本文主要是介绍打好Pandas与Matplotlib组合拳,玩转数据分析与可视化,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
打好Pandas与Matplotlib组合拳,玩转数据分析与可视化
一、获取数据源
前一篇公众号文章爬取了哔哩哔哩“每周必看”栏目的 252 期视频,获取收录的 8697 条视频名称、视频封面、up 主、播放量、弹幕量、点赞投币量等信息,保存到 excel 表格。
参考:Python实战:爬取哔哩哔哩网站“每周必看”栏目

本期,我将使用 pandas 库进行数据分析,通过 matplotlib 库实现数据可视化。
excel 表格数据源可在“程序员coding”公众号,后台回复“每周必看”获取。
二、查看数据
1、df.shape
df.shape 是一个 pandas 数据帧(DataFrame)的属性,执行 df.shape,会返回一个元组,该元组的第一个元素代表数据帧的行数,第二个元素代表列数。
import pandas as pd# 读取本地Excel文件
df = pd.read_excel('小破站-每周必看-总252期-总计8697条.xlsx')# 查看形状,几行几列
print(df.shape)

2、挑选列
由于列数有 66 列太多,我将挑选下面几列关键数据做分析。
| 列名 | 含义 |
|---|---|
| num | 第几期集合 |
| title | 标题 |
| owner.name | up主 |
| tname | 视频类型 |
| stat.view | 播放量 |
| stat.coin | 投币 |
| stat.like | 点赞 |
| stat.favorite | 收藏 |
| stat.share | 转发 |
import pandas as pd# 读取本地Excel文件
file_path = '小破站-每周必看-总252期-总计8697条.xlsx'
columns = ["num", "title", "owner.name", "tname", "stat.view", "stat.coin", "stat.like", "stat.favorite", "stat.share"]
df = pd.read_excel(file_path, usecols=columns)# 查看形状,几行几列
print(df.shape)

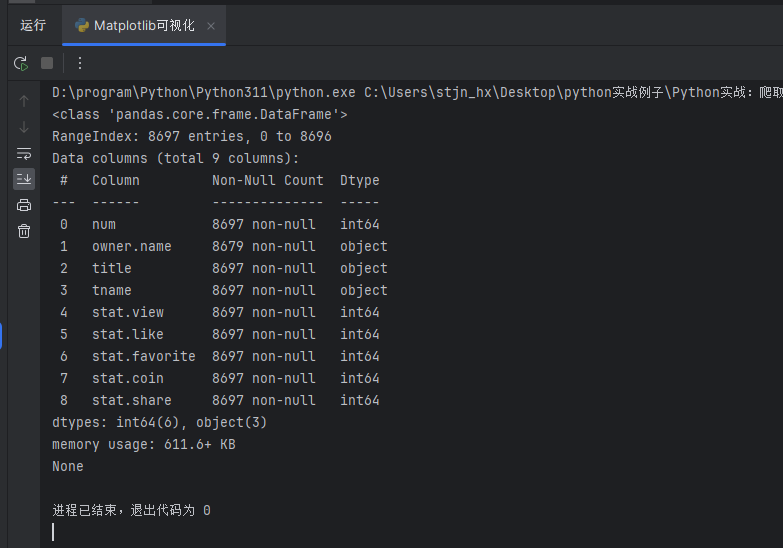
3、df.info()
df.info()可以获得 DataFrame 的简明摘要,包括每列中非空值的数量、每列的数据类型以及 DataFrame 的内存使用情况。
# 查看列信息
print(df.info())
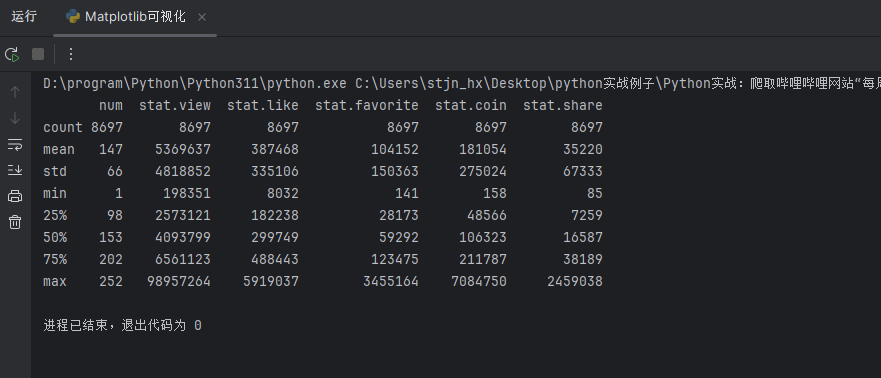
4、df.describe()
df.describe()方法用于生成 DataFrame 的各种特征的汇总统计信息。它返回一个新的 DataFrame,其中包含原始 DataFrame 中每个数值列的计数、平均值、标准差、最小值、第 25 百分位、中位数、第 75 百分位和最大值。
在 pandas 中,当数据帧(DataFrame)中的某一列包含非常大的整数时,pandas 会自动将该列的显示格式设置为科学计数法。可以使用 pandas 的 pd.set_option() 函数来设置显示选项,以普通整数形式显示这些值。
import pandas as pd# Pycharm输出窗口有省略号,数据显示不全解决方法
pd.set_option('display.max_rows', 500)
pd.set_option('display.max_columns', 100)
pd.set_option('display.width', 1000)# 设置 pandas 显示选项,以普通整数形式显示大整数
pd.set_option('display.float_format', lambda x: '%.0f' % x)# 读取本地Excel文件
file_path = '小破站-每周必看-总252期-总计8697条.xlsx'
columns = ["num", "title", "owner.name", "tname", "stat.view", "stat.coin", "stat.like", "stat.favorite", "stat.share"]
df = pd.read_excel(file_path, usecols=columns)# 数据分析
print(df.describe())
三、matplotlib库
Matplotlib 是 Python 中类似 MATLAB 的绘图工具。Matplotlib 只需几行代码就可以生成图表、直方图、条形图、功率谱、误差图、散点图等。还可以控制线型、字体、轴属性等。
1、安装
pip install matplotlib
2、入门案例
-
导入所需的库:
numpy和matplotlib.pyplot。 -
创建一个 NumPy 数组
x,包含从 1 到 10 的整数。 -
定义线性回归线的方程:y = 2x + 5。将其表示为一个 NumPy 数组
y。 -
设置图表的标题、x 轴标签、y 轴标签。
-
使用
plt.plot()函数绘制线性回归线。 -
使用
plt.show()函数显示图表。代码如下:
import numpy as np
from matplotlib import pyplot as plt x = np.arange(1,11)
y = 2 * x + 5
plt.title("Matplotlib demo")
plt.xlabel("x axis caption")
plt.ylabel("y axis caption")
plt.plot(x,y)
plt.show()
生成的图表如下:

四、视频数据分析
1、每期收录视频曲线
excel 表格包含 8697 条视频数据,”num“列表示第几期集合。
对”num“列数据分析,查看每一期收录视频数量,并通过 matplotlib 生成折线图,查看每期收录视频曲线。
代码如下:
import pandas as pd
import matplotlib.pyplot as plt# 读取本地Excel文件
file_path = '小破站-每周必看-总252期-总计8697条.xlsx'
columns = ["num", "title", "owner.name", "tname", "stat.view", "stat.coin", "stat.like", "stat.favorite", "stat.share"]
df = pd.read_excel(file_path, usecols=columns)# 分析num列每个值出现的次数
value_counts = df['num'].value_counts().sort_index()# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False# 生成折线图
plt.plot(value_counts.index, value_counts.values)
plt.xlabel('期数')
plt.ylabel('收录视频数量')
plt.title('每期收录视频数量曲线')
plt.show()
生成的折线图如下,可以看出相较于早期,后期合集收录的视频开始增多:

2、显示标注
在折线图上增加标注最大值、最小值和平均值。代码如下:
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np# 读取本地Excel文件
file_path = '小破站-每周必看-总252期-总计8697条.xlsx'
columns = ["num", "title", "owner.name", "tname", "stat.view", "stat.coin", "stat.like", "stat.favorite", "stat.share"]
df = pd.read_excel(file_path, usecols=columns)# 分析 "num" 列中每个值出现的次数
value_counts = df['num'].value_counts().sort_index()# 查找最大值和位置
max_value = np.amax(value_counts.values)
max_positions = np.argwhere(value_counts.values == max_value)
# 查找最小值和位置
min_value = np.amin(value_counts.values)
min_position = np.argmin(value_counts.values)
# 查找平均值
avg_value = np.mean(value_counts.values)# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False# 生成折线图
plt.plot(value_counts.index, value_counts.values)
plt.xlabel('期数')
plt.ylabel('收录视频数量')
plt.title('每期收录视频数量曲线')for max_position in max_positions:# 添加 y 轴最大值、最小值和平均值的标注plt.annotate(f'最多视频数量: {max_value}', xy=(max_position, max_value), xytext=(10, 10),textcoords='offset points',arrowprops=dict(arrowstyle='->'))plt.annotate(f'最少视频数量: {min_value}', xy=(min_position, min_value), xytext=(20, 0),textcoords='offset points',arrowprops=dict(arrowstyle='->'))plt.annotate(f'平均视频数量: {avg_value:.2f}', xy=(1, avg_value), xytext=(20, 0), textcoords='offset points',arrowprops=dict(arrowstyle='->'))plt.show()
生成带有标注的折线图如下,所有合集中,最少收录视频 10 个,最多收录视频 51 个,平均每期收录视频 34 个。

3、top20 up
查看被收录视频数量前 20 的 up 主。代码如下:
import pandas as pd
import matplotlib.pyplot as plt# 读取本地Excel文件
file_path = '小破站-每周必看-总252期-总计8697条.xlsx'
columns = ["num", "title", "owner.name", "tname", "stat.view", "stat.coin", "stat.like", "stat.favorite", "stat.share"]
df = pd.read_excel(file_path, usecols=columns)# 计算owner.name列出现次数
name_count = df['owner.name'].value_counts()# 获取出现次数最多的前20个
top_20_names = name_count.head(20)# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False# 创建条形图
plt.barh(top_20_names.index, top_20_names.values)# 添加标题和轴标签
plt.title('被收录视频前20名up主')
plt.xlabel('被收录次数')
plt.ylabel('up主名字')# 设置y轴降序排列
plt.gca().invert_yaxis()# 在条形图右边显示次数数字
for i, (name, count) in enumerate(top_20_names.items()):plt.text(count + 1, i, str(count), fontweight='bold', fontsize=12)# 显示图片
plt.show()
生成的条形图如下,可以看出老番茄、凉风Kaze、盗月社食遇记等up被收录视频排行前三,top20中还有罗翔说刑法、木鱼水心、硬核的半佛老师、我是郭杰瑞等知名up主。

4、top20 视频类型
类似的,还可以分析被收录视频前 20 名视频类型。代码如下:
import pandas as pd
import matplotlib.pyplot as plt# 读取本地Excel文件
file_path = '小破站-每周必看-总252期-总计8697条.xlsx'
columns = ["num", "title", "owner.name", "tname", "stat.view", "stat.coin", "stat.like", "stat.favorite", "stat.share"]
df = pd.read_excel(file_path, usecols=columns)# 计算tname列出现次数
name_count = df['tname'].value_counts()# 获取出现次数最多的前20个
top_20_names = name_count.head(20)# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False# 创建条形图
plt.barh(top_20_names.index, top_20_names.values)# 添加标题和轴标签
plt.title('被收录视频前20名视频类型')
plt.xlabel('被收录次数')
plt.ylabel('视频类型')# 设置y轴降序排列
plt.gca().invert_yaxis()# 在条形图右边显示次数数字
for i, (name, count) in enumerate(top_20_names.items()):plt.text(count + 1, i, str(count), fontweight='bold', fontsize=12)# 显示图片
plt.show()
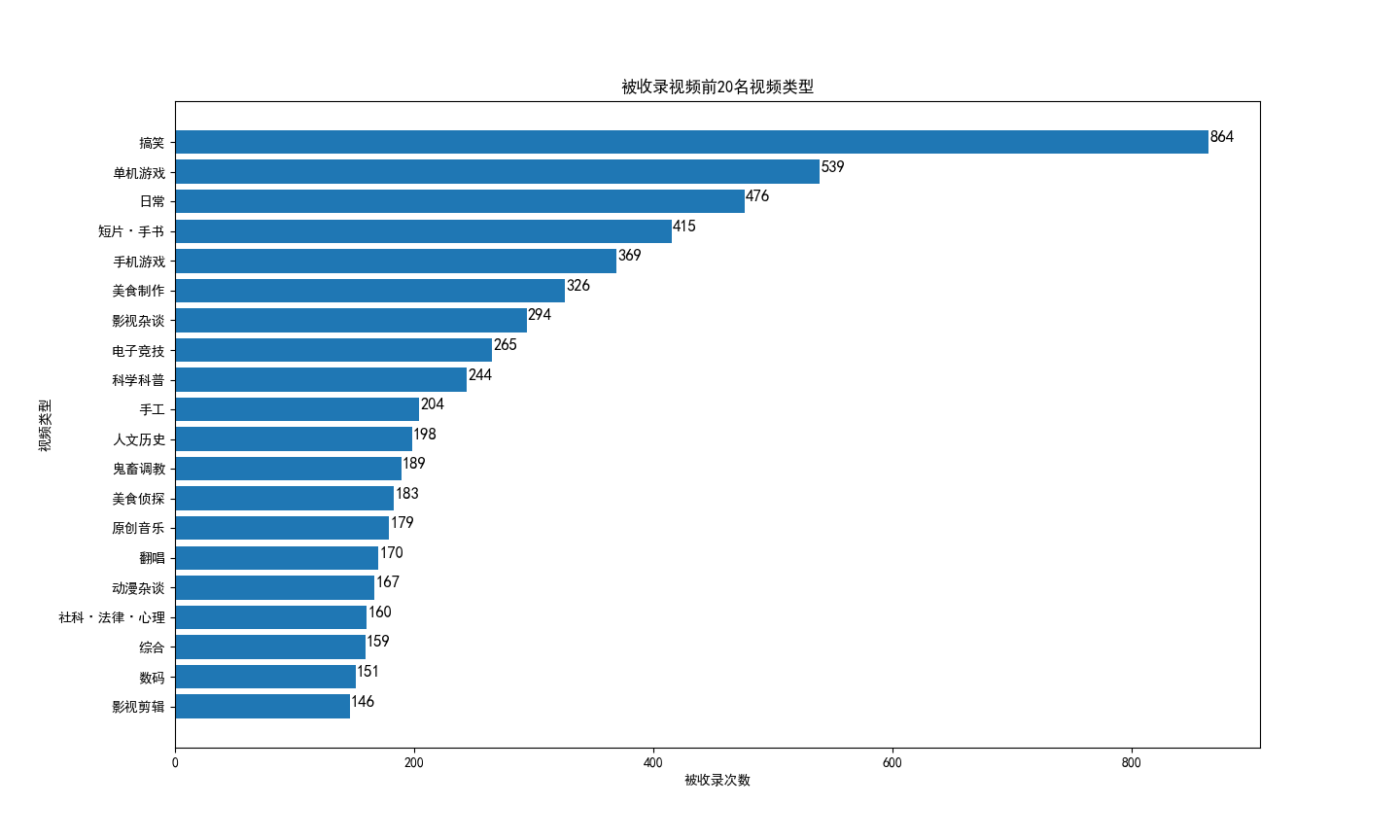
生成的条形图如下,搞笑、游戏、美食、影视、鬼畜等类型视频被收录较多:
5、top20 视频类型-饼图
import pandas as pd
import matplotlib.pyplot as plt# 读取本地Excel文件
file_path = '小破站-每周必看-总252期-总计8697条.xlsx'
columns = ["num", "title", "owner.name", "tname", "stat.view", "stat.coin", "stat.like", "stat.favorite", "stat.share"]
df = pd.read_excel(file_path, usecols=columns)# 计算每个视频类型的播放量总和
grouped = df.groupby("tname")["stat.view"].sum()# 对播放量总和进行降序排序
sorted_grouped = grouped.sort_values(ascending=False)# 获取前20个视频类型
top20_tname = sorted_grouped.index[:20]
top20_views = sorted_grouped.values[:20]# 计算播放量占比
total_views = sum(top20_views)
view_percentages = [view / total_views * 100 for view in top20_views]# 设置 explode 参数以强调占比最大的扇形
max_percentage_index = view_percentages.index(max(view_percentages))
explode = [0.1 if i == max_percentage_index else 0 for i in range(len(top20_tname))]# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False# 绘制饼图
plt.figure(figsize=(10, 6))
plt.pie(top20_views, labels=top20_tname, autopct="%.1f%%", explode=explode)
plt.title("收录视频类型top20")
plt.show()
上面这段代码计算了每个类型视频的播放量总和,并按播放量降序排序。然后绘制一个饼图,显示前 20 个视频类型的播放量占比,并通过设置参数 explode 强调占比最大的扇形。
生成的饼图如下,强调占比最大的扇形:

6、top20 播放
播放量前 20 的视频标题:
import pandas as pd
import matplotlib.pyplot as plt# 读取本地Excel文件
file_path = '小破站-每周必看-总252期-总计8697条.xlsx'
columns = ["num", "title", "owner.name", "tname", "stat.view", "stat.coin", "stat.like", "stat.favorite", "stat.share"]
df = pd.read_excel(file_path, usecols=columns)# 分析播放量前20的视频
top_20 = df.nlargest(20, 'stat.view')# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False# 创建条形图
plt.figure(figsize=(10, 5))
plt.barh(top_20['title'], top_20['stat.view'])
plt.xlabel('播放量')
plt.ylabel('视频标题')
plt.title('播放量前20的视频')# 设置y轴降序排列
plt.gca().invert_yaxis()# 解决保存图时y坐标视频标题显示不全
plt.tight_layout()# 设置x轴显示范围
x_min = 0
x_max = top_20['stat.view'].max() * 1.1 # 将最大值乘以1.1以便留有一些空间
plt.xlim(x_min, x_max)# # 在条形图右边显示次数数字
# for i, v in enumerate(top_20['stat.view']):
# plt.text(v + 1000, i, str(v), fontweight='bold', color='red')# 在条形图右边显示播放量
for i, v in enumerate(top_20['stat.view']):formatted_view = format(v, ',')plt.text(v + 1000, i, formatted_view, fontweight='bold', color='red')# 显示图表
plt.show()
生成的条形图如下:

哈哈,可以去找这些视频来看看放松一下啦。
7、top20 总播放量up
总播放量前 20 的 up 主:
import pandas as pd
import matplotlib.pyplot as plt# 读取本地Excel文件
file_path = '小破站-每周必看-总252期-总计8697条.xlsx'
columns = ["num", "title", "owner.name", "tname", "stat.view", "stat.coin", "stat.like", "stat.favorite", "stat.share"]
df = pd.read_excel(file_path, usecols=columns)# 对owner.name的播放量stat.view求和
sum_df = df.groupby("owner.name")["stat.view"].sum().reset_index()# 展示播放量stat.view总计前20的名字owner.name
top_20 = sum_df.nlargest(20, "stat.view")# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False# 使用matplotlib生成条形图
plt.figure(figsize=(10, 10))
plt.barh(top_20["owner.name"], top_20["stat.view"])
plt.xlabel("播放量")
plt.ylabel("up主")
plt.title("总播放量前20的up主")# 设置y轴降序排列
plt.gca().invert_yaxis()# 设置x轴显示范围
x_min = 0
x_max = top_20['stat.view'].max() * 1.1 # 将最大值乘以1.1以便留有一些空间
plt.xlim(x_min, x_max)# 在条形图右边显示播放量
for i, v in enumerate(top_20['stat.view']):formatted_view = format(v, ',')plt.text(v + 1000, i, formatted_view, fontweight='bold', color='red')# 显示图片
plt.show()
小潮院长被收录的视频播放量竟被超过16亿次、老番茄被收录的视频播放量竟被超过12亿次,真大佬!太牛了!远超第3名绵羊料理被收录的视频播放量6亿次。

8、一个up主数据
以其中一个 up 主“老番茄”为例,分析特定 up 主被收录视频的播放、投币、点赞、收藏、转发总量。代码如下:
import pandas as pd
import matplotlib.pyplot as plt# 读取本地Excel文件
file_path = '小破站-每周必看-总252期-总计8697条.xlsx'
columns = ["num", "title", "owner.name", "tname", "stat.view", "stat.coin", "stat.like", "stat.favorite", "stat.share"]
df = pd.read_excel(file_path, usecols=columns)# 对owner.name等于“老番茄”的所有stat.view,stat.coin,stat.like,stat.favorite,stat.share求和
data = df[df["owner.name"] == "老番茄"]
sum_data = data[["stat.view", "stat.coin", "stat.like", "stat.favorite", "stat.share"]].sum()# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False# 使用matplotlib生成柱状图
plt.figure(figsize=(10, 10))
plt.barh(sum_data.index, sum_data.values)
plt.xlabel("总量")
plt.ylabel("分项")
plt.title("老番茄被收录视频的播放、投币、点赞、收藏、转发总量")# 设置y轴降序排列
plt.gca().invert_yaxis()# 设置x轴显示范围
x_min = 0
x_max = sum_data.values.max() * 1.1 # 将最大值乘以1.1以便留有一些空间
plt.xlim(x_min, x_max)# 在条形图右边显示播放量
for i, v in enumerate(sum_data.values):formatted_view = format(v, ',')plt.text(v + 1000, i, formatted_view, fontweight='bold', color='red')plt.show()
生成的图表如下,“老番茄”被收录的视频,播放量 12 亿次、投币 5000 万个、点赞 9000 万次、收藏 2000 万次、转发总量 300 万次。谁能换算一下这能值多少 RMB 啊!。

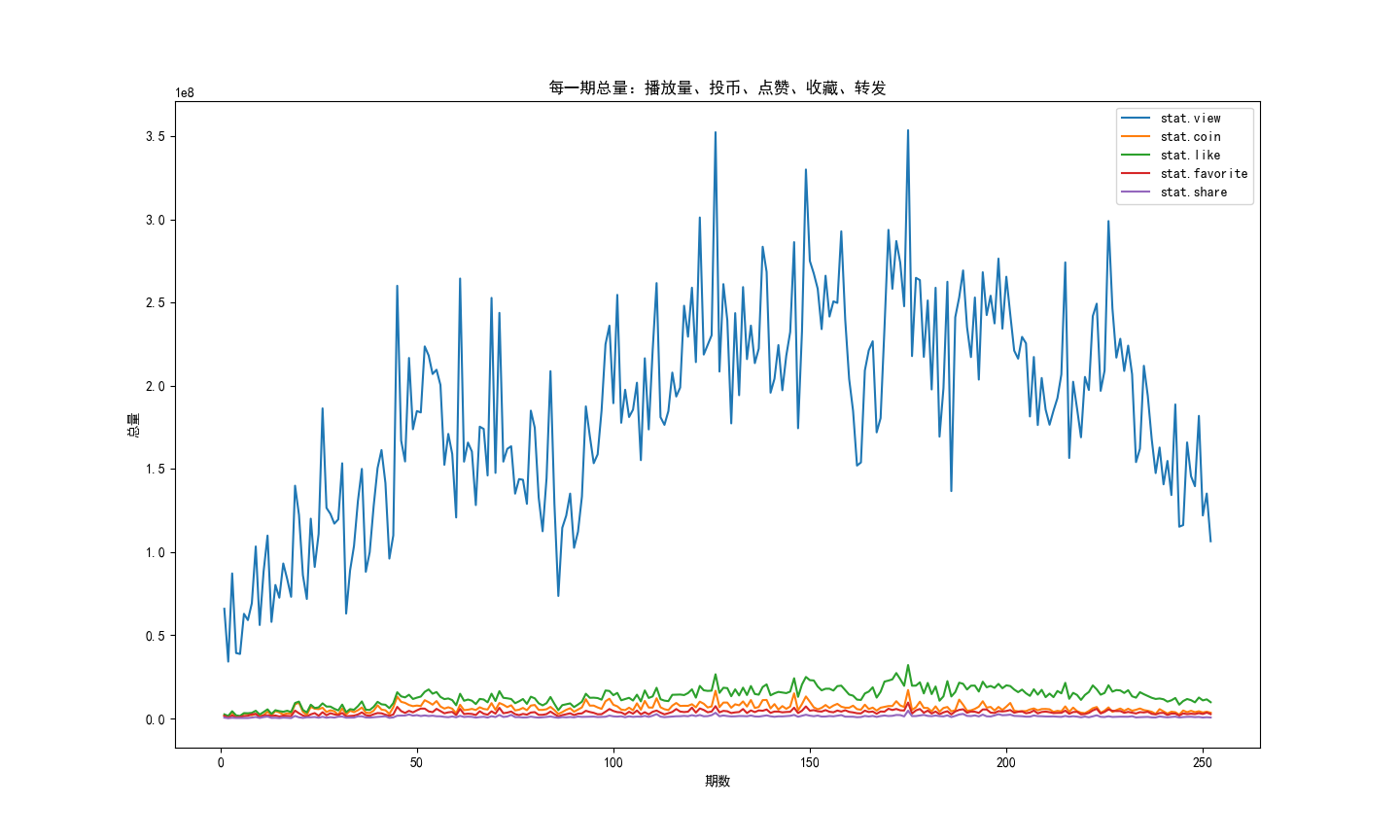
9、252期数据总览
分析每一期集合收录的视频,用播放量、投币、点赞、收藏、转发总量,生成折线图。
import pandas as pd
import matplotlib.pyplot as plt# 读取本地Excel文件
file_path = '小破站-每周必看-总252期-总计8697条.xlsx'
columns = ["num", "title", "owner.name", "tname", "stat.view", "stat.coin", "stat.like", "stat.favorite", "stat.share"]
df = pd.read_excel(file_path, usecols=columns)# 对num的所有stat.view,stat.coin,stat.like,stat.favorite,stat.share求和
sum_data = df[["num", "stat.view", "stat.coin", "stat.like", "stat.favorite", "stat.share"]].groupby("num").sum()# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False# 使用matplotlib生成折线图
plt.figure(figsize=(10, 10))
plt.plot(sum_data.index, sum_data["stat.view"], label="stat.view")
plt.plot(sum_data.index, sum_data["stat.coin"], label="stat.coin")
plt.plot(sum_data.index, sum_data["stat.like"], label="stat.like")
plt.plot(sum_data.index, sum_data["stat.favorite"], label="stat.favorite")
plt.plot(sum_data.index, sum_data["stat.share"], label="stat.share")
plt.xlabel("期数")
plt.ylabel("总量")
plt.title("每一期总量:播放量、投币、点赞、收藏、转发")
plt.legend()plt.show()
五、总结
熟练结合使用 Pandas 和 Matplotlib,可以多维度的进行数据分析与可视化。
使用过 Matlab 基础的话,会发现 Matplotlib 一些命令是相似的。总体来说 Matplotlib 使用起来比较简单,可以快速入门。想要生成比较好看的图还是要花心思进行调教优化,比如设置中文字体、数据标签、y 轴内容过长优化显示等细节,需要逐步完善。
更多的 Matplotlib 高阶用法还在尝试,放在未来再另起一篇继续写。
本文首发在“程序员coding”公众号,欢迎关注与我一起交流学习。
这篇关于打好Pandas与Matplotlib组合拳,玩转数据分析与可视化的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






