本文主要是介绍【面试突击】深挖网络 IO 面试实战,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
🌈🌈🌈🌈🌈🌈🌈🌈
欢迎关注公众号(通过文章导读关注:【11来了】),及时收到 AI 前沿项目工具及新技术的推送!在我后台回复 「资料」 可领取
编程高频电子书!
在我后台回复「面试」可领取硬核面试笔记!文章导读地址:点击查看文章导读!
感谢你的关注!
🍁🍁🍁🍁🍁🍁🍁🍁 
深挖网络 IO 面试实战
学前须知:
这个模块对网络 IO 这块进行深挖,深入理解了网络 IO 之后,可以跟面试官聊的有来有回,通过深入讨论,你可以展示你对网络 I/O 了解的很深入,以及你如何将这些知识应用到实际的服务器架构和性能优化中,那面试的结果一定是非常不错的
(切记不要对每一块的内容都浅尝辄止,没有技术深度是无法让面试官刮目相看的)
这个模块对网络 IO 这块进行深挖,深入理解了网络 IO 之后,可以跟面试官聊的有来有回,那面试的结果一定是非常不错的
如果每次面试官问一个问题,你都是回答了解一下,那样只会显出你对这块内容的理解太表层!
这个模块对网络 IO 这块进行深挖,深入理解了网络 IO 之后,可以跟面试官聊的有来有回,那面试的结果一定是非常不错的
如果每次面试官问一个问题,你都是回答了解一下,那样只会显出你对这块内容的理解太表层!
只要问到网络 IO 方面,那么一定会去问 Netty 的内容,因为几乎所有的网络通信,只要是用 Java 做的,都是使用 Netty 框架来进行网络通信的,所以 Netty 的东西一定要了解,如果不了解 Netty ,就像你学习 Java 不了解 SpringBoot 一样
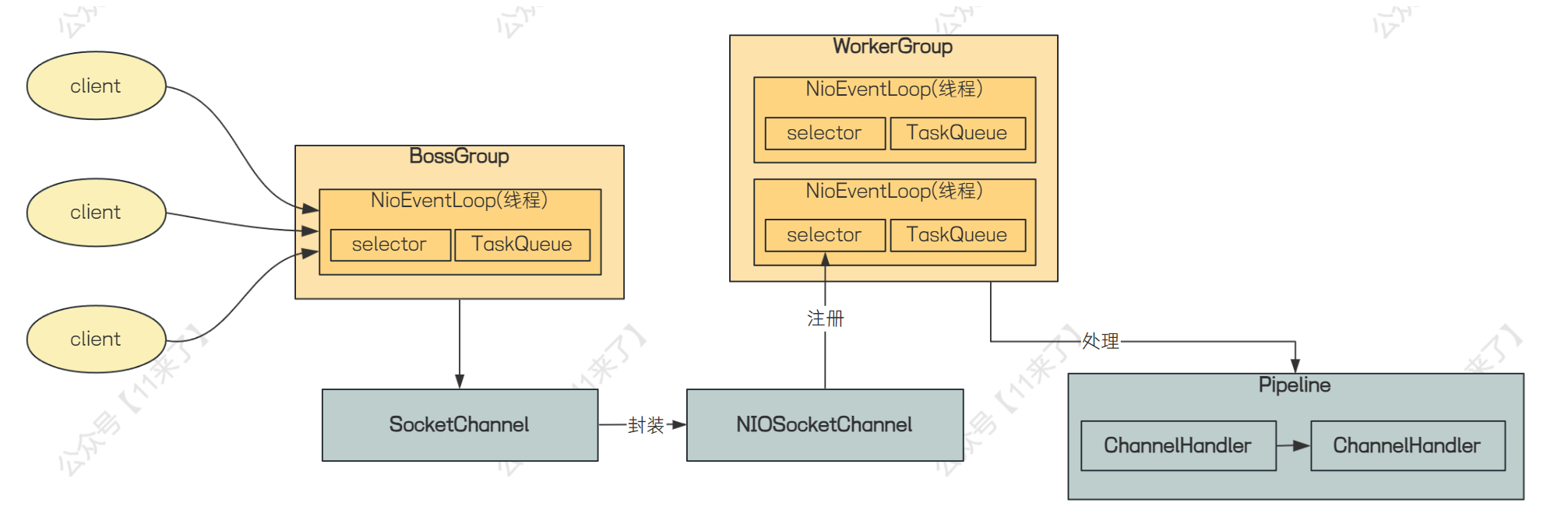
Netty 架构原理图
问到 Netty 了,那么 NIO、BIO、AIO 肯定是要了解的,由于面试突击里之前已经写过这块的内容了,这里就不重复说了
下边说一下 Netty 的架构原理图,从整体架构学习:
Netty 处理流程:
1、BossGroup 和 WorkerGroup 都是线程组,BossGroup 负责接收客户端发送来的连接请求,NioEventLoop 是真正工作的线程,用来响应客户端的 accept 事件
2、当接收到连接建立 Accept 事件,获取到对应的 SocketChannel,封装成 NIOSocketChannel,并注册到 Worker 线程池中的某个 NioEventLoop 线程的 selector 中
3、当 Worker 线程监听到 selector 中发生自己感兴趣的事件后,就由 handler 进行处理
Netty 为什么这么快?
那么 Netty 作为高性能的网络 IO 框架,一定要了解 Netty 在哪些方面保证了高性能:
-
传输:用什么样的通道将数据发送给对方,BIO、NIO 或者 AIO,IO 模型在很大程度上决定了框架的性能。
IO模型的选择- Netty 使用 NIO 进行网络传输,可以提供非阻塞的 IO 操作,极大提升了性能
-
协议:采用什么样的通信协议,HTTP 或者内部私有协议。协议的选择不同,性能模型也不同。相比于公有协议,内部私有协议的性能通常可以被设计的更优。
协议的选择- Netty 支持丰富的网络协议,如 TCP、UDP、HTTP、HTTP/2、WebSocket 等,既保证了灵活性,又可以实现高性能
- 并且 Netty 可以定制私有协议,避免传输不必要的数据,进一步提升性能
-
线程模型:数据报如何读取?读取之后的编解码在哪个线程进行,编解码后的消息如何派发,Reactor 线程模型的不同,对性能的影响也非常大。
线程模型的选择- Netty 使用主从 Reactor 多线程模型,进一步提升性能
-
零拷贝:Netty 中使用了零拷贝,来提升数据传输速度
Netty 中的零拷贝了解吗?
Netty 通过零拷贝技术减少数据复制次数,提升性能!
Netty 的 零拷贝 主要在以下三个方面:
-
Netty 的接收和发送使用堆外内存(直接内存)进行 Socket 读写,不需要进行字节缓冲区的二次拷贝。
-
Netty 提供 CompositeByteBuf 组合缓冲区类,可以将多个 ByteBuf 合并为一个逻辑上的 ByteBufer,避免了各个 ByteBufer 之间的拷贝,将几个小 buffer 合并成一个大buffer的繁琐操作。
-
Netty 的文件传输使用了 FileChannel 的 transferTo 方法,该方法底层使用了
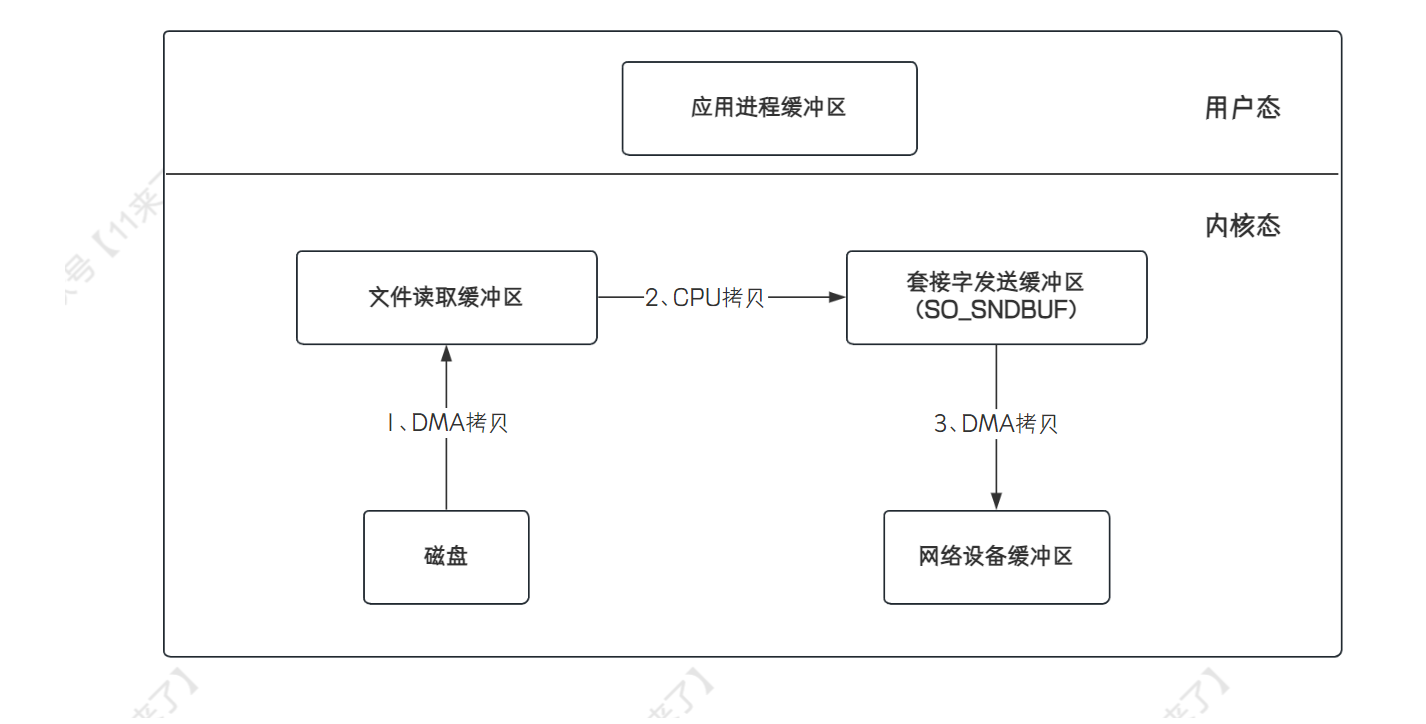
sendfile函数实现了 cpu 零拷贝。sendfile函数通过网络发送数据的流程为:(3次拷贝、2次上下文切换,这里上下文切换是在用户空间发起write操作,此时用户态切换为内核态,write调用完毕后又会从内核态切换回用户态)
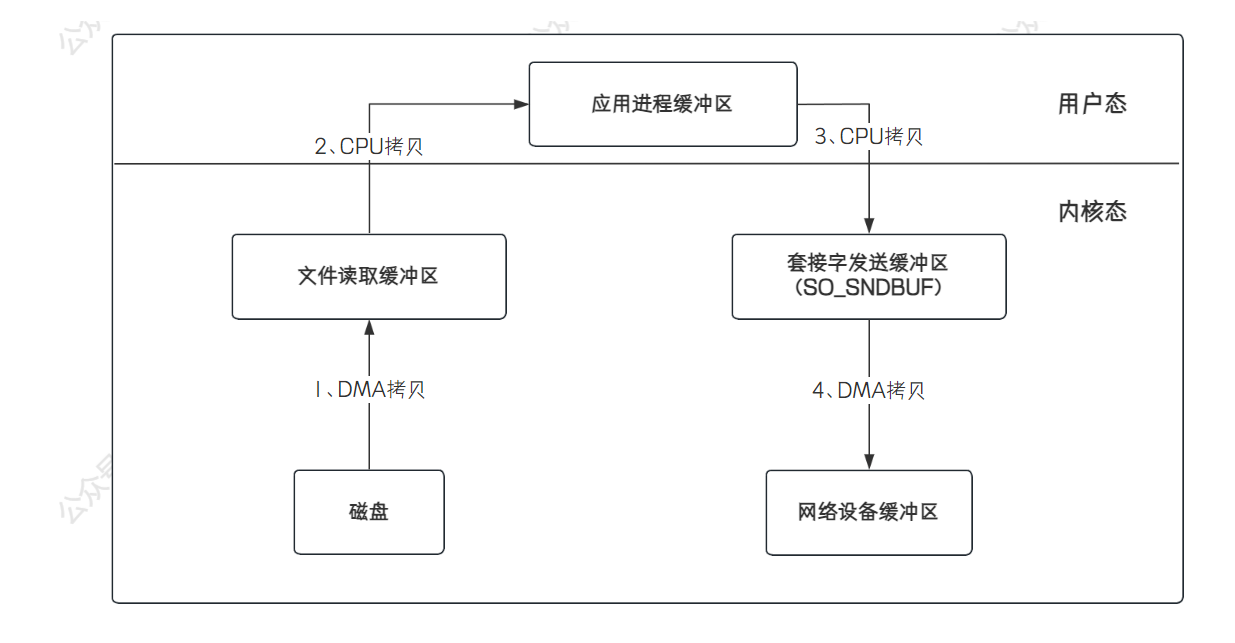
下边画一个直观一些的图片,从
应用程序的角度来看 Netty 的零拷贝:
但是不能只了解零拷贝是怎样的,因为技术是过渡的,还要知道不使用零拷贝时,传统 IO 是怎么传输数据的:
- 传统的 IO 操作会有 4 次拷贝,4 次用户态和内核态之间的切换,因此性能是比较低的
- 这里说一下是
哪 4 次内核态的切换- 首先,应用程序去磁盘读取数据进行发送时,此时会从用户态切换到内核态,通过 DMA 拷贝将数据放到文件读取缓冲区中
- 再从内核态切换到用户态,将文件读取缓冲区的数据通过 CPU 拷贝读取到应用进程缓冲区中
- 再从用户态切换到内核态,将数据从应用进程缓冲区通过 CPU 拷贝放到 Socket 发送缓冲区中,之后的数据会从 Socket 发送缓冲区中通过 DMA 拷贝发送到网络设备缓冲区中
- 操作完成之后,再从内核态切换到用户态
直接内存了解吗?
直接内存(也称为堆外内存)并不是虚拟机运行时数据区的一部分,直接内存的大小受限于系统的内存
在 JDK1.4 引入了 NIO 类,在 NIO 中可以通过使用 native 函数库直接分配堆外内存,然后通过存储在堆中的 DirectByteBuffer 对象作为这块内存的引用进行操作
使用直接内存,可以避免了 Java 堆和 Native 堆中来回复制数据
在上边提到了 Netty 的零拷贝,其中有一种就是使用了 直接内存来实现零拷贝 的,直接内存的特点就是快,接下来看看为什么使用直接内存更快呢?
直接内存使用场景:
- 有很大的数据需要存储,且数据生命周期长
- 频繁的 IO 操作,如网络并发场景
直接内存与堆内存比较:
- 直接内存申请空间耗费更高的性能,当频繁申请到一定量时尤为明显
- 直接内存IO读写的性能要优于普通的堆内存,在多次读写操作的情况下差异明显
直接内存相比于堆内存,避免了数据的二次拷贝。
-
我们先来分析
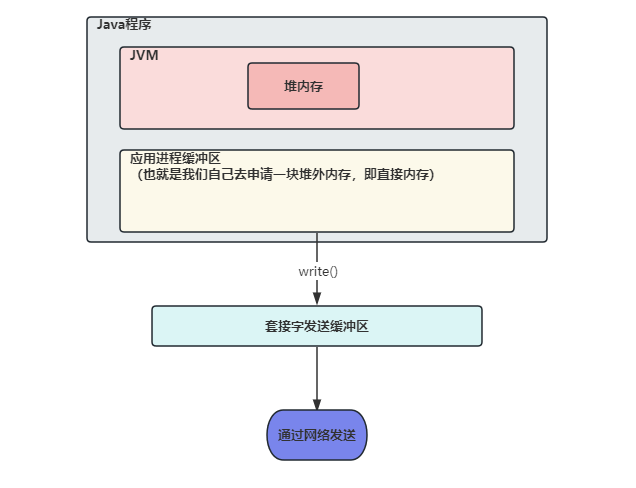
不使用直接内存的情况,我们在网络发送数据需要将数据先写入 Socket 的缓冲区内,那么如果数据存储在 JVM 的堆内存中的话,会先将堆内存中的数据复制一份到直接内存中,再将直接内存中的数据写入到 Socket 缓冲区中,之后进行数据的发送-
为什么不能直接将 JVM 堆内存中的数据写入 Socket 缓冲区中呢?在 JVM 堆内存中有 GC 机制,GC 后可能会导致堆内存中数据位置发生变化,那么如果直接将 JVM 堆内存中的数据写入 Socket 缓冲区中,如果写入过程中发生 GC,导致我们需要写入的数据位置发生变化,就会将错误的数据写入 Socket 缓冲区
-
-
那么如果使用直接内存的时候,我们将
数据直接存放在直接内存中,在堆内存中只存放了对直接内存中数据的引用,这样在发送数据时,直接将数据从直接内存取出,放入 Socket 缓冲区中即可,减少了一次堆内存到直接内存的拷贝
直接内存与非直接内存性能比较:
public class ByteBufferCompare {public static void main(String[] args) {//allocateCompare(); //分配比较operateCompare(); //读写比较}/*** 直接内存 和 堆内存的 分配空间比较* 结论: 在数据量提升时,直接内存相比非直接内的申请,有很严重的性能问题*/public static void allocateCompare() {int time = 1000 * 10000; //操作次数,1千万long st = System.currentTimeMillis();for (int i = 0; i < time; i++) {//ByteBuffer.allocate(int capacity) 分配一个新的字节缓冲区。ByteBuffer buffer = ByteBuffer.allocate(2); //非直接内存分配申请}long et = System.currentTimeMillis();System.out.println("在进行" + time + "次分配操作时,堆内存 分配耗时:" +(et - st) + "ms");long st_heap = System.currentTimeMillis();for (int i = 0; i < time; i++) {//ByteBuffer.allocateDirect(int capacity) 分配新的直接字节缓冲区。ByteBuffer buffer = ByteBuffer.allocateDirect(2); //直接内存分配申请}long et_direct = System.currentTimeMillis();System.out.println("在进行" + time + "次分配操作时,直接内存 分配耗时:" +(et_direct - st_heap) + "ms");}/*** 直接内存 和 堆内存的 读写性能比较* 结论:直接内存在直接的IO 操作上,在频繁的读写时 会有显著的性能提升*/public static void operateCompare() {int time = 10 * 10000 * 10000; //操作次数,10亿ByteBuffer buffer = ByteBuffer.allocate(2 * time);long st = System.currentTimeMillis();for (int i = 0; i < time; i++) {// putChar(char value) 用来写入 char 值的相对 put 方法buffer.putChar('a');}buffer.flip();for (int i = 0; i < time; i++) {buffer.getChar();}long et = System.currentTimeMillis();System.out.println("在进行" + time + "次读写操作时,非直接内存读写耗时:" +(et - st) + "ms");ByteBuffer buffer_d = ByteBuffer.allocateDirect(2 * time);long st_direct = System.currentTimeMillis();for (int i = 0; i < time; i++) {// putChar(char value) 用来写入 char 值的相对 put 方法buffer_d.putChar('a');}buffer_d.flip();for (int i = 0; i < time; i++) {buffer_d.getChar();}long et_direct = System.currentTimeMillis();System.out.println("在进行" + time + "次读写操作时,直接内存读写耗时:" +(et_direct - st_direct) + "ms");}
}
这篇关于【面试突击】深挖网络 IO 面试实战的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





