本文主要是介绍Zookeeper分布式一致性协议ZAB,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1、分布式一致性协议ZAB详解
Zookeeper Atomic Broadcast(Zookeeper 原子广播协议)。ZAB 协议是为分布式协调服务 Zookeeper 专门设计的一种支持 崩溃恢复 和 原子广播 的协议。整个 Zookeeper 就是在这两个模式之间切换。 简而言之,当 Leader 服务可以正常使用,就进入消息广播模式,当 Leader 不可用时,则进入崩溃恢复模式。
2、zookeeper集群崩溃恢复leader选举流程
半数节点以上同步成功,3/2+1也就是3个节点需要2个节点同步。zk不是实时的强一致性,可以说是顺序一致性。leader挂了,事务id最大的那个节点成为新的主节点(因为他同步的数据最多)。
3、原子广播协议是什么
ZAB 协议的消息广播过程使用的是一个原子广播协议,类似一个 两阶段提交过程(2PC)。对于客户端发送的写请求,全部由 Leader 接收,Leader 将请求封装成一个事务 Proposal,将其发送给所有 Follwer ,然后,根据所有 Follwer 的反馈,如果超过半数(含leader自己)成功响应,则执行 commit 操作。发送请求会先写到log中,leader收到超过半数ack才会commit写入内存。
4、从create命令来看下zookeeper集群数据同步全流程
通过nio的socketChannel发送到客户端
5、zookeeper链式数据处理器之责任链设计模式剖析
LeaderZooKeeperServer 和 FollowerZooKeeperServer 责任链有一定不同,但整体是类似的 ,leader做过的syncRequest(同步日志到磁盘),ackRequest(发送ack到leader),commit(提交数据到内存),finalRequest(数据到内存,节点变动触发客户端监听) ,follower也要做一遍这些操作。
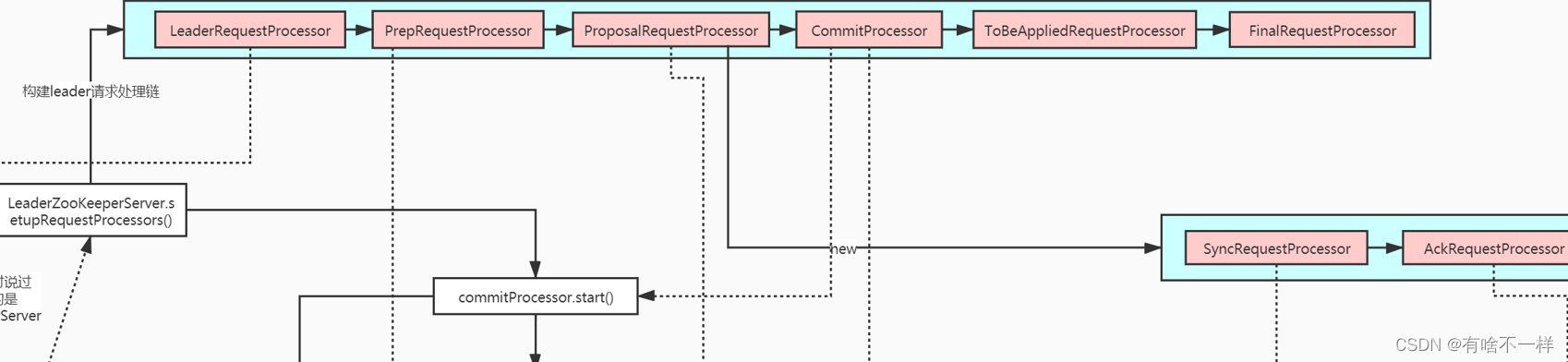

//LeaderZooKeeperServerprotected void setupRequestProcessors() {//构建leader请求处理链 -责任链 设计模式RequestProcessor finalProcessor = new FinalRequestProcessor(this);RequestProcessor toBeAppliedProcessor = new Leader.ToBeAppliedRequestProcessor(finalProcessor, getLeader());commitProcessor = new CommitProcessor(toBeAppliedProcessor,Long.toString(getServerId()), false,getZooKeeperServerListener());commitProcessor.start();ProposalRequestProcessor proposalProcessor = new ProposalRequestProcessor(this,commitProcessor);proposalProcessor.initialize();prepRequestProcessor = new PrepRequestProcessor(this, proposalProcessor);prepRequestProcessor.start();//线程处理消息firstProcessor = new LeaderRequestProcessor(this, prepRequestProcessor);setupContainerManager();}
ProposalRequestProcessor构造器中又初始化了两个Processor
public ProposalRequestProcessor(LeaderZooKeeperServer zks,RequestProcessor nextProcessor) {this.zks = zks;this.nextProcessor = nextProcessor;AckRequestProcessor ackProcessor = new AckRequestProcessor(zks.getLeader());syncProcessor = new SyncRequestProcessor(zks, ackProcessor);}6、集群数据同步全流程
SyncRequestProcessor
client 发起request create /zhuge 666
Leader的操作 1.1 leader向所有follower发送proposal 1.2 写本地数据文件 1.3 给自己发ack
Follower的操作 2.1 写本地数据文件 2.2 返回ack给Leader
Leader的操作 3.1 leader收到半数以上给所有Follower发送commit 3.2 发送inform让observer存储消息 3.3 commit:写自己的内存数据 3.4 回发节点数据变动通知给客户端,触发客户端client监听事件 3.5 返回客户端命令操作结果
Follower的操作 4 commit:写自己的内存数据
当leader发完时还没有超过半数以上,等follower发过来超过后会commit。1.1步中发生的proposal是加入到一个leader的queuedPackets队列里了,leader.lead启动时有启动一个线程LearnerHandler run方法种startSendingPackets方法又启动线程 ,将队列中的packet阻塞式poll数据转发给follower
7、zxid创建流程
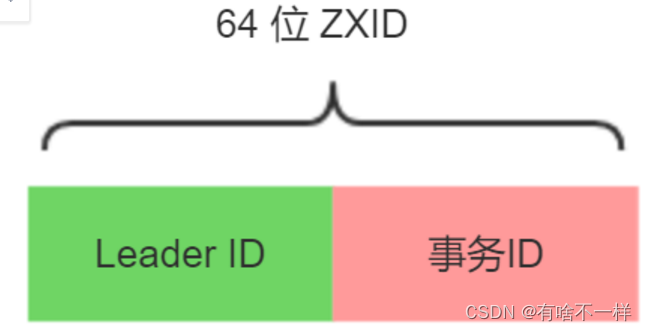
这么设计是因为某个leader挂掉后,事务Id在jvm内存中是无法同步的,所以下一次LeaderId+1即可,这样避免了事务Id又重0开始覆盖之前的记录的问题。private final AtomicLong hzxid = new AtomicLong(0); 事务id自增是原子性的
8、客户端Watcher监听机制
客户端用path和wathcer绑定好存到一个集合里,到时服务端(发现节点变动触发监听机制)传回来一个path,客户端就会根据path从wathcer集合里去找相应的watcher。出于性能考虑监听是一次性的,触发一次后在服务端的watcherTable里会remove这个path
9、zk如何使用BIO&NIO&Netty通信
leader和follower选举后的通讯是建立BIO连接(适用于连接数比较少),除开选举的端口是另一个端口。
zk默认使用NIO连接(适用于多个客户端),因为以前Netty有时候不稳定,需要保证系统的稳定。Netty在后期加入,可以手动配置,现在官方是推荐使用netty.
将zoo.cfg文件位置配置到启动参数里
-Dzookeeper.serverCnxnFactory=org.apache.zookeeper.server.NettyServerCnxnFactory
使用Netty通信

10、zookeeper集群架构如何规避脑裂问题
脑裂(brain-split):脑裂是指在主备切换时,由于切换不彻底或其他原因,导致客户端和follower误以为出现两个leader,最终使得整个集群处于混乱状态。
zookeeper 如果leader挂掉,会进行重新选举,选举周期会+1,就是leaderId会比上一个大,这样可以判断最大的zxid才是最终的leader。就算他后面恢复了,log记录的内容也会被清除掉,因为leaderId不是最大的那个。
11、zookeeper架构设计核心总结
ZAB协议(多节点分布式一致性算法的实现),原子广播,并发消息队列/并发编程,bio/nio通讯,zxid,leader选举(多级内存队列,半数以上),崩溃恢复
这篇关于Zookeeper分布式一致性协议ZAB的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






