本文主要是介绍(40)Azkaban调度,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1.Azkaban安装,上网搜,有很多可以操作的博客
2 创建 MySQL 数据库和表
1 )创建 gmall_report 数据库
注 :SQL 语句
CREATE DATABASE `gmall_report`
CHARACTER SET 'utf8' COLLATE
'utf8_general_ci';
2 )创建表
( 1 )创建用户主题表
DROP TABLE IF EXISTS `ads_user_topic`;
CREATE TABLE `ads_user_topic` (
`dt` date NOT NULL,
`day_users` bigint(255) NULL DEFAULT NULL,
`day_new_users` bigint(255) NULL DEFAULT NULL,
`day_new_payment_users` bigint(255) NULL DEFAULT NULL,
`payment_users` bigint(255) NULL DEFAULT NULL,
`users` bigint(255) NULL DEFAULT NULL,
`day_users2users` double(255, 2) NULL DEFAULT NULL,
`payment_users2users` double(255, 2) NULL DEFAULT NULL,
`day_new_users2users` double(255, 2) NULL DEFAULT NULL,
PRIMARY KEY (`dt`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT
= Compact;
( 2 )创建地区主题表
DROP TABLE IF EXISTS `ads_area_topic`;
CREATE TABLE `ads_area_topic` (
`dt` date NOT NULL,
`id` int(11) NULL DEFAULT NULL,
`province_name` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci
NULL DEFAULT NULL,
`area_code` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL
DEFAULT NULL,
`iso_code` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NOT
NULL,
`region_id` int(11) NULL DEFAULT NULL,
`region_name` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci
NULL DEFAULT NULL,
`login_day_count` bigint(255) NULL DEFAULT NULL,
`order_day_count` bigint(255) NULL DEFAULT NULL,
`order_day_amount` double(255, 2) NULL DEFAULT NULL,
`payment_day_count` bigint(255) NULL DEFAULT NULL,
`payment_day_amount` double(255, 2) NULL DEFAULT NULL,
PRIMARY KEY (`dt`, `iso_code`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT
= Compact;
3 )其余 ads 层表(略)
3 Sqoop 导出脚本
1 )编写 Sqoop 导出脚本
在 /home/atguigu/bin 目录下创建脚本 hdfs_to_mysql.sh
[atguigu@hadoop102 bin]$ vim hdfs_to_mysql.sh
在脚本中填写如下内容
#!/bin/bash
hive_db_name=gmall
mysql_db_name=gmall_report
export_data() {
/opt/module/sqoop/bin/sqoop export \
-Dmapreduce.job.queuename=hive \
--connect
"jdbc:mysql://hadoop102:3306/${mysql_db_name}?useUnicode=true&characterEn
coding=utf-8" \
--username root \
--password 000000 \
--table $1 \
--num-mappers 1 \
--export-dir /warehouse/$hive_db_name/ads/$1 \
--input-fields-terminated-by "\t" \
--update-mode allowinsert \
--update-key $2 \
--input-null-string '\\N' \
--input-null-non-string '\\N'
}
case $1 in
"ads_uv_count")
export_data "ads_uv_count" "dt"
;;
"ads_user_action_convert_day")
export_data "ads_user_action_convert_day" "dt"
;;
"ads_user_topic")
export_data "ads_user_topic" "dt"
;;
"ads_area_topic")
export_data "ads_area_topic" "dt,iso_code"
;;
"all")
export_data "ads_user_topic" "dt"
export_data "ads_area_topic" "dt,iso_code"
# 其余表省略未写
;;
esac
关于导出 update 还是 insert 的问题
➢ --update-mode :
updateonly 只更新,无法插入新数据
allowinsert 允许新增
➢
--update-key :允许更新的情况下,指定哪些字段匹配视为同一条数据,进行更新而
不增加。多个字段用逗号分隔。
➢
--input-null-string 和 --input-null-non-string :
分别表示,将字符串列和非字符串列的空串和 “null” 转义。
官网地址: http://sqoop.apache.org/docs/1.4.6/SqoopUserGuide.html
Sqoop will by default import NULL values as string null. Hive is however
using string \N to denote NULL values and therefore predicates dealing
with NULL(like IS NULL) will not work correctly. You should append
parameters --null-string and --null-non-string in case of import job or -
-input-null-string and --input-null-non-string in case of an export job if
you wish to properly preserve NULL values. Because sqoop is using those
parameters in generated code, you need to properly escape value \N to \\N :
Hive 中的 Null 在底层是以“ \N ”来存储,而 MySQL 中的 Null 在底层就是 Null ,为了
保证数据两端的一致性。在导出数据时采用 --input-null-string 和 --input-null-non-string 两个参
数。导入数据时采用 --null-string 和 --null-non-string 。
3 )执行 Sqoop 导出脚本
[atguigu@hadoop102 bin]$ chmod 777 sqoop_export.sh
[atguigu@hadoop102 bin]$ sqoop_export.sh all
4 会员主题指标获取的全调度流程
8.4.1 数据准备
1 )用户行为数据准备
( 1 )修改 /opt/module/applog 下的 application.properties
# 业务日期
mock.date=2020-06-26
注意:分发至其他需要生成数据的节点
[atguigu@hadoop102 applog]$ xsync application.properties
( 2 )生成数据
[atguigu@hadoop102 bin]$ lg.sh
注意:生成数据之后,记得查看 HDFS 数据是否存在!
( 3 )观察 HDFS 的 /origin_data/gmall/log/topic_log/2020-06-26 路径是否有数据

2 )业务数据准备
( 1 )修改 /opt/module/db_log 下的 application.properties
[atguigu@hadoop102 db_log]$ vim application.properties
# 业务日期
mock.date=2020-06-26
( 2 )生成数据
[atguigu@hadoop102 db_log]$ java -jar gmall2020-mock-db-2020-04-01.jar
( 3 )观察 SQLyog 中 order_infor 表中 operate_time 中有 2020-06-26 日期的数据

3. 编译写 Azkaban 工作流程配置文件
1 )编写 azkaban.project 文件,内容如下
azkaban-flow-version: 2.0
2 )编写 gmall.flow 文件,内容如下
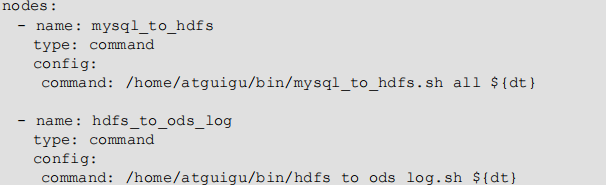
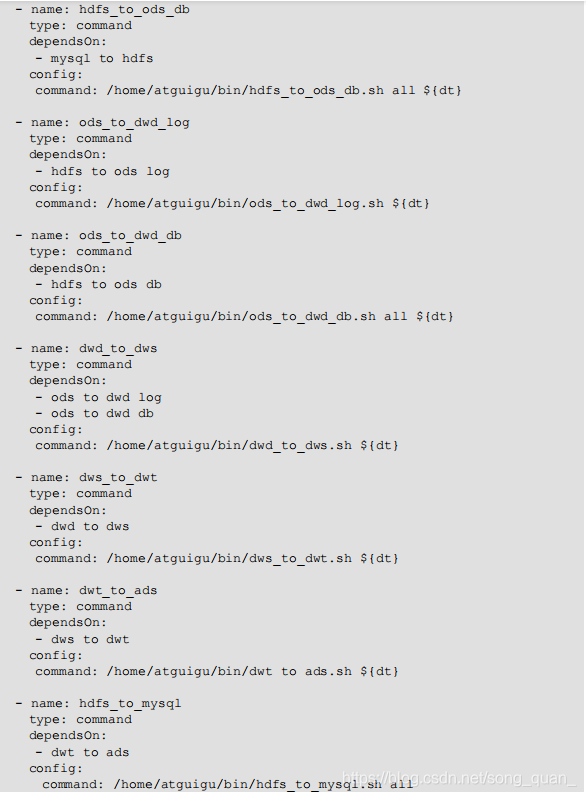
3)将 azkaban.project、gmall.flow 文件压缩到一个 zip 文件,文件名称必须是英文。
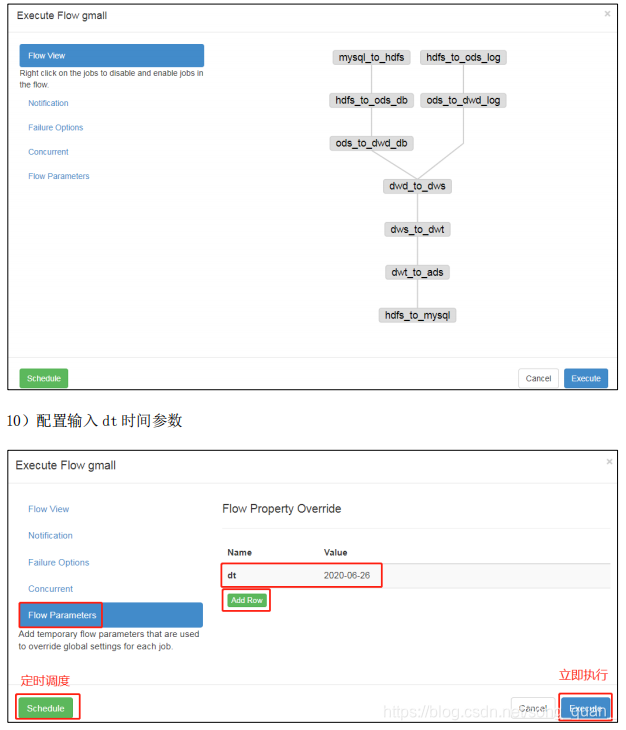
4)在 WebServer 新建项目: http://hadoop102:8081/index


3 Azkaban 多 Executor 模式下注意事项
Azkaban 多 Executor 模式是指,在集群中多个节点部署 Executor 。在这种模式下,
Azkaban web Server 会根据策略,选取其中一个 Executor 去执行任务。
由于我们需要交给 Azkaban 调度的脚本,以及脚本需要的 Hive , Sqoop 等应用只在
hadoop102 部署了,为保证任务顺利执行,我们须在以下两种方案 任选其一,推荐使用方案
二。
方案一:指定特定的 Executor ( hadoop102 )去执行任务。
1 )在 MySQL 中 azkaban 数据库 executors 表中,查询 hadoop102 上的 Executor 的 id 。
mysql> use azkaban;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
mysql> select * from executors;
+----+-----------+-------+--------+
| id | host | port | active |
+----+-----------+-------+--------+
| 1 | hadoop103 | 35985 | 1 |
| 2 | hadoop104 | 36363 | 1 |
| 3 | hadoop102 | 12321 | 1 |
+----+-----------+-------+--------+
2 )在执行工作流程时加入 useExecutor 属性,如下

方案二:在 Executor 所在所有节点部署任务所需脚本和应用。
1 )分发脚本、 hive 、 sqoop 、 spark 、 my_env.sh
[atguigu@hadoop102 ~]$ xsync /home/atguigu/bin/
[atguigu@hadoop102 ~]$ xsync /opt/module/hive
[atguigu@hadoop102 ~]$ xsync /opt/module/sqoop
[atguigu@hadoop102 ~]$ xsync /opt/module/spark
[atguigu@hadoop102
~]$
sudo /home/atguigu/bin/xsync
/etc/profile.d/my_env.sh
这篇关于(40)Azkaban调度的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




