本文主要是介绍DDR4读写测试(二):基本读写测试,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
上次基本讲了怎么配置MIG的IP,这次继续翻译手册PG150,根据其提供用户端的app接口的读写模式,针对每种模式进行最基本的读写测试。
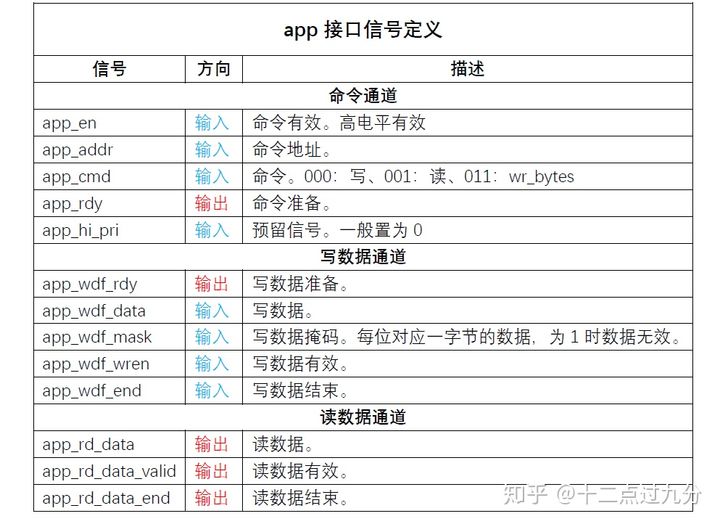
MIG核用户app接口信号定义
写RTL前需要了解些什么?
- 还需了解什么?知道个app接口定义不就好了????
但似乎在(一):MIG IP核配置中并未提地址的事情,所以本文再探讨下地址的问题。
我们知道,一个RAM中一个地址对应存储一个数据。但是问题来了,在KCU116评估板上有两颗DDR4的颗粒,都是256Mb*16的,也就是总容量为256Mb*16*2=8Gb,但是app接口提供的地址位宽为28bit,数据位宽256,也就是说对应的数据量为(2^28)*256bit=64Gb,显然64不等于8,那岂不是地址长了?高位地址都没用到?
综上,我们需要了解使用的这个IP的app接口的地址的含义。
- 遇事不决,Product Guide!
在文档PG150中的123-128页中特地说明地址的定义,由于KCU116评估板上采用两颗DDR4的颗粒,并且在之前的MIG的配置中采用“ROW COLUMN BANK”映射形式(当然可以按照需要选择不同的映射形式),故可以直接看PG150的124页[1]。

DDR4 “ROW_COLUMN_BANK” Mapping
由上图可以知道,app_addr包括{rank, logical_rank, row, column-3, bank, bank_group, 3},那么问题又来了,以上这些是指什么意思?
这就和DDR的结构有关系了,笔者简单画了个DDR4颗粒的结构图(当然画的比较简单抽象),如下所示:
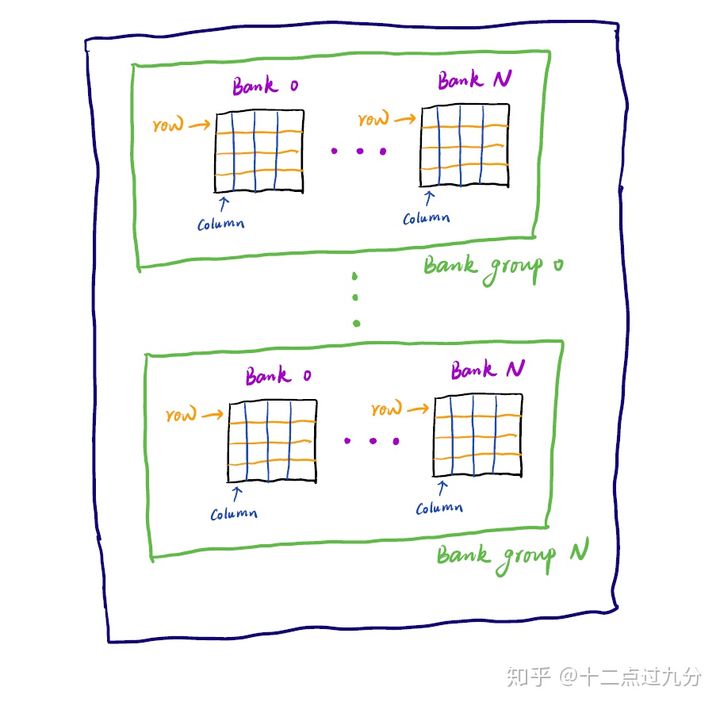
DDR4颗粒的简单结构
由上图可以很清楚的看到,一颗DDR4的颗粒由若干Bank Group组成,每个Bank Group又由若干Bank组成,然后一个Bank由若干行列的矩阵组成,某行某列对应存储某个数据。当然DDR4颗粒会采用3DS(3-Dimensional Stack)堆叠方式来提升单颗的容量,上图只表示为一层时的情况,即logical_rank为1。当然对于某些DDR4内存条来说不只一颗DDR4颗粒,所以又会出现多个颗粒组成一个RANK,比如假定四颗数据位宽为16的DDR4颗粒组成一个RANK,但DDR4内存条上有八颗DDR4颗粒,那么RANK就是2。
了解这些之后,再查询DDR4的颗粒手册,板子采用MT40A256M16GE-075E,参数如下图所示[2]:
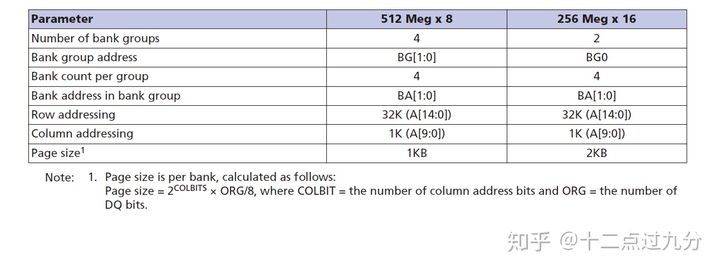
MT40A256M16GE-075E参数
由上可以得知,各参数位宽为:rank = 1,logical_rank = 1,row = 15,column = 10, bank = 2,bank_group = 1。由于rank和logical_rank均为1,按照图“DDR4 “ROW_COLUMN_BANK” Mapping”可知app_addr位宽不包括rank和logical_rank,那么累加其余位宽可得28,正好和app_addr位宽一致!
app接口的地址定义清楚了,那么为什么数据位宽为256,为颗粒16*2的两倍,这时需要注意的是,由两个DDR4颗粒组成一个rank,数据总位宽为32bit,即上述app_addr每个地址对应数据位宽即为32bit,而该MIG中采用Burst Length 8,即app接口的数据位宽为256bit,但经过MIG后分成八次32bit存入相应的地址中,简单计算可得(2^28)*32bit = 8Gb,正好是两个DDR4颗粒的总容量。
- 破案了!
由上可知,并非说app接口的每个地址对应256bit的数据,而是只对应32bit,所以在读写数据的过程中,故需要注意地址的对齐,即app_addr[addr_width-1:3]中的地址可作为256bit数据的读写地址,而低三位[2:0]作为每个256bit分为8个32bit数据的存储地址。
- 在什么情况下读写DDR4的效率最高?
前文说过DDR4相较于DDR3的最大改进之处即提出Bank Group结构,而每个Group可以独立工作,即如果前后对DDR的操作位于不同的Group里,那么后者不必等带前者执行完即可独立执行读写操作。那么本文采用的这颗DDR具有2个Bank Group,也就是说在最理想的情况下只要前后两次读操作或者写操作在不同的Group,即可获得最大性能。
上文得到的app_addr = {row, column-3, bank, bank_group, 3},即保证相邻两次读或写操作的app_addr[3]不一致,即可获得最高的读写效率。
上仿真?
本文暂不进行DDR4读写的仿真试验,具体仿真可详见:
- 小勇奋战:DDR3自建仿真平台(一)--成功拉起init_calib_complete信号
- 小勇奋战:DDR3自建仿真平台(二)--用户端读写仿真测试
- 小勇奋战:DDR3的亲戚DDR4--依旧是跑仿真
测试一:简单顺序写读测试
接下来就是进行简单的读写测试,读写的时许图如下图所示[3],RTL按照时许图写即可。
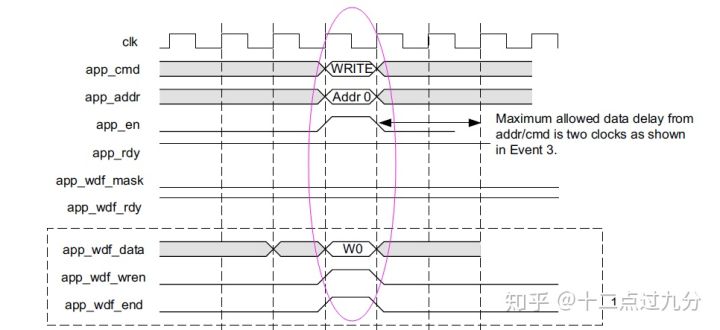
DDR4 写操作时序图
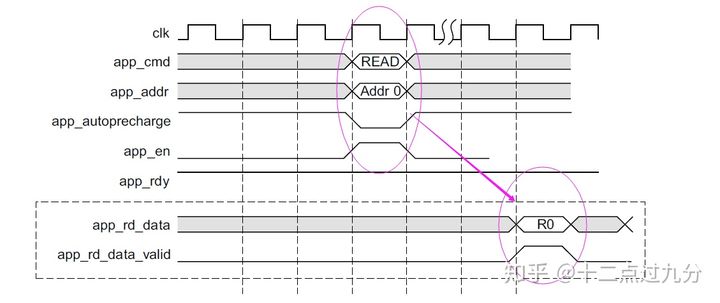
DDR4 读操作时序图
- 万物皆可状态机!
笔者采用状态机简单写了DDR4的写读的RTL如后附录所示,大概逻辑是:每次先向连续八个地址写入八个数据,再从这八个地址将数据读出,然后这个流程一直循环!
之后就是综合、加Debug、布局布线、生成bit、下载到 KCU116 评估板上观察结果!
- 直接看测试结果!
下图即循环写读流程中一次写读数据过程,分为1-4步可见下图。
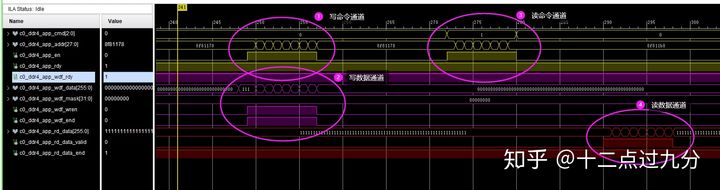
一次写读DDR4的Debug结果
依次向28'h8F81178 - 28'h8F811B0中八个地址写入111111... - 88888.....等八个数据。
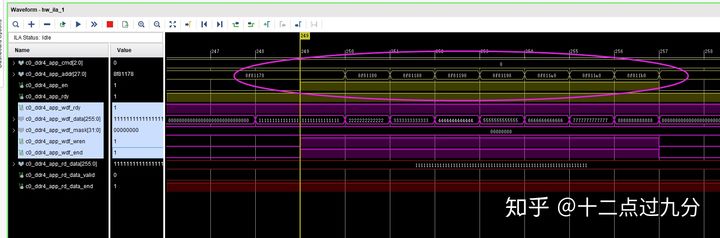
写命令和写数据结果
之后再依次向28'h8F81178 - 28'h8F811B0中八个地址读出111111... - 88888.....等八个数据。
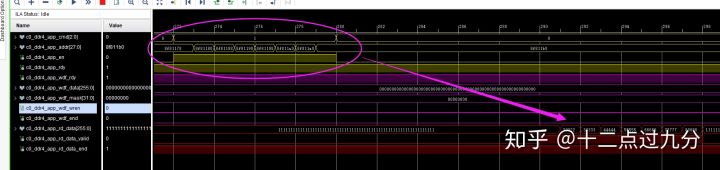
读命令和读数据结果
- 上板测试成功!
由上测试可知,在地址对齐的情况下,连续向多个地址写入数据并再次读出,读写一致,即完成对DDR4的读写测试。同时可以发现,读出数据的顺序与读地址的顺序一致。
- 读写8个太少,我再多点呢?
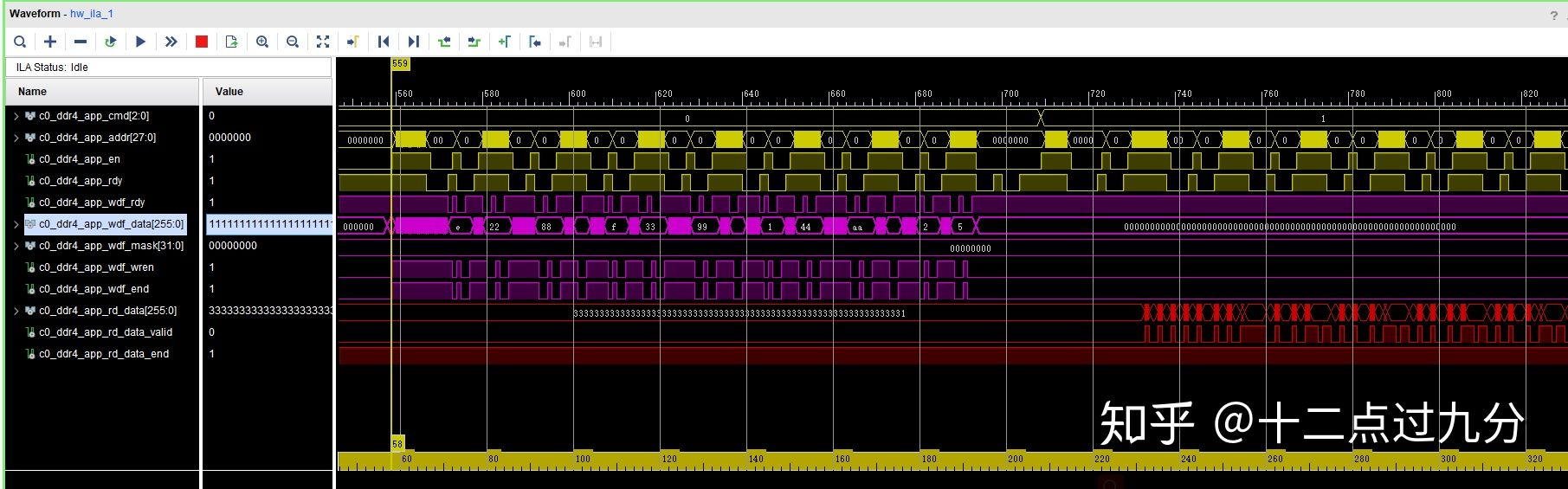
代码逻辑不变,只是将单次写读长度设为64,即单次写读256bit * 64 = 2048 bytes数据,结果如下图。
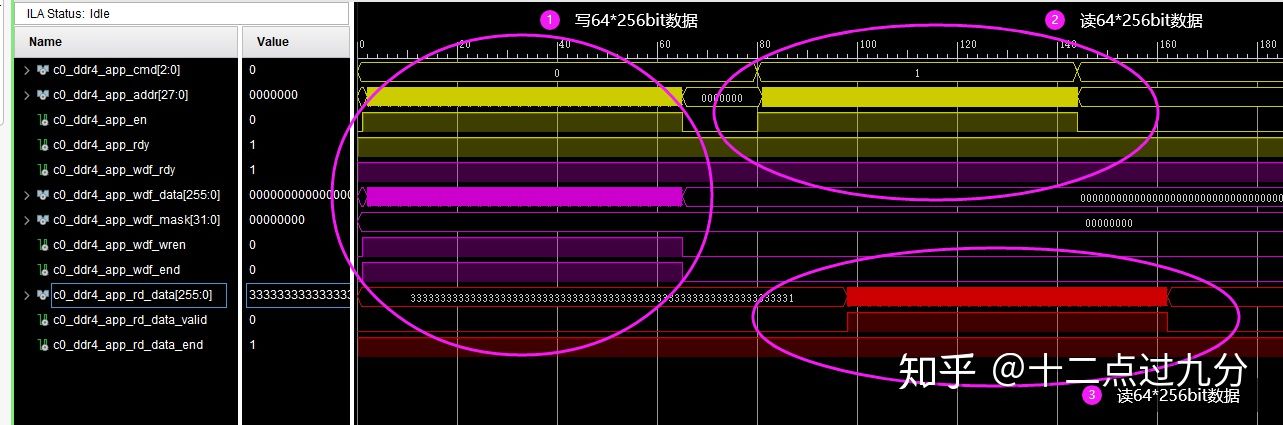
连续写读64*256bit数据结果
对DDR4连续进行64次读写操作,部分结果如下两张图所示,经过写读比较发现,两者数据一致,似乎日常使用问题不大。
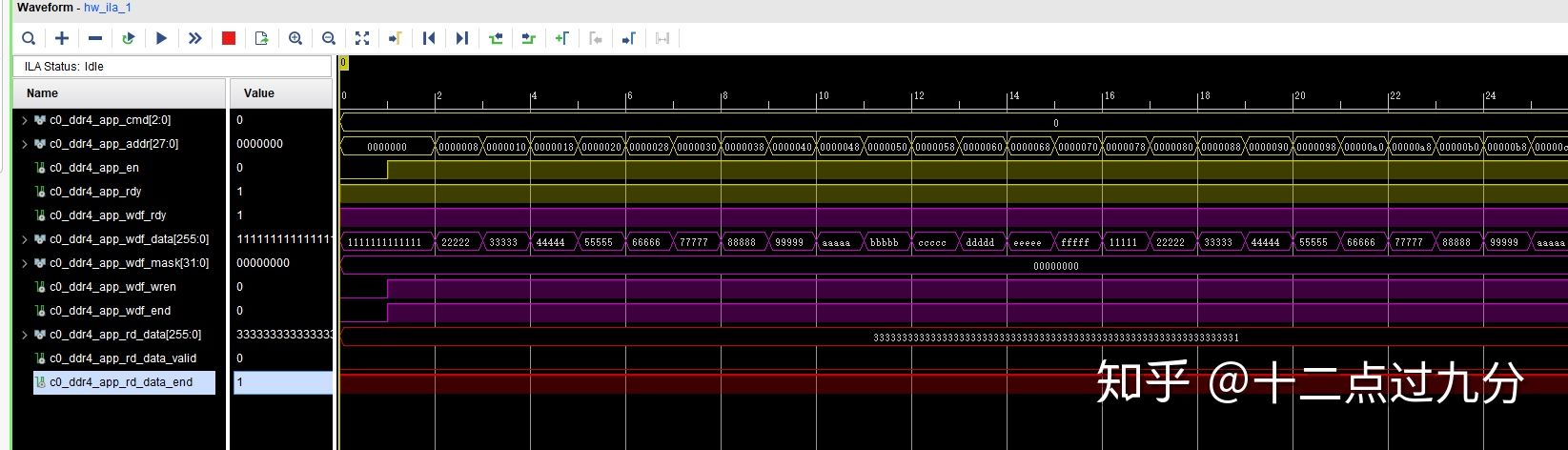
写数据通道
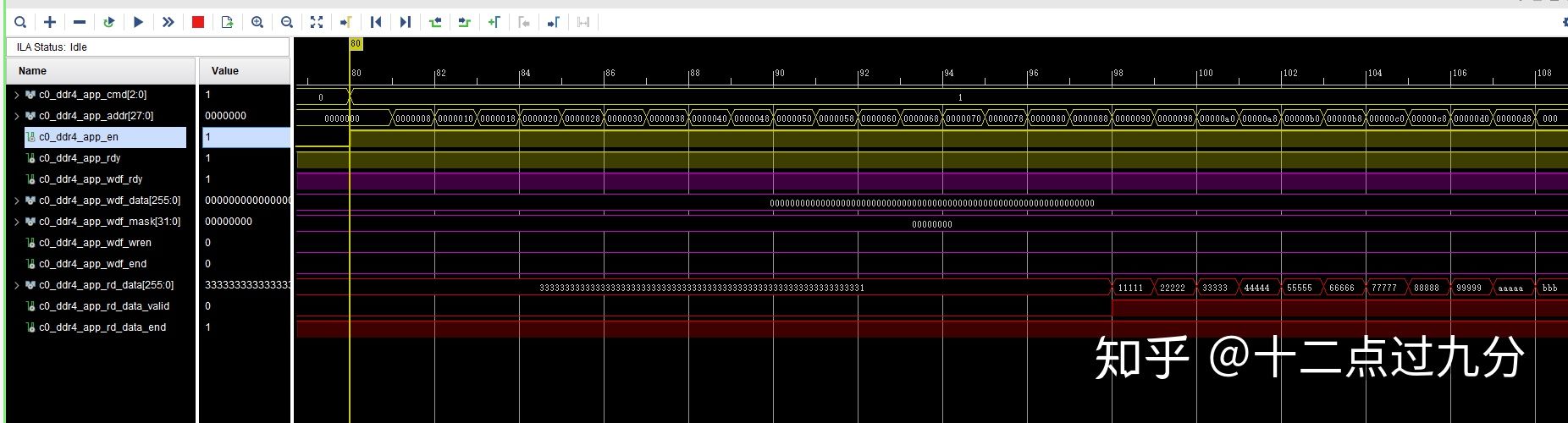
读数据通道
对于该MIG的性能在文档PG150已有说明,如下图即该控制器对总线利用率的情况[4],或许在其他设计中,可以根据下图情况进行合理设计以达到最大利用率。当然,在文档中还有很多性能参数的介绍,这里不再赘述。
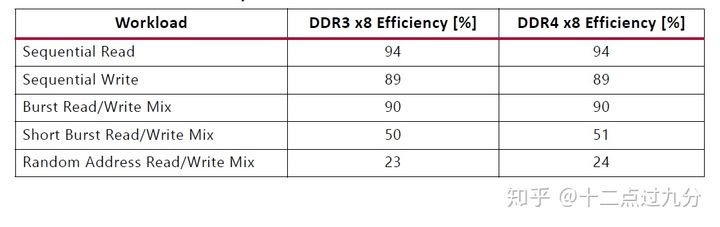
DDR总线效率
测试二:读写延时等测试
对于用户app接口来说,写数据的时候,命令通道和写数据通道的前后延时最大不超过2个时钟周期,在文档PG150已有说明,若下图所示[5],即在允许的范围内,写命令通道可以不与写数据通道一一对齐。
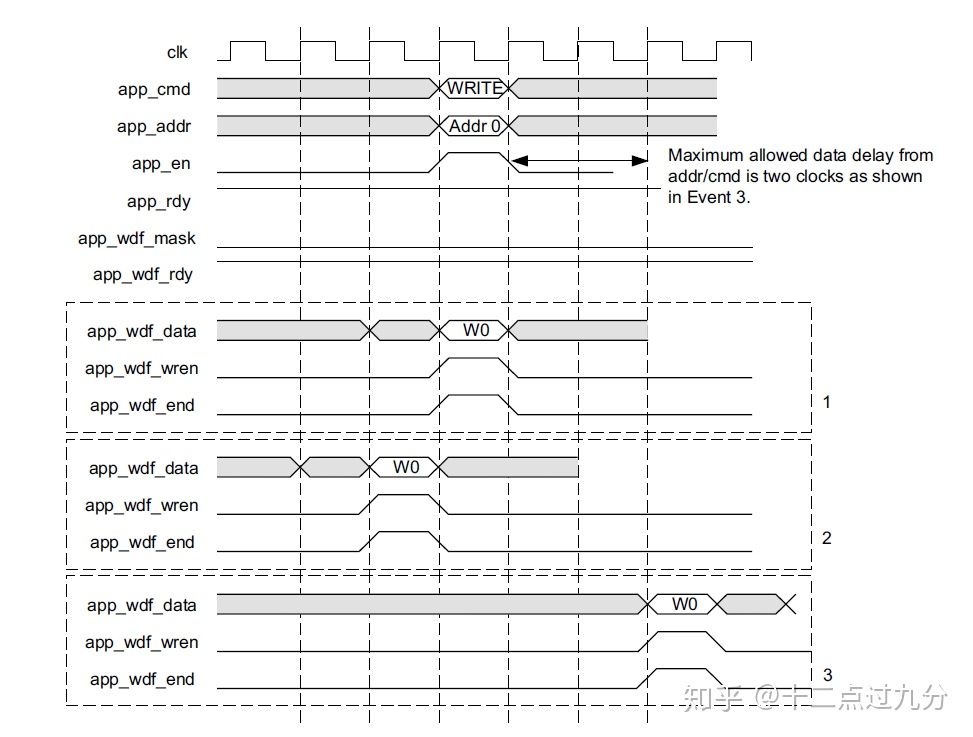
用户app接口写时许图
那么问题来了,我写数据输出到数据真正写入DDR的延时是多少?以及读数据的命令输出到该地址的数据被读出,中间又有多长的延时?
似乎问题在IP的配置过程中已有回答,如下图所示,即写延时14个时钟周期,读延时18个时钟周期,那么果真如此吗?
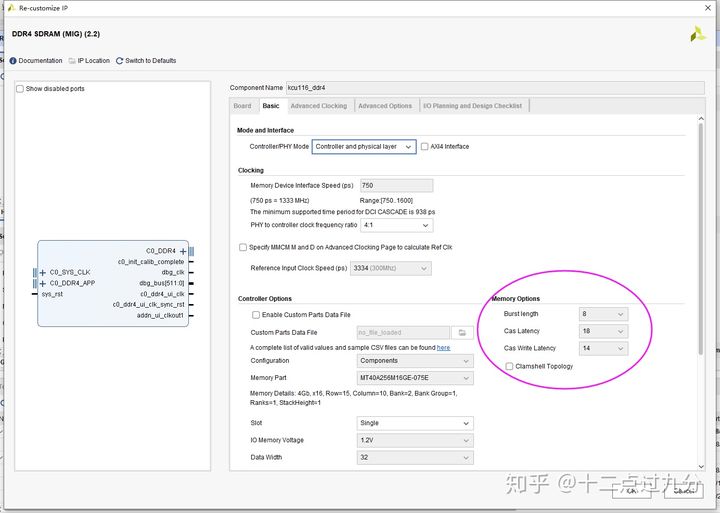
MIG核的Basic界面
由于写延时14,读延时18,在现在的代码逻辑下不能进行测试,故只测试读延时。
下图即读延时的测试结果,的确如IP配置中所说,从读命令发出到数据被读出,中间历经18个时钟周期,诚不欺我!
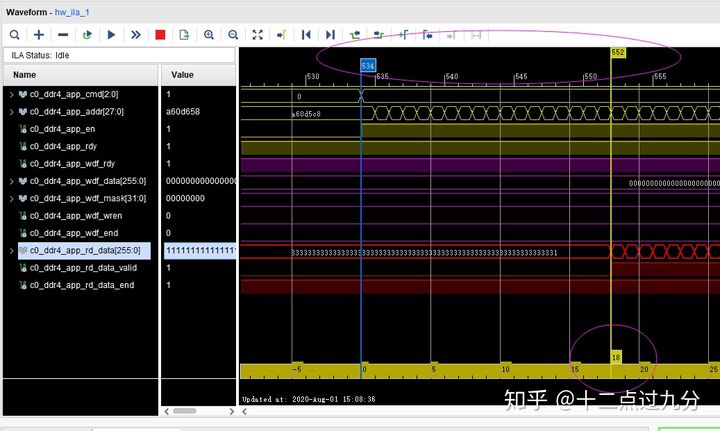
读延时测试结果
测试三:问题测试
- 前面说了,用户app接口的命令通道的地址是根据DDR4的存储结构映射而来的,在使用app接口进行数据的读写时需要注意地址对齐,但是,我就不对齐,你拿我怎样?
如果地址不对齐(从低位地址直接累加),测试结果如下,光这锯齿般的读写就说明效率不高,更不用说数据不对。
地址不对齐,试试就逝世
- 那我对齐地址,但是无视Bank Group、Bank、Row、Column等,读写的地址反复横跳、变换无常又会怎样?
地址反复横跳的最差测试结果如下图所示(同一Bank里读写),虽说写的数据和读出来的数据一致,但是可以明显的看到命令通道的ready信号会拉低,说明由于读写地址在同一bank group里等问题会出现一定的延时,DDR控制器处理不过来,从而导致读写效率的降低。
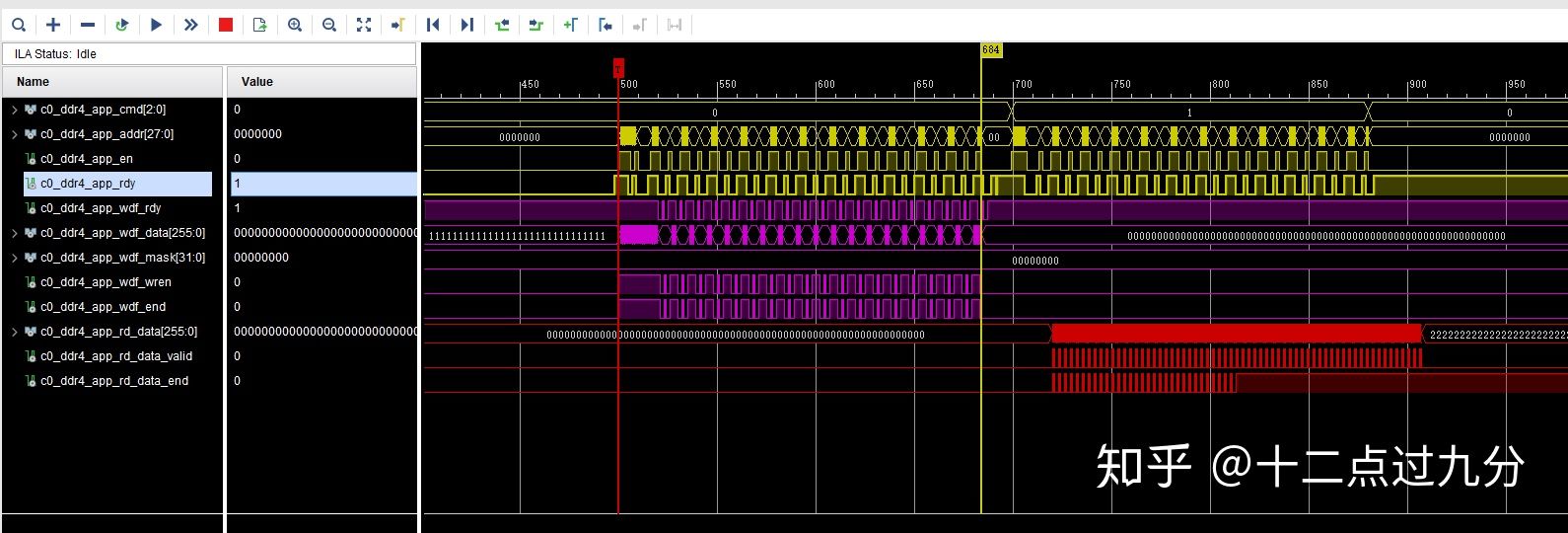
最差读写测试情况
总结
使用MIG的app接口进行读写操作时,需注意地址的映射关系,需注意地址对齐,顺序读写DDR4的效率最高!
注:上述顺序读写即选择“ROW COLUMN BANK”映射,以app_addr[n-1:3] <= app_addr[n-1:3] + 1顺序地址情况下,这样即可做到前后读写数据的地址位于不同的Bank Group里,以最大效率利用DDR的带宽。
以上即DDR4基本读写测试的全部内容,似乎前面关于地址的问题放到(一)中更为合适,不过先就这样放吧。可能上述测试比较简单,之后有时间再深入研究下DDR的其他问题。
因为目前只会使用MIG对DDR进行读写操作,对于DDR的原理结构等尚未非常了解,如有不对之处,还望批评指正~
附录1-DDR4写读测试源码
//代码写的粗糙,仅作循环写读测试使用//--------信号定义------------localparam WR_LENGTH = 8'd8; //每次循环写读测试中数据长度 8*256bitreg [15:0] state_ns;reg [15:0] state_cs;localparam IDLE = 16'h1,WR_DDR = 16'h2,WAIT = 16'h4,RD_DDR = 16'h8,PROC_END = 16'h10;reg process_start;wire write_ddr_end;wire wait_ddr_end;wire read_ddr_end;wire process_end;reg [7:0] write_ddr_cnt;reg [7:0] wait_ddr_cnt;reg [7:0] read_ddr_cnt;reg [15:0] process_cnt;//命令通道reg ddr4_app_en;reg [27:0] ddr4_app_addr;reg [2:0] ddr4_app_cmd;//写数据通道reg ddr4_app_wdf_wren;reg ddr4_app_wdf_end;reg [255:0] ddr4_app_wdf_data;reg [31:0] ddr4_app_wdf_mask;//----------CMD--------------always @ (posedge ddr4_clk or negedge ddr4_rst_n) beginif(!ddr4_rst_n) beginstate_cs <= IDLE;endelse beginstate_cs <= state_ns;endendalways @ (*) begincase(state_cs)IDLE:beginif (process_start) beginstate_ns = WR_DDR;endelse beginstate_ns = IDLE;endendWR_DDR:beginif (write_ddr_end) beginstate_ns = WAIT;endelse beginstate_ns = WR_DDR;endendWAIT:beginif (wait_ddr_end) beginstate_ns = RD_DDR;endelse beginstate_ns = WAIT;endendRD_DDR:beginif (read_ddr_end) beginstate_ns = PROC_END;endelse beginstate_ns = RD_DDR;endendPROC_END:beginif (process_end) beginstate_ns = IDLE;endelse beginstate_ns = PROC_END;endenddefault:beginstate_ns = IDLE;endendcaseend//流程计数always @ (posedge ddr4_clk or negedge ddr4_rst_n) beginif(!ddr4_rst_n) beginprocess_start <= 1'b0;endelse if (state_ns == IDLE) beginprocess_start <= c0_ddr4_init_complete_i & c0_ddr4_app_rdy_i & c0_ddr4_app_wdf_rdy_i;endelse beginprocess_start <= 1'b0;endendalways @ (posedge ddr4_clk or negedge ddr4_rst_n) beginif(!ddr4_rst_n) beginwrite_ddr_cnt <= 8'h0;endelse if ((state_ns == WR_DDR) && c0_ddr4_app_rdy_i && ddr4_app_en) beginwrite_ddr_cnt <= write_ddr_cnt + 8'h1;endelse if (state_ns == PROC_END) beginwrite_ddr_cnt <= 8'h0;endendassign write_ddr_end = (write_ddr_cnt == (WR_LENGTH - 8'h1));always @ (posedge ddr4_clk or negedge ddr4_rst_n) beginif(!ddr4_rst_n) beginwait_ddr_cnt <= 8'h0;endelse if (state_ns == WAIT) beginwait_ddr_cnt <= wait_ddr_cnt + 8'h1;endelse if (state_ns == PROC_END) beginwait_ddr_cnt <= 8'h0;endendassign wait_ddr_end = (wait_ddr_cnt == 8'hF);always @ (posedge ddr4_clk or negedge ddr4_rst_n) beginif(!ddr4_rst_n) beginread_ddr_cnt <= 8'h0;endelse if ((state_ns == RD_DDR) && c0_ddr4_app_rdy_i && ddr4_app_en) beginread_ddr_cnt <= read_ddr_cnt + 8'h1;endelse if (state_ns == PROC_END) beginread_ddr_cnt <= 8'h0;endendassign read_ddr_end = (read_ddr_cnt == (WR_LENGTH - 8'h1));always @ (posedge ddr4_clk or negedge ddr4_rst_n) beginif(!ddr4_rst_n) beginprocess_cnt <= 16'h0;endelse if (state_ns == PROC_END) beginprocess_cnt <= process_cnt + 16'h1;endelse if (state_ns == IDLE) beginprocess_cnt <= 16'h0;endendassign process_end = (process_cnt == 16'hFF);//读写指令always @ (posedge ddr4_clk or negedge ddr4_rst_n) beginif(!ddr4_rst_n) beginddr4_app_en <= 1'b0;ddr4_app_cmd <= 3'b000;endelse begincase(state_ns)WR_DDR:beginif (c0_ddr4_app_rdy_i) beginddr4_app_en <= 1'b1;ddr4_app_cmd <= 3'b000;endelse beginddr4_app_en <= 1'b0;ddr4_app_cmd <= 3'b000;endendRD_DDR:beginif (c0_ddr4_app_rdy_i) beginddr4_app_en <= 1'b1;ddr4_app_cmd <= 3'b001;endelse beginddr4_app_en <= 1'b0;ddr4_app_cmd <= 3'b001;endenddefault:beginddr4_app_en <= 1'b0;ddr4_app_cmd <= 3'b000;endendcaseendend//读写地址always @ (posedge ddr4_clk or negedge ddr4_rst_n) beginif(!ddr4_rst_n) beginddr4_app_addr <= 28'h0;endelse begincase(state_ns)IDLE:beginddr4_app_addr <= 28'h0;endWR_DDR:beginif (c0_ddr4_app_rdy_i && ddr4_app_en) beginddr4_app_addr <= ddr4_app_addr + 28'h8; //地址对齐endelse beginddr4_app_addr <= ddr4_app_addr;endendWAIT:beginddr4_app_addr <= 28'h0;endRD_DDR:beginif (c0_ddr4_app_rdy_i && ddr4_app_en) beginddr4_app_addr <= ddr4_app_addr + 28'h8; //地址对齐endelse beginddr4_app_addr <= ddr4_app_addr;endendPROC_END:beginddr4_app_addr <= 28'h0;enddefault:beginddr4_app_addr <= 28'h0;endendcaseendend//写数据always @ (posedge ddr4_clk or negedge ddr4_rst_n) beginif(!ddr4_rst_n) beginddr4_app_wdf_wren <= 1'b0;ddr4_app_wdf_end <= 1'b0;ddr4_app_wdf_mask <= 32'h0;endelse begincase(state_ns)WR_DDR:beginif (c0_ddr4_app_wdf_rdy_i) beginddr4_app_wdf_wren <= 1'b1;ddr4_app_wdf_end <= 1'b1;ddr4_app_wdf_mask <= 32'h0;endelse beginddr4_app_wdf_wren <= 1'b0;ddr4_app_wdf_end <= 1'b0;ddr4_app_wdf_mask <= 32'h0;end enddefault:beginddr4_app_wdf_wren <= 1'b0;ddr4_app_wdf_end <= 1'b0;ddr4_app_wdf_mask <= 32'h0;endendcaseendendalways @ (posedge ddr4_clk or negedge ddr4_rst_n) beginif(!ddr4_rst_n) beginddr4_app_wdf_data <= 256'h0;endelse if (state_ns == IDLE) beginddr4_app_wdf_data <= {(64){4'b1}};endelse if((state_ns == WR_DDR) && c0_ddr4_app_wdf_rdy_i && ddr4_app_wdf_wren) beginddr4_app_wdf_data <= ddr4_app_wdf_data + {(64){4'b1}};endelse if (state_ns == WAIT) beginddr4_app_wdf_data <= 256'h0;endend
参考
- ^Xilinx手册PG150的第124页
- ^"MT40A256M16-075E" datasheet 第2页 MT40A256M16GE-075E AUT | Micron Technologies, Inc
- ^Xilinx手册PG150的第133页、第136页
- ^Xilinx手册PG150的第20页
- ^Xilinx手册PG150的第133页
这篇关于DDR4读写测试(二):基本读写测试的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






