本文主要是介绍Linux-4.20.8内核桥收包源码解析(二)----------sk_buff的操作,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
作者:lwyang?
内核版本:Linux-4.20.8
SKB的缓存池
网络模块中,有两个用来分配SKB的高速缓存池
void __init skb_init(void)
{skbuff_head_cache = kmem_cache_create_usercopy("skbuff_head_cache",sizeof(struct sk_buff),0,SLAB_HWCACHE_ALIGN|SLAB_PANIC,offsetof(struct sk_buff, cb),sizeof_field(struct sk_buff, cb),NULL);skbuff_fclone_cache = kmem_cache_create("skbuff_fclone_cache",sizeof(struct sk_buff_fclones),0,SLAB_HWCACHE_ALIGN|SLAB_PANIC,NULL);
}
/* Layout of fast clones : [skb1][skb2][fclone_ref] */
struct sk_buff_fclones {struct sk_buff skb1;struct sk_buff skb2;//父子skb总计数refcount_t fclone_ref;
};
skbuff_head_cache :创建skbuff_head_cache高速缓存,一般情况下,SKB都是从该高速缓存创建的
skbuff_fclone_cache :创建每次以两倍SKB描述符长度分配空间的skbuff_fclone_cache高速缓存,如果在分配SKB时就知道可能被克隆,那么应该从这个高速缓存分配空间,用于后续克隆提高效率,创建时指定的单位内存区域为2*sizeof(struct sk_buff) + sizeof(refcount_t)
分配SKB
static inline struct sk_buff *alloc_skb(unsigned int size,gfp_t priority)
{return __alloc_skb(size, priority, 0, NUMA_NO_NODE);
}
//If SKB_ALLOC_FCLONE is set, allocate from fclone cache
//instead of head cache and allocate a cloned (child) skb
struct sk_buff *__alloc_skb(unsigned int size, gfp_t gfp_mask,int flags, int node)
{struct kmem_cache *cache;struct skb_shared_info *shinfo;struct sk_buff *skb;u8 *data;bool pfmemalloc;//根据参数fclone确定从哪个高速缓存中分配SKBcache = (flags & SKB_ALLOC_FCLONE)? skbuff_fclone_cache : skbuff_head_cache;if (sk_memalloc_socks() && (flags & SKB_ALLOC_RX))gfp_mask |= __GFP_MEMALLOC;/* Get the HEAD *///从分配标志中去除GFP_DMAskb = kmem_cache_alloc_node(cache, gfp_mask & ~__GFP_DMA, node);if (!skb)goto out;prefetchw(skb);/* We do our best to align skb_shared_info on a separate cache* line. It usually works because kmalloc(X > SMP_CACHE_BYTES) gives* aligned memory blocks, unless SLUB/SLAB debug is enabled.* Both skb->head and skb_shared_info are cache line aligned.*///数据缓冲区大小size对齐size = SKB_DATA_ALIGN(size);size += SKB_DATA_ALIGN(sizeof(struct skb_shared_info));//分配数据缓冲区,长度为size和sizeof(struct skb_shared_info)之和,因为缓冲区尾部紧跟着skb_shared_infodata = kmalloc_reserve(size, gfp_mask, node, &pfmemalloc);if (!data)goto nodata;/* kmalloc(size) might give us more room than requested.* Put skb_shared_info exactly at the end of allocated zone,* to allow max possible filling before reallocation.*/size = SKB_WITH_OVERHEAD(ksize(data));prefetchw(data + size);/** Only clear those fields we need to clear, not those that we will* actually initialise below. Hence, don't put any more fields after* the tail pointer in struct sk_buff!*/memset(skb, 0, offsetof(struct sk_buff, tail));/* Account for allocated memory : skb + skb->head */skb->truesize = SKB_TRUESIZE(size);skb->pfmemalloc = pfmemalloc;refcount_set(&skb->users, 1);skb->head = data;skb->data = data;skb_reset_tail_pointer(skb);skb->end = skb->tail + size;skb->mac_header = (typeof(skb->mac_header))~0U;skb->transport_header = (typeof(skb->transport_header))~0U;/* make sure we initialize shinfo sequentially */shinfo = skb_shinfo(skb);memset(shinfo, 0, offsetof(struct skb_shared_info, dataref));atomic_set(&shinfo->dataref, 1);//如果从skbuff_fclone_cache 高速缓存分配SKB描述符,还需要设置父SKB的fclone为SKB_FCLONE_ORIG,表示可以克隆,//同时将子skb的fclone设置为SKB_FCLONE_CLONE,引用计数fclone_ref置为1if (flags & SKB_ALLOC_FCLONE) {struct sk_buff_fclones *fclones;fclones = container_of(skb, struct sk_buff_fclones, skb1);skb->fclone = SKB_FCLONE_ORIG;refcount_set(&fclones->fclone_ref, 1);fclones->skb2.fclone = SKB_FCLONE_CLONE;}
out:return skb;
nodata:kmem_cache_free(cache, skb);skb = NULL;goto out;
}
调用alloc_skb()之后的套接字缓冲区
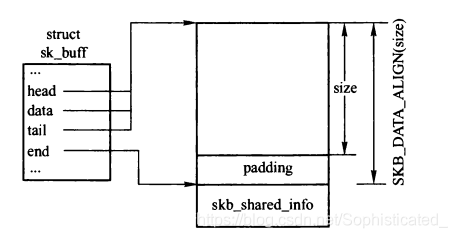
dev_alloc_skb()通常被设备驱动用在中断上下文中
skb数据操作
skb_reserve() 在数据缓冲区头部预留空间,通常用在在数据缓冲区插入协议首部或者在某边界上对齐,只是简单的更新了数据缓冲区的两个指针data和tail,只能用于空skb
static inline void skb_reserve(struct sk_buff *skb, int len)
{skb->data += len;skb->tail += len;
}
skb_push()在缓冲区开头加入一块空间,没有真正向数据缓冲区添加数据,只是data指针上移,一般添加头部时使用
static inline void *__skb_push(struct sk_buff *skb, unsigned int len)
{skb->data -= len;skb->len += len;return skb->data;
}
skb_pull()将data指针下移,一般用于在接收数据包由下往上传递,上层忽略下次的首部
static inline void *__skb_pull(struct sk_buff *skb, unsigned int len)
{skb->len -= len;BUG_ON(skb->len < skb->data_len);return skb->data += len;
}
skb_put() 修改数据区末尾指针tail,使之下移,使数据区向下扩大len字节
static inline void *__skb_put(struct sk_buff *skb, unsigned int len)
{//tmp = skb->head + skb->tailvoid *tmp = skb_tail_pointer(skb);SKB_LINEAR_ASSERT(skb);skb->tail += len;skb->len += len;return tmp;
}
复制和克隆skb
skb_clone()只复制skb描述符,同时增加缓存区的引用计数,以免共享数据提前释放。包克隆的场景是一个接收包程序要把该数据包传递给多个接收者,例如包处理函数后者一个或多个网络模块,原始的及克隆skb描述符cloned值都会被设置为1,克隆的skb描述符users置为1,这样在第一次释放时就会释放掉,同时数据缓冲区引用计数加1
//Duplicate an &sk_buff. The new one is not owned by a socket.
//Both copies share the same packet data but not structure.
//The new buffer has a reference count of 1
struct sk_buff *skb_clone(struct sk_buff *skb, gfp_t gfp_mask)
{struct sk_buff_fclones *fclones = container_of(skb,struct sk_buff_fclones,skb1);struct sk_buff *n;if (skb_orphan_frags(skb, gfp_mask))return NULL;//如果skb的flone标记为SKB_FCLONE_ORIG 并且sk_buff_fclones 的引用计数为1,就直接从skbuff_fclone_cache中分配if (skb->fclone == SKB_FCLONE_ORIG &&refcount_read(&fclones->fclone_ref) == 1) {n = &fclones->skb2;//设置sk_buff_fclones 加1refcount_set(&fclones->fclone_ref, 2);} else {if (skb_pfmemalloc(skb))gfp_mask |= __GFP_MEMALLOC;//否则就从skbuff_head_cache缓冲池中分配一个新的skb来用于克隆n = kmem_cache_alloc(skbuff_head_cache, gfp_mask);if (!n)return NULL;//设置新分配的skb的fclone标识为SKB_FCLONE_UNAVAILABLEn->fclone = SKB_FCLONE_UNAVAILABLE;}return __skb_clone(n, skb);
}
上面函数决定完是从skbuff_fclone_cache还是skbuff_head_cache中分配skb后,接下来就是将skb描述符各字段赋值给克隆的skb
static struct sk_buff *__skb_clone(struct sk_buff *n, struct sk_buff *skb)
{
//定义一个宏用于父子skb直接的数据复制
#define C(x) n->x = skb->xn->next = n->prev = NULL;//克隆的skb的sock为NULLn->sk = NULL;__copy_skb_header(n, skb);C(len);C(data_len);C(mac_len);n->hdr_len = skb->nohdr ? skb_headroom(skb) : skb->hdr_len;//将克隆skb的fcloned字段设置为1n->cloned = 1;n->nohdr = 0;n->peeked = 0;C(pfmemalloc);n->destructor = NULL;//复制数据缓冲区的指针C(tail);C(end);C(head);C(head_frag);C(data);C(truesize);//将克隆skb的users字段设置为1refcount_set(&n->users, 1);//将原skb非线性区域中的dataref字段加1atomic_inc(&(skb_shinfo(skb)->dataref));//将原skb的users字段设置为1skb->cloned = 1;return n;
#undef C
}
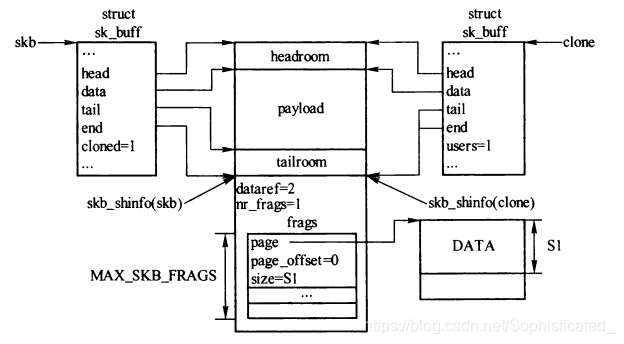
skb_copy() 当需要修改缓冲区的数据时就需要用到
// Make a copy of both an &sk_buff and its data.
// This is used when the caller wishes to modify the data and needs a private copy of the data to alter.
// Returns %NULL on failure or the pointer to the buffer on success. The returned buffer has a reference count of 1
struct sk_buff *skb_copy(const struct sk_buff *skb, gfp_t gfp_mask)
{int headerlen = skb_headroom(skb);unsigned int size = skb_end_offset(skb) + skb->data_len;struct sk_buff *n = __alloc_skb(size, gfp_mask,skb_alloc_rx_flag(skb), NUMA_NO_NODE);if (!n)return NULL;/* Set the data pointer */skb_reserve(n, headerlen);/* Set the tail pointer and length */skb_put(n, skb->len);BUG_ON(skb_copy_bits(skb, -headerlen, n->head, headerlen + skb->len));skb_copy_header(n, skb);return n;
}

As by-product this function converts non-linear &sk_buff to linear one, so that &sk_buff becomes completely private and caller is allowed to modify all the data of returned buffer. This means that this function is not recommended for use in circumstances when only header is going to be modified. Use
pskb_copy()instead.
skb_clone–只复制skb描述符本身,如果只修改skb描述符则使用该函数克隆;
pskb_copy–复制skb描述符+线性数据区域(包括skb_shared_info),如果需要修改描述符以及数据则使用该函数复制;
skb_copy–复制所有数据,包括skb描述符+线性数据区域+非线性数据区,如果需要修改描述符和全部数据则使用该函数复制;
这篇关于Linux-4.20.8内核桥收包源码解析(二)----------sk_buff的操作的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







