本文主要是介绍[Nodejs]解析表单数据(x-www-form-urlencoded),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在解析x-www-form-urlencoded数据时,使用querystring提示已被弃用。查阅资料后得知可以使用 URLSearchParams 对象进行解析,代码如下
// 解析表单数据的全局中间件
app.use((req, res, next) => {let str = '';req.on('data', chunk => {str += chunk;})req.on('end', () => {// 利用 URLSearchParams 解析 x-www-form-urlencoded 数据const params = new URLSearchParams(str); // params = { 'bookname' => '步履不停', 'author' => '是枝裕和' }// 进一步转换成对象类型数let body = {};params.forEach((value, key) => {body[key] = value;})// 传给请求体 req 下的 body 属性req.body = body;next();})
})postman中设置的请求:
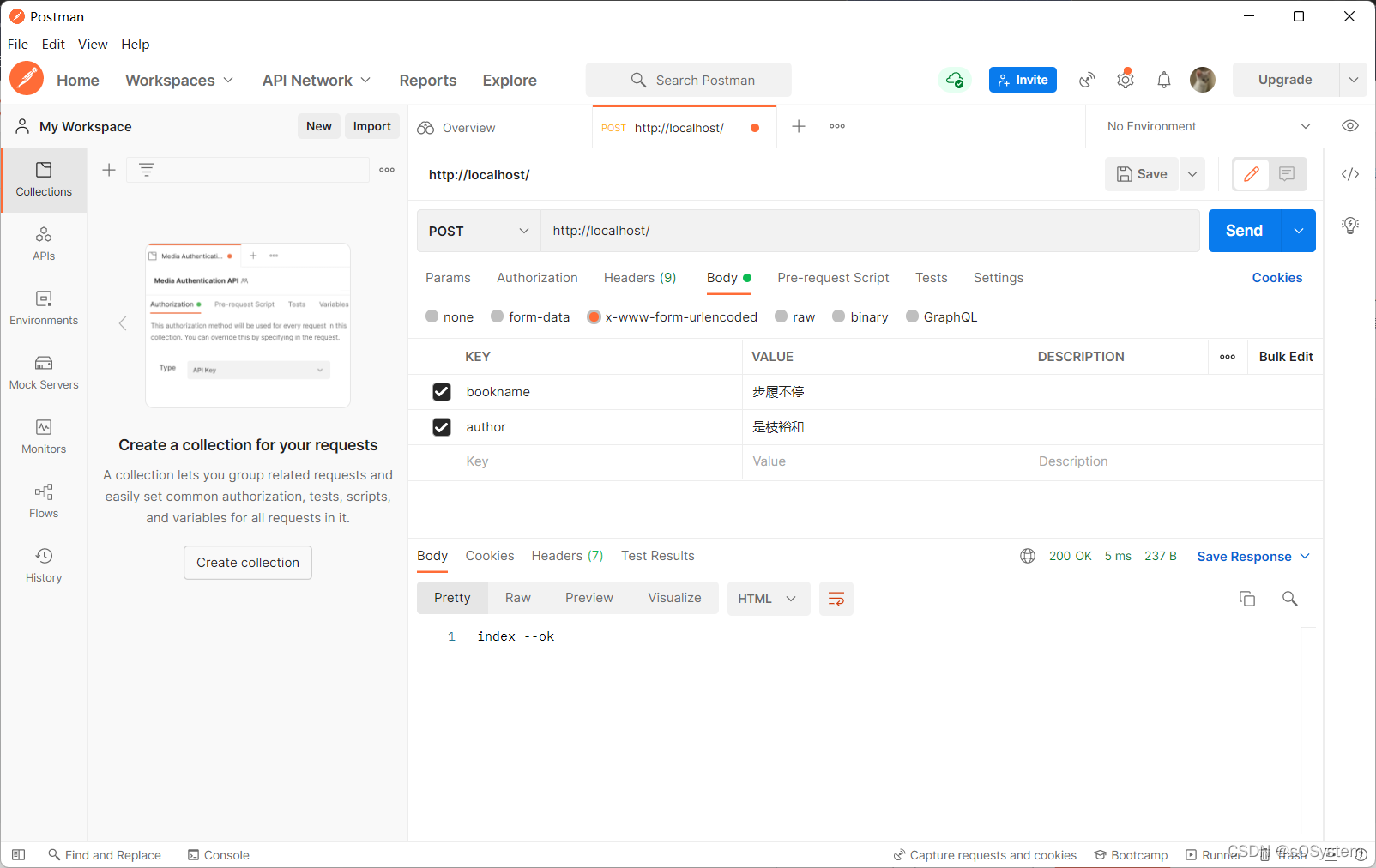
解析结果:
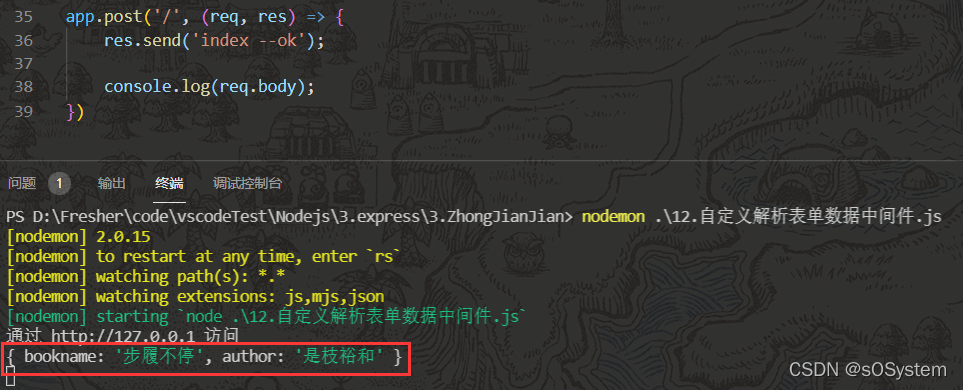
更多关于 URLSearchParams 的内容可以参照下面的文章
https://sunzhaoxiang.blog.csdn.net/article/details/88017953
这篇关于[Nodejs]解析表单数据(x-www-form-urlencoded)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



