本文主要是介绍Linux内核源码学习 Ext2文件系统布局,文件数据块寻址,VFS虚拟文件系统 转载,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
https://zhuanlan.zhihu.com/p/441979618
文件系统布局
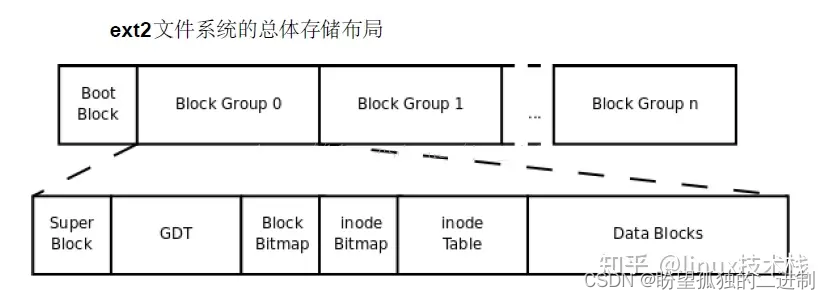
文件系统中存储的最小单位是块( Block),一个块究竟多大是在格式化时确定的,例如 mke2fs 的 -b 选项可以设定块大小为 1024、 2048 或 4096 字节。而上图中引导块/自举块( Boot Block)的大小是确定的,就是 1KB,引导块是由 PC 标准规定的,用来存储磁盘分区信息和启动信息,任何文件系统都不能使用启动块。启动块之后才是 ext2 文件系统的开始, ext2 文件系统将整个分区划成若干个同样大小的块组( Block Group),每个块组都由以下部分组成。
超级块(Super Block)
描述整个分区的文件系统信息,例如块大小、文件系统版本号、上次 mount 的时间等等。超级块在每个块组的开头都有一份拷贝。
块组描述符表(GDT, Group Descriptor Table)
由很多块组描述符组成,整个分区分成多少个块组就对应有多少个块组描述符。每个块组描述符( Group Descriptor)存储一个块组的描述信息,例如在这个块组中从哪里开始是 inode 表,从哪里开始是数据块,空闲的 inode 和数据块还有多少个等等。和超级块类似,块组描述符表在每个块组的开头也都有一份拷贝,这些信息是非常重要的,一旦超级块意外损坏就会丢失整个分区的数据,一旦块组描述符意外损坏就会丢失整个块组的数据,因此它们都有多份拷贝。通常内核只用到第 0 个块组中的拷贝,当执行 e2fsck 检查文件系统一致性时,第 0 个块组中的超级块和块组描述符表就会拷贝到其它块组,这样当第 0 个块组的开头意外损坏时就可以用其它拷贝来恢复,从而减少损失。
块位图(Block Bitmap)
一个块组中的块是这样利用的:数据块存储所有文件的数据,比如某个分区的块大小是 1024 字节,某个文件是 2049字节,那么就需要三个数据块来存,即使第三个块只存了一个字节也需要占用一个整块;超级块、块组描述符表、块位图、 inode 位图、 inode 表这几部分存储该块组的描述信息。那么如何知道哪些块已经用来存储文件数据或其它描述信息,哪些块仍然空闲可用呢?块位图就是用来描述整个块组中哪些块已用哪些块空闲的,它本身占一个块,其中的每个 bit 代表本块组中的一个块,这个 bit 为 1 表示该块已用,这个 bit 为 0 表示该块空闲可用。
为什么用 df 命令统计整个磁盘的已用空间非常快呢?因为只需要查看每个块组的块位图即可,而不需要搜遍整个分区。相反,用 du 命令查看一个较大目录的已用空间就非常慢,因为不可避免地要搜遍整个目录的所有文件。
与此相联系的另一个问题是:在格式化一个分区时究竟会划出多少个块组呢?主要的限制在于块位图本身必须只占一个块。用 mke2fs 格式化时默认块大小是 1024 字节,可以用 -b 参数指定块大小,现在设块大小指定为 b 字节,那么一个块可以有 8b 个 bit,这样大小的一个块位图就可以表示 8b 个块的占用情况,因此一个块组最多可以有 8b 个块,如果整个分区有 s 个块,那么就可以有 s/(8b) 个块组。格式化时可以用 -g 参数指定一个块组有多少个块,但是通常不需要手动指定, mke2fs 工具会计算出最优的数值。
inode 位图(inode Bitmap)
和块位图类似,本身占一个块,其中每个 bit 表示一个 inode 是否空闲可用。
inode 表(inode Table)
我们知道,一个文件除了数据需要存储之外,一些描述信息也需要存储,例如文件类型(常规、目录、符号链接等),权限,文件大小,创建 /修改 /访问时间等,也就是 ls -l命令看到的那些信息,这些信息存在 inode 中而不是数据块中。每个文件都有一个 inode,一个块组中的所有 inode 组成了 inode 表。
inode 表占多少个块在格式化时就要决定并写入块组描述符中, mke2fs 格式化工具的默认策略是一个块组有多少个 8KB 就分配多少个 inode 。由于数据块占了整个块组的绝大部分,也可以近似认为数据块有多少个 8KB 就分配多少个 inode,换句话说,如果平均每个文件的大小是 8KB,当分区存满的时候 inode 表会得到比较充分的利用,数据块也不浪费。如果这个分区存的都是很大的文件(比如电影),则数据块用完的时候 inode 会有一些浪费,如果这个分区存的都是很小的文件(比如源代码),则有可能数据块还没用完 inode 就已经用完了,数据块可能有很大的浪费。如果用户在格式化时能够对这个分区以后要存储的文件大小做一个预测,也可以用 mke2fs 的 -i参数手动指定每多少个字节分配一个 inode。
数据块(Data Block)
根据不同的文件类型有以下几种情况:
对于常规文件,文件的数据存储在数据块中。
对于目录,该目录下的所有文件名和目录名存储在数据块中,注意文件名保存在它所在目录的数据块中,除文件名之外, ls -l 命令看到的其它信息都保存在该文件的 inode 中。注意这个概念:目录也是一种文件,是一种特殊类型的文件。
对于符号链接,如果目标路径名较短则直接保存在 inode 中以便更快地查找,如果目标路径名较长则分配一个数据块来保存。
设备文件、FIFO 和 socket 等特殊文件没有数据块,即文件大小为 0,设备文件的主设备号和次设备号保存在 inode 中。
Ext2 文件系统加上日志支持的下一个版本是 ext3 文件系统,它和 ext2 文件系统在硬盘布局上是一样的,其差别仅仅是 ext3 文件系统在硬盘上多出了一个特殊的 inode(可以理解为一个特殊文件),用来记录文件系统的日志,也即所谓的 journal。
Ext4 支持更大的文件和无限量的子目录。
On an ext3 file-system 31,998 subdirectories is the limit. Each subdirectory is considered a “link” by the system and this is where we get the somewhat cryptic “too many links” message.
By the way, there is technically a limit of 32,000 subdirectories but each directory always includes two links – one to reference itself and another to reference the parent directory – that leaves us with 31,998 to work with.
consider bucketing your directories into a multi-level hashed structure, to reduce the number of directories you need to store at a particular “layer”.In the case of hashes, a similar technique can be used, take the first 4 character of the file “ABCDEFG.txt” and put it in “AB/CD/ABCDEFG.txt”
数据块寻址
如果一个文件有多个数据块,这些数据块很可能不是连续存放的,应该如何寻址到每个块呢?事实上,每个文件的 inode 的索引项一共有 15 个,从 Blocks[0] 到 Blocks[14],每个索引项占 4 字节。前 12 个索引项都表示块编号,例如若 Blocks[0] 字段保存着 24,就表示第 24 个块是该文件的数据块,如果块大小是 1KB,这样可以表示从 0 字节到 12KB 的文件。如果剩下的三个索引项 Blocks[12] 到 Blocks[14] 也是这么用的,就只能表示最大 15KB 的文件了,这是远远不够的,事实上,剩下的三个索引项都是间接索引。
索引项 Blocks[12] 所指向的块并非数据块,而是称为间接寻址块( Indirect Block),其中存放的都是类似 Blocks[0] 这种索引项,再由索引项指向数据块。设块大小是 b,那么一个间接寻址块中可以存放 b/4 个索引项,指向 b/4个数据块。所以如果把 Blocks[0] 到 Blocks[12] 都用上,最多可以表示 b/4+12 个数据块,对于块大小是 1K 的情况,最大可表示 268K 的文件。如下图所示,注意文件的数据块编号是从 0开始的, Blocks[0] 指向第 0 个数据块, Blocks[11] 指向第 11 个数据块, Blocks[12] 所指向的间接寻址块的第一个索引项指向第 12 个数据块,依此类推。
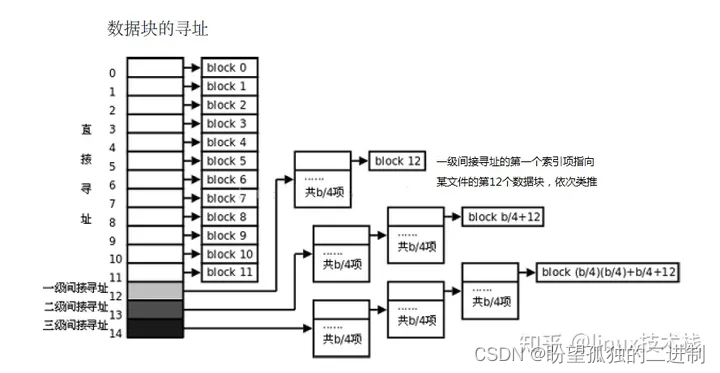
从上图可以看出,索引项 Blocks[13] 指向两级的间接寻址块,总共最多可表示 (b/4)^2 +b/4+12 个数据块,对于 1K 的块大小最大可表示 64.26MB 的文件。索引项 Blocks[14] 指向三级的间接寻址块,总共最多可表示 (b/4)^3 +(b/4)^2 +b/4+12 个数据块,对于 1K 的块大小最大可表示 16.06GB 的文件。
可见,这种寻址方式对于访问不超过 12 个数据块的小文件是非常快的,访问文件中的任意数据只需要两次读盘操作,一次读 inode(也就是读索引项)一次读数据块。而访问大文件中的数据则需要最多五次读盘操作: inode、一级间接寻址块、二级间接寻址块、三级间接寻址块、数据块。实际上,磁盘中的 inode(索引节点高速缓存)和数据块(块高速缓存)往往已经被内核缓存了,读大文件的效率也不会太低。
VFS 虚拟文件系统
Linux 支持各种各样的文件系统格式,如 ext2、 ext3、 reiserfs、 FAT、 NTFS、 iso9660 等等,不同的磁盘分区、光盘或其它存储设备都有不同的文件系统格式,然而这些文件系统都可以 mount 到某个目录下,使我们看到一个统一的目录树,各种文件系统上的目录和文件我们用 ls 命令看起来是一样的,读写操作用起来也都是一样的,这是怎么做到的呢? Linux 内核在各种不同的文件系统格式之上做了一个抽象层,使得文件、目录、读写访问等概念成为抽象层的概念,因此各种文件系统看起来用起来都一样,这个抽象层称为虚拟文件系统(VFS,Virtual File System)。
VFS 是应用程序和具体的文件系统之间的一个层。不过,在某些情况下,一个文件操作可能由 VFS 本身去执行,无需调用下一层程序。例如,当某个进程关闭一个打开的文件时,并不需要涉及磁盘上的相应文件,因此,VFS 只需释放对应的文件对象。类似地,如果系统调用 lseek() 修改一个文件指针,而这个文件指针指向有关打开的文件与进程交互的一个属性,那么 VFS 只需修改对应的文件对象,而不必访问磁盘上的文件,因此,无需调用具体的文件系统子程序。从某种意义上说,可以把 VFS 看成“通用”文件系统,它在必要时依赖某种具体的文件系统。
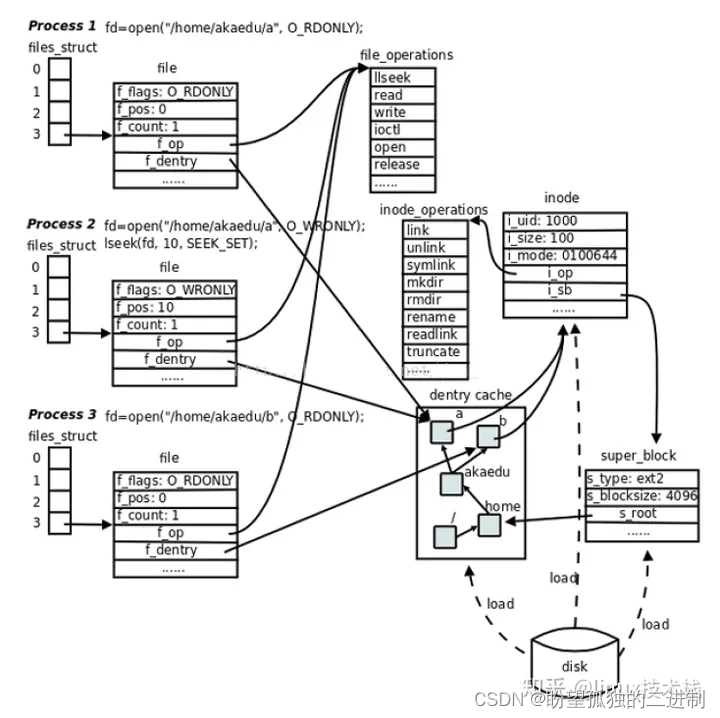
每个进程在 PCB(Process Control Block)中都保存着一个指向文件描述符表的指针(struct files_struct* files),文件描述符就是这个表的索引,每个表项都有一个指向已打开文件的指针,现在我们明确一下:已打开的文件在内核中用 file 结构体表示,文件描述符表中的指针指向 file 结构体。
在 file 结构体中维护 File Status Flag( file 结构体的成员 f_flags)和当前读写位置( file 结构体的成员 f_pos)。在上图中,进程 1 和进程 2 都打开同一文件,但是对应不同的 file 结构体,因此可以有不同的 File Status Flag 和读写位置。 file 结构体中比较重要的成员还有 f_count,表示引用计数( Reference Count),dup、 fork 等系统调用会导致多个文件描述符指向同一个 file 结构体,例如有 fd1 和 fd2 都引用同一个 file 结构体,那么它的引用计数就是 2,当 close(fd1) 时并不会释放 file 结构体,而只是把引用计数减到 1,如果再 close(fd2),引用计数就会减到 0 同时释放 file 结构体,这才真的关闭了文件。
每个 file 结构体都指向一个 file_operations 结构体,这个结构体的成员都是函数指针,指向实现各种文件操作的内核函数。比如在用户程序中 read 一个文件描述符, read 通过系统调用进入内核,然后找到这个文件描述符所指向的 file 结构体,找到 file结构体所指向的 file_operations 结构体,调用它的 read 成员所指向的内核函数以完成用户请求。在用户程序中调用 lseek、read、write、ioctl、open 等函数,最终都由内核调用 file_operations 的各成员所指向的内核函数完成用户请求。 file_operations 结构体中的 release 成员用于完成用户程序的 close 请求,之所以叫 release 而不叫 close 是因为它不一定真的关闭文件,而是减少引用计数,只有引用计数减到 0 才关闭文件。对于同一个文件系统上打开的常规文件来说, read、 write 等文件操作的步骤和方法应该是一样的,调用的函数应该是相同的,所以图中的三个打开文件的 file结构体指向同一个 file_operations 结构体。如果打开一个字符设备文件,那么它的 read、 write 操作肯定和常规文件不一样,不是读写磁盘的数据块而是读写硬件设备,所以 file结构体应该指向不同的 file_operations 结构体,其中的各种文件操作函数由该设备的驱动程序实现。
每个 file 结构体都有一个指向 dentry 结构体的指针, “dentry”是 directory entry(目录项)的缩写。我们传给 open、 stat 等函数的参数的是一个路径,例如 /home/akaedu/a,需要根据路径找到文件的 inode。为了减少读盘次数,内核缓存了目录的树状结构,称为 dentry cache(目录高速缓存),其中每个节点是一个 dentry 结构体,只要沿着路径各部分的 dentry搜索即可,从根目录 /找到 home目录,然后找到 akaedu 目录,然后找到文件 a。 dentry cache 只保存最近访问过的目录项,如果要找的目录项在 cache 中没有,就要从磁盘读到内存中。
每个 dentry 结构体都有一个指针指向 inode 结构体。 inode 结构体保存着从磁盘 inode 读上来的信息。在上图的例子中,有两个 dentry,分别表示 /home/akaedu/a 和 /home/akaedu/b,它们都指向同一个 inode,说明这两个文件互为硬链接。 inode 结构体中保存着从磁盘分区的 inode 读上来信息,例如所有者、文件大小、文件类型和权限位等。每个 inode 结构体都有一个指向 inode_operations 结构体的指针,后者也是一组函数指针指向一些完成文件目录操作的内核函数。和 file_operations 不同, inode_operations 所指向的不是针对某一个文件进行操作的函数,而是影响文件和目录布局的函数,例如添加删除文件和目录、跟踪符号链接等等,属于同一文件系统的各 inode 结构体可以指向同一个 inode_operations 结构体。
inode 结构体有一个指向 super_block 结构体的指针。 super_block 结构体保存着从磁盘分区的超级块读上来的信息,例如文件系统类型、块大小等。 super_block 结构体的 s_root 成员是一个指向 dentry 的指针,表示这个文件系统的根目录被 mount 到哪里,在上图的例子中这个分区被 mount 到 /home 目录下。
file、 dentry、 inode、 super_block 这几个结构体组成了 VFS 的核心概念。对于 ext2 文件系统来说,在磁盘存储布局上也有 inode 和超级块的概念,所以很容易和 VFS 中的概念建立对应关系。而另外一些文件系统格式来自非 UNIX 系统(例如 Windows的 FAT32、 NTFS),可能没有 inode 或超级块这样的概念,但为了能 mount到 Linux系统,也只好在驱动程序中硬凑一下,在 Linux下看 FAT32 和 NTFS 分区会发现权限位是错的,所有文件都是 rwxrwxrwx,因为它们本来就没有 inode 和权限位的概念,这是硬凑出来的。
这篇关于Linux内核源码学习 Ext2文件系统布局,文件数据块寻址,VFS虚拟文件系统 转载的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







