本文主要是介绍基于python的网页自动化工具:DrissionPage,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
简介
DrissionPage 是一个基于 python 的网页自动化工具。它既能控制浏览器,也能收发数据包,还能把两者合而为一。可兼顾浏览器自动化的便利性和 requests 的高效率。它功能强大,内置无数人性化设计和便捷功能。它的语法简洁而优雅,代码量少,对新手友好。
安装
pip install DrissionPage# 升级最新稳定版
pip install DrissionPage --upgrade# 指定版本升级
pip install DrissionPage==4.0.0b17
主要对象
ChromiumPage:单纯用于操作浏览器的页面对象
SessionPage:单纯用于收发数据包的页面对象
WebPage:整合浏览器控制和收发数据包于一体的页面对象
尝试启动浏览器
from DrissionPage import ChromiumPagepage = ChromiumPage()
page.get('http://g1879.gitee.io/DrissionPageDocs')
设置路径
首先通过Chrome快捷方式是找到Chrome路径。
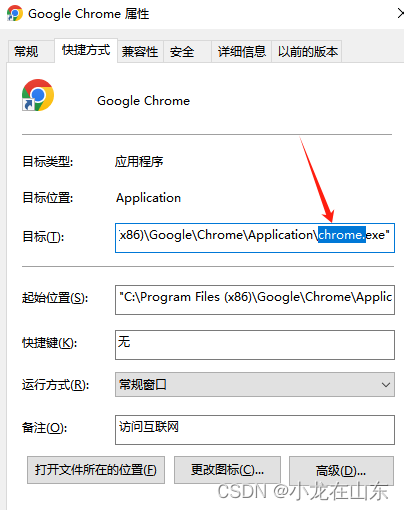
from DrissionPage import ChromiumOptionspath = r'D:\Chrome\Chrome.exe' # 请改为你电脑内Chrome可执行文件路径
ChromiumOptions().set_browser_path(path).save()
定位元素、触发事件
from DrissionPage import ChromiumPage# 创建页面对象,并启动或接管浏览器
page = ChromiumPage()
# 跳转到登录页面
page.get('https://gitee.com/login')# 定位到账号文本框,获取文本框元素
ele = page.ele('#user_login')
# 输入对文本框输入账号
ele.input('您的账号')
# 定位到密码文本框并输入密码
page.ele('#user_password').input('您的密码')
# 点击登录按钮
page.ele('@value=登 录').click()
遍历数据
from DrissionPage import SessionPage# 创建页面对象
page = SessionPage()# 爬取3页
for i in range(1, 4):# 访问某一页的网页page.get(f'https://gitee.com/explore/all?page={i}')# 获取所有开源库<a>元素列表links = page.eles('.title project-namespace-path')# 遍历所有<a>元素for link in links:# 打印链接信息print(link.text, link.link)
切换模式
from DrissionPage import WebPage# 创建页面对象
page = WebPage()
# 访问网址
page.get('https://gitee.com/explore')
# 查找文本框元素并输入关键词
page('#q').input('DrissionPage')
# 点击搜索按钮
page('t:button@tx():搜索').click()
# 等待页面加载
page.wait.load_start()
# 切换到收发数据包模式
page.change_mode()
# 获取所有行元素
items = page('#hits-list').eles('.item')
# 遍历获取到的元素
for item in items:# 打印元素文本print(item('.title').text)print(item('.desc').text)print()
参考
https://g1879.gitee.io/drissionpagedocs/
这篇关于基于python的网页自动化工具:DrissionPage的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



![python 字典d[k]中key不存在的解决方案](/front/images/it_default.jpg)




