select e.* from emp e where e.sal < any(select sal from emp where empid=20);4》多行多列子查询
可以使用in比较运算符
--查询部门编号为5和8的addre,job的数据
select ename,job from emp where empid = 5 or ompid = 8; --成对的比较
--注:查询表中的数据addre,job和部门编号为5和8的addre,job一样的数据,不包括自己
select empid,ename,addre,job from emp
where (addre,job) in (select ename,job from emp where empid = 5 or ompid = 8) and empid != 5 and empid != 8;--非成对的比较,把多行多列的子查询拆分成两个多行单列的子查询,分别使用in运算符
select empid,ename,addre,job from emp
where addre in (select addre from emp where empid = 5 or ompid = 8)
and job in(select job from emp where empid = 5 or ompid = 8)
and empid != 5 and empid != 8;
锁表,解锁
锁表!
select * from user for update;
--锁表(其它事务不能读、更新、删除)
BEGIN TRAN
SELECT * FROM <表名> WITH(TABLOCKX);
WAITFOR delay '00:00:20'
COMMIT TRAN--锁表(其它事务只能读,不能更新、删除)
BEGIN TRAN
SELECT * FROM <表名> WITH(HOLDLOCK);
WAITFOR delay '00:00:20'
COMMIT TRAN--锁部分行
BEGIN TRAN
SELECT * FROM <表名> WITH(XLOCK) WHERE ID IN ('81A2EDF9-D1FD-4037-A17B-1369FD3B169B');
WAITFOR delay '00:01:20'
COMMIT TRAN--查看被锁表
select request_session_id 锁表进程,OBJECT_NAME(resource_associated_entity_id) 被锁表名
from sys.dm_tran_locks where resource_type='OBJECT';--解锁
declare @spid int
Set @spid = 55 --锁表进程
declare @sql varchar(1000)
set @sql='kill '+cast(@spid as varchar)
exec(@sql)·十三、约束
·唯一约束unique
保证该字段的数据不能重复,或字段组合不能重复,但是可以为null
--创建表的时候使用
firstName varchar2(10),
LastName varchar2(10),
//取一个名字叫name_uni的唯一约束
constraints name_uni unique (firstName,LastName)·主键约束primary key
非空且唯一,一个表中只能有一个主键约束(只能写一个);但可以同时可以作用在多个字段上,也被称为联合主键
--创建表
sid number(4),
sname varchar2(20),
constraints T_STU primary key (sid)--给sid加主键约束
- 添加主键约束
alter table myUser add constraint myUser_key primary key (userId); --alter table 表 add constraint 主键名 主键类型(主键字段)
#### ·外键约束外键约束可以重复,可以为null;- 添加外键约束```sql
alter table cTable add foreign key(cUserId) references zTable(userId)
--alter table 从表 add foreign key(外键字段) references 主表(主键字段)
- 删除外键约束
alter table myUser drop foreign key cUserId
--alter table 表名 drop foreign key 外键名
序列
- 用来维护数据库的主键数据
- 自动提供唯一的数值
- 共享对象
- 将序列值装入内存可以提高访问效率
创建序列
--创建序列,名字为seq_stu
create sequence seq_stu
INCREMENT BY: --指定序列号之间的间隔,该值可为正的或负的整数,但不可为0。序列为升序。忽略该子句时,缺省值为1。
START WITH:--指定生成的第一个序列号。在升序时,序列可从比最小值大的值开始,缺省值为序列的最小值。对于降序,序列可由比最大值小的值开始,缺省值为序列的最大值。
MAXVALUE:--指定序列可生成的最大值。
NOMAXVALUE:--为升序指定最大值为1027,为降序指定最大值为-1。
MINVALUE:--指定序列的最小值。
NOMINVALUE:--为升序指定最小值为1。为降序指定最小值为-1026。
cycle --需要循环
nocache --不需要缓存登录-- 创建序列 Student_stuId_Seq --create sequence Student_stuId_Seqincrement by 1start with 1minvalue 1maxvalue 999999999;
修改序列
-- 更改序列 Student_stuId_Seq--alter sequence Student_stuId_Seqincrement by 2 minvalue 1maxvalue 999999999;
查询使用序列
--查询序列下一个值
select Student_stuId_Seq.Nextval 自增序列ID from dual;
--查询序列当前值
select Student_stuId_Seq.currval from dual;
新增使用序列
--给表student新增数据,seq_stu.nextval可以自动添加id值insert into Student(stuId,Stuname) values(Student_stuId_Seq.Nextval,'张三');insert into Student(stuId,Stuname) values(Student_stuId_Seq.Nextval,'李四');
删除序列
drop sequence Student_stuId_Seq;
其他
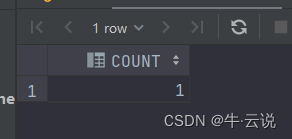
sql判断表是否存在
1.第一种方式
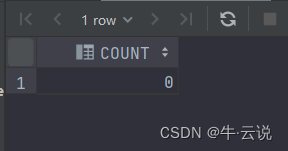
select count(*) as count from user_tables where table_name =upper('tableName');
查询结果
2.第二种方式
SELECT COUNT(*) as count FROM ALL_TABLES WHERE OWNER = UPPER('用户名') AND TABLE_NAME = UPPER('表名')
查询结果
plsql中创建表空间(模式)
-- 创建表空间
create tablespace TS_RAW_XZloggingdatafile 'D:\oradata\6400NXdata\TS_RAW_XZ.dbf' --保存的文件size 16384m --大小autoextend on next 32m maxsize unlimitedextent management local;
-- Create the user
--创建用户
create user US_RAW_XZidentified by "US_RAW_XZ"default tablespace TS_RAW_XZtemporary tablespace TEMPprofile DEFAULTquota unlimited on TS_RAW_XZ;
-- Grant/Revoke role privileges
grant connect to US_RAW_XZ with admin option;
grant dba to US_RAW_XZ with admin option;
grant resource to US_RAW_XZ with admin option;
-- Grant/Revoke system privileges
grant unlimited tablespace to US_RAW_XZ with admin option;
希望可以帮助到您
~感谢您的光临~
这篇关于Oracle 知识精要汇总的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









