本文主要是介绍HNU-数据挖掘-实验1-实验平台及环境安装,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
数据挖掘课程实验
实验1 实验平台及环境安装
计科210X 甘晴void 202108010XXX

文章目录
- 数据挖掘课程实验<br>实验1 实验平台及环境安装
- 实验背景
- 实验目标
- 实验步骤
- 1.安装虚拟机和Linux平台,熟悉Ubuntu环境。
- 2.在Linux平台上搭建Python平台,并安装Python环境工具anaconda。
- 3.掌握Anaconda下的Python环境安装,创建名称为emoji的python3.7环境。
- 4.熟练安装pycharm和jupyter notebook。
- 5.掌握pip和conda命令安装常用软件包。比如numpy、pandas、tensorflow、 h5py、mygene matplotlib、seaborn、umap-learn等。
实验背景
Python 是一个高层次的结合了解释性、编译性、互动性和面向对象的脚本语言。Python 是 FLOSS(自由/开放源码软件)之一。Python 的设计具有很强的可读性,相比其他语言经常使用英文关键字,其他语言的一些标点符号,它具有比其他语言更有特色语法结构。Python的最大的优势之一是丰富的库,跨平台的,在UNIX,Windows和Macintosh兼容很好。
实验目标
在Linux平台下安装、配置python环境和相关软件。
实验步骤
1.安装虚拟机和Linux平台,熟悉Ubuntu环境。
(1)虚拟机使用Oracle VM VirtualBox。之前计算机系统和操作系统课程也使用的该平台。
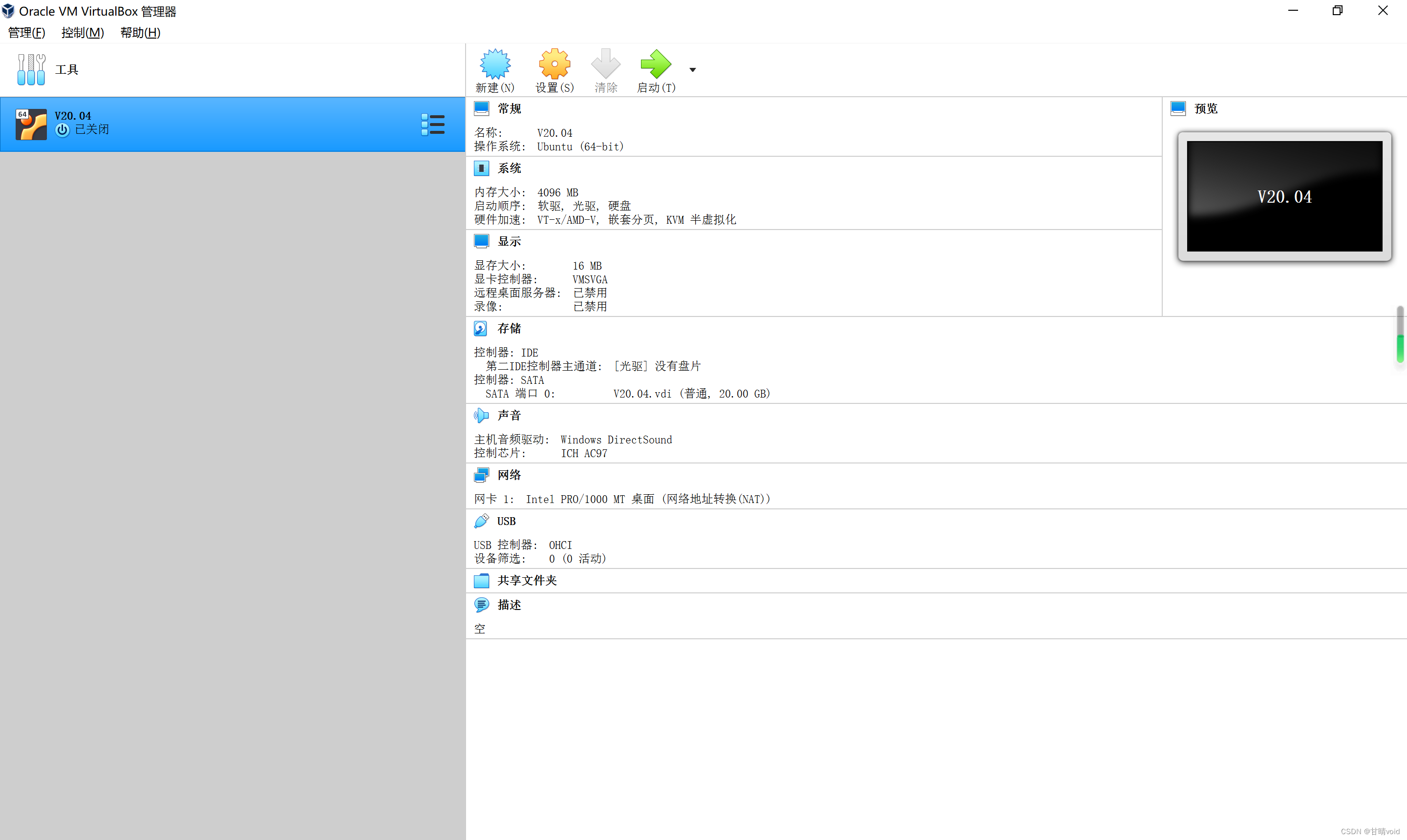
(2)创建Linux操作系统64=位。使用xubuntu20.04版本。
(3)安装完系统之后立加装扩展功能。
2.在Linux平台上搭建Python平台,并安装Python环境工具anaconda。
Linux自带python平台,在终端输入
python3
查看本地python环境,得知是python3.8环境。
首先了解anaconda与miniconda的区别。
Anaconda是一个包含了conda、Python和超过150个科学包及其依赖项的科学Python发行版。它具有可视化图形用户界面(Anaconda Navigator)并且为了方便新手使用,预先包含了大量的库,如NumPy, Pandas, Scipy, Matplotlib等。
相较之下,Miniconda更加轻量级。它只包含了Python和Conda,但并没有预装其他的库。Miniconda用户需要手动安装他们需要的包,这使得Miniconda的环境更为简洁,可以根据实际需求来安装必要的包,避免不必要的存储占用。
考虑到作为虚拟机的Linux系统实际上有的存储空间并不大,所以打算安装miniconda替代anaconda。
(1)访问miniconda的官网https://docs.conda.io/projects/miniconda/en/latest/获取信息
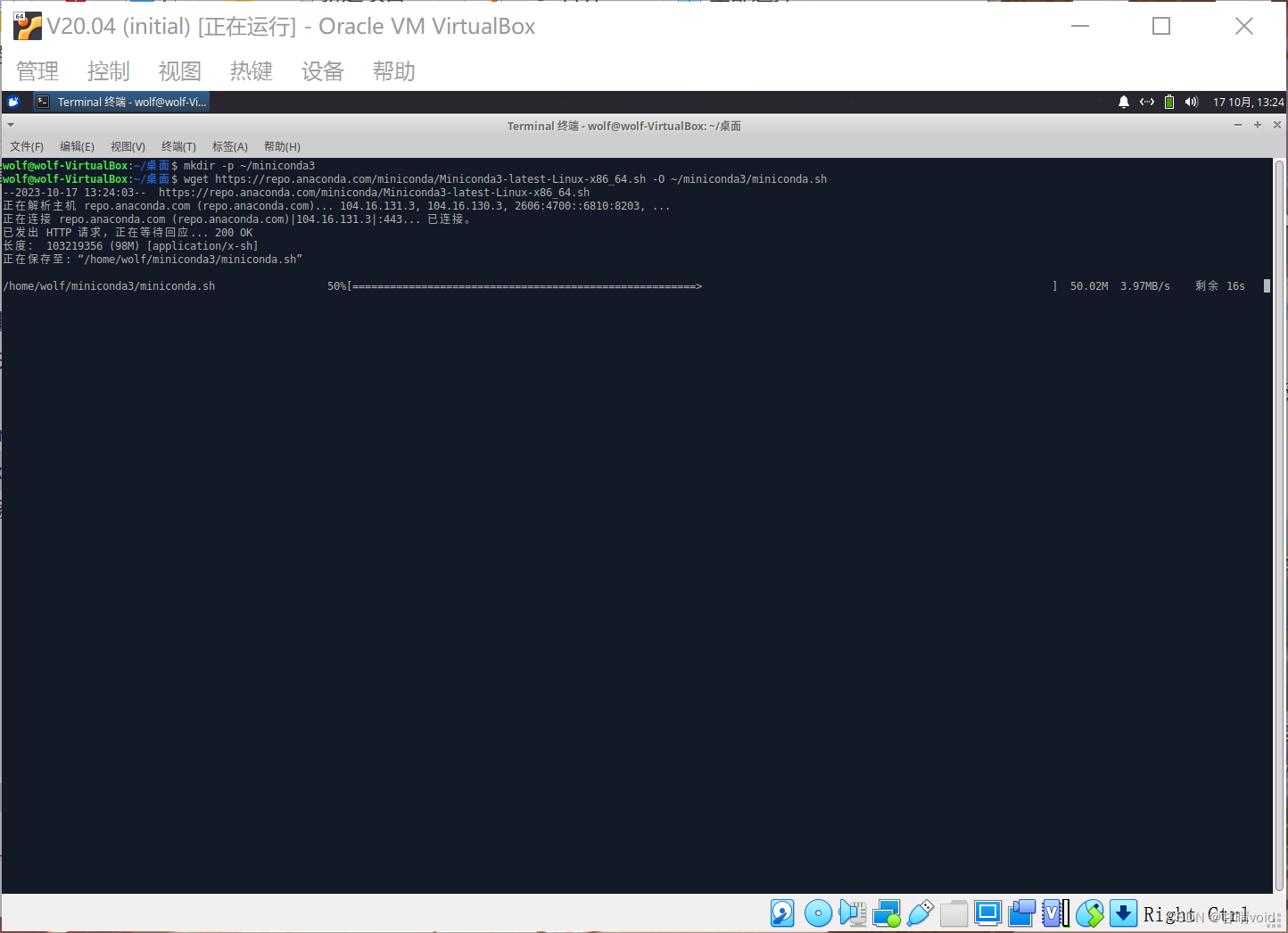
(2)在Linux下使用如下指令进行安装并初始化。
mkdir -p ~/miniconda3
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh -O ~/miniconda3/miniconda.sh
bash ~/miniconda3/miniconda.sh -b -u -p ~/miniconda3
rm -rf ~/miniconda3/miniconda.sh
~/miniconda3/bin/conda init bash
~/miniconda3/bin/conda init zsh
步骤截图如下
3.掌握Anaconda下的Python环境安装,创建名称为emoji的python3.7环境。
安装了最新版本的miniconda之后,再次打开终端,会显示一个默认的(base)在前面,形如以下。
(base) wolf@wolf-VirtualBox:~/桌面$
表示miniconda基本安装时 成功的,目前处于conda的环境下。
此时再次查看python3的版本,发现不知什么时候升级成3.11了。通过查阅资料发现,miniconda会自动为我们配置python环境,不需要手动再下载python版本。
使用以下指令配置环境。
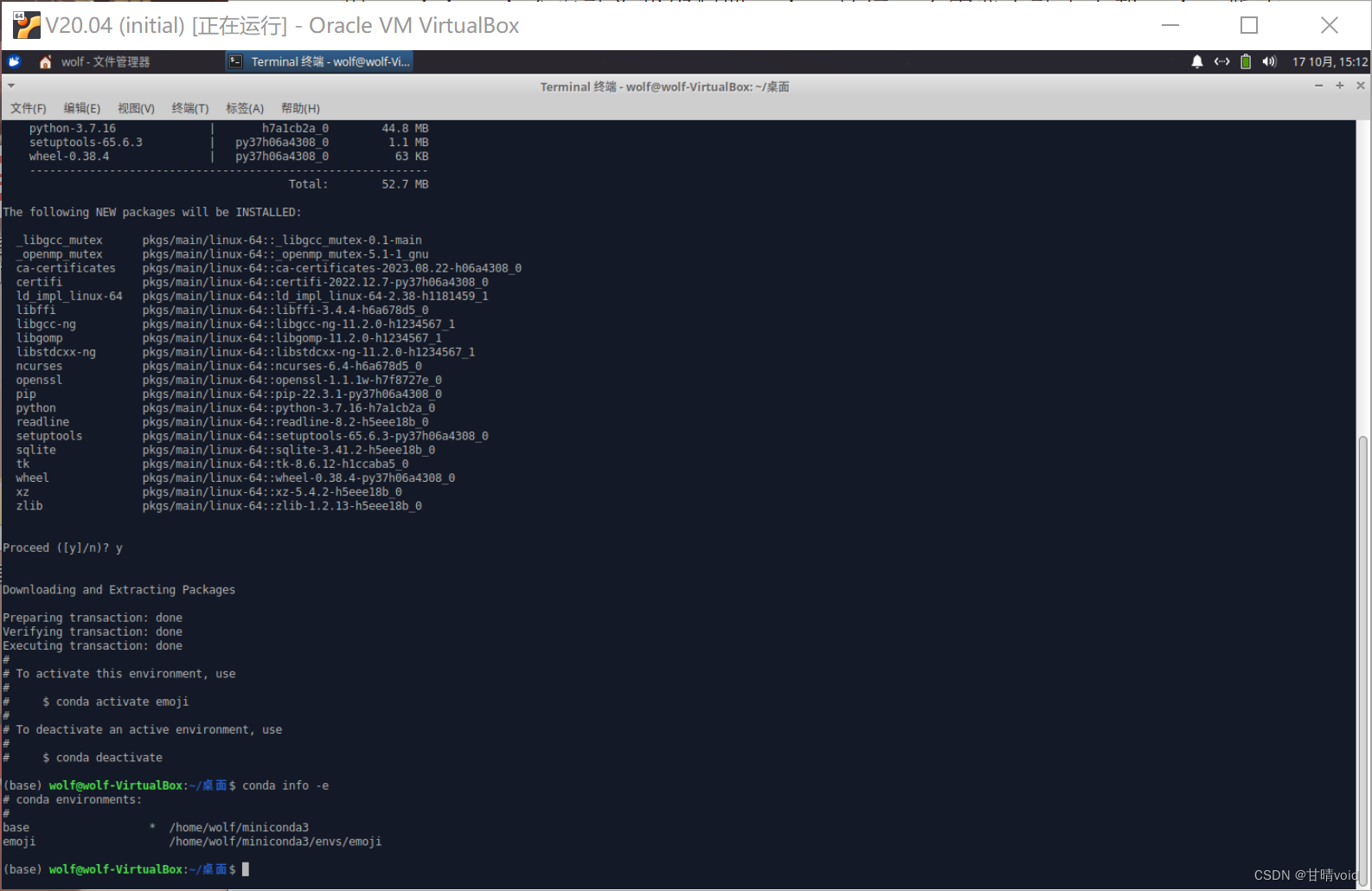
conda create -n emoji python=3.7
安装完成后使用如下指令查看
conda info -e
发现出现了原来的基础环境(base)和新建的环境(emoji)
此时若使用
conda activate emoji //进入
conda deactivate //退出
conda config --set auto_activate_base true
conda config --set auto_activate_base false //取消自动进入
★这里还应该加一步换源(换用清华源)
pip install pip -U
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
4.熟练安装pycharm和jupyter notebook。
使用Linux访问pycharm官方网址
https://www.jetbrains.com/pycharm/download/?section=linux
下载Linux下的pycharm,注意不要下载成Professional版本,要下载community版本的。
安装完毕后找到位置,解压该压缩包。
tar -zxvf pycharm-community-2023.2.3.tar.gz
进入bin文件夹
./pycharm.sh
即可进行安装,安装后就可以打开pycharm,可以看见与windows下是一致的。
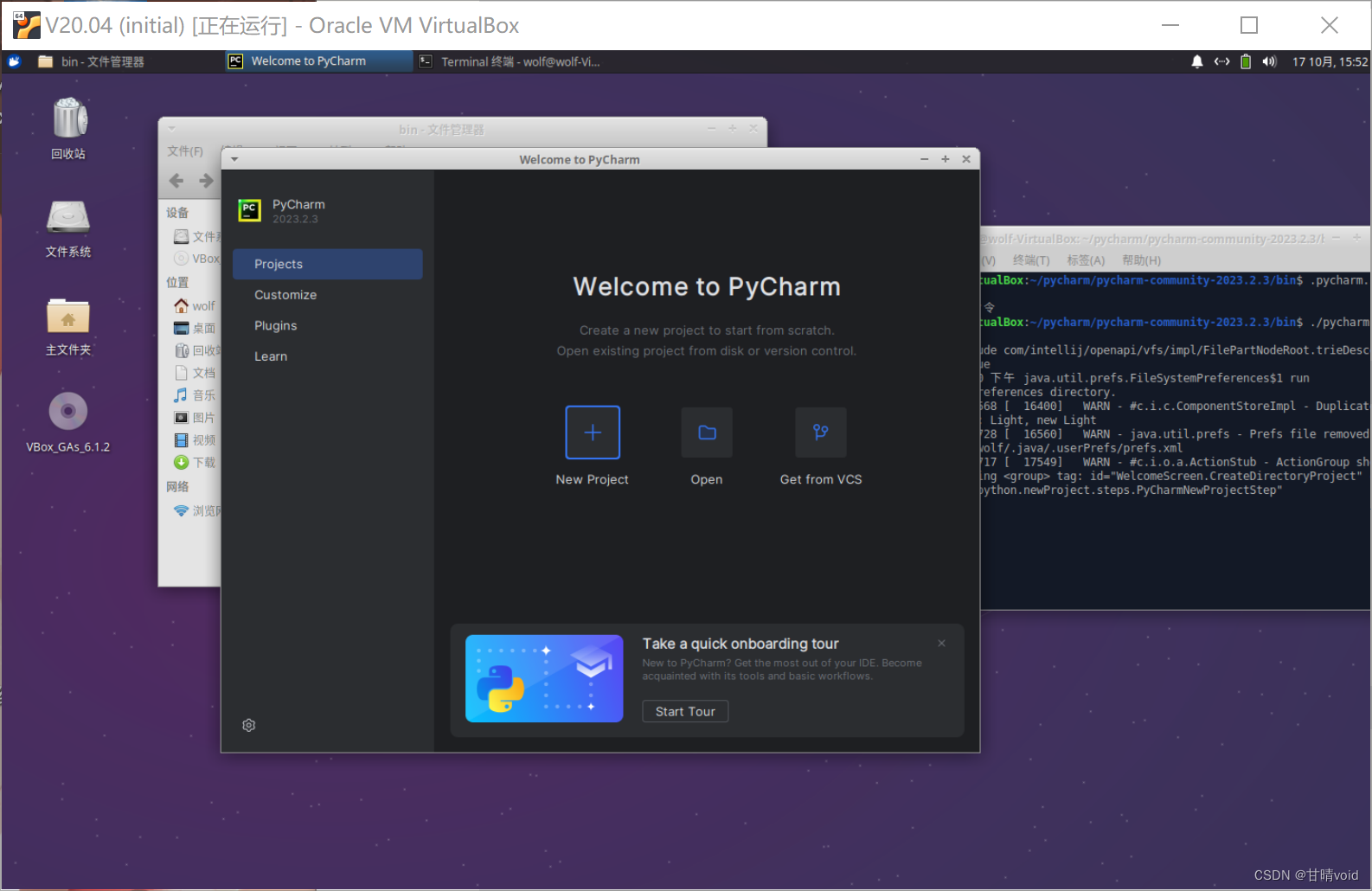
接下来为pycharm配置conda的环境。即pycharm作为编辑器,打开conda环境下的python工程。选择conda环境和对应版本即可。
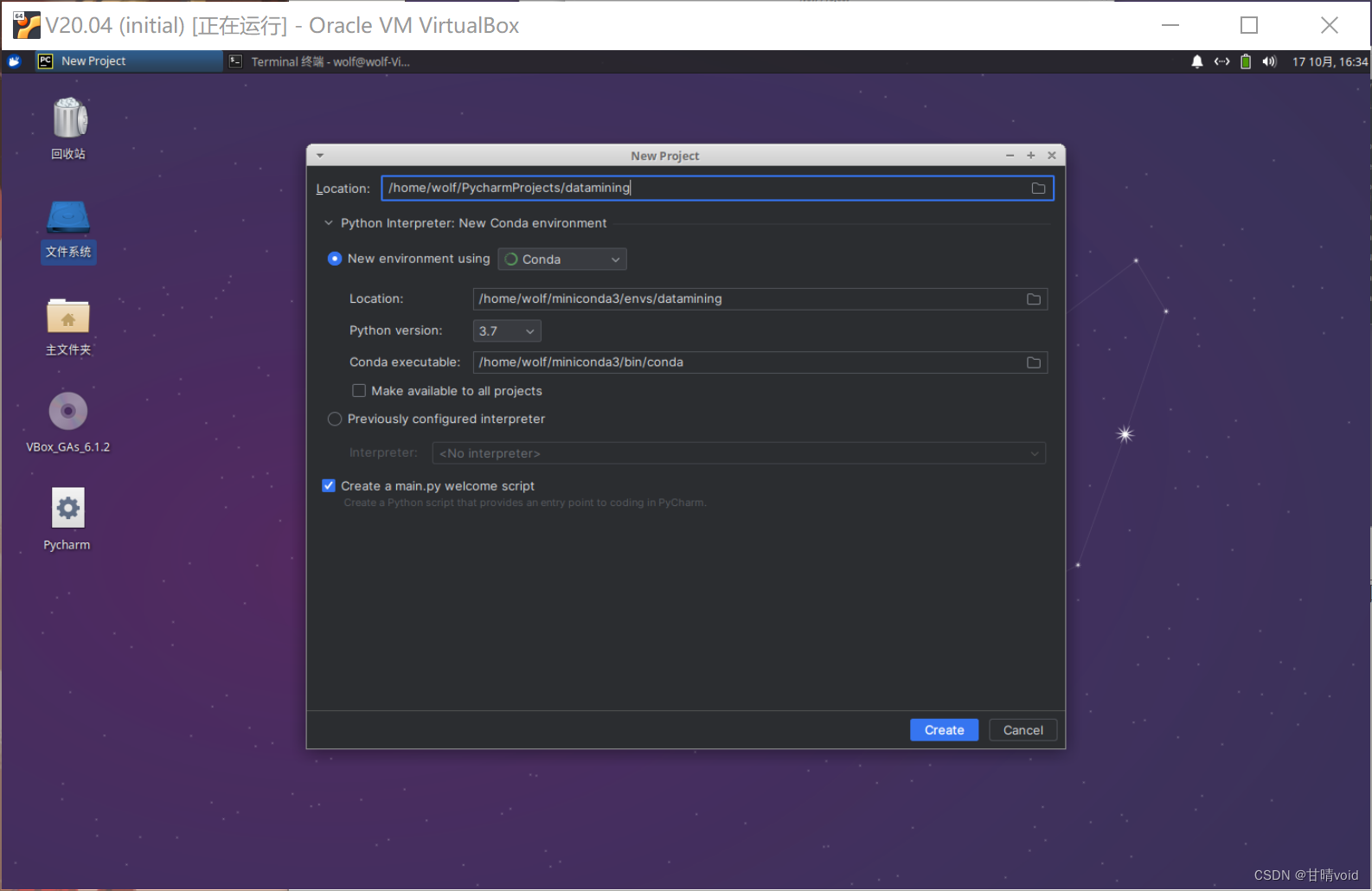
这里我们发现很不方便,每次打开pycharm都需要到里面去打开,故可以创建桌面的快捷方式。
关于jupyter-notebook,这个在我的windows系统下的anaconda环境中是已经存在的,我认为再安装jupyter的意义不是很大,故没有在这里安装。需要用到的时候我会去再进行安装的。
5.掌握pip和conda命令安装常用软件包。比如numpy、pandas、tensorflow、 h5py、mygene matplotlib、seaborn、umap-learn等。
这一步就比较基础了,在之前windows下的anaconda环境中,我们也做过类似的事情。接下来逐个安装即可。
进入emoji环境。
conda activate emoji
conda install numpy
conda install pandas
pip install tensorflow #使用conda安装失败
conda install h5py
conda install matplotlib
conda install seaborn
pip install umap-learn #使用conda安装失败
conda list
出现以下三个done这样就表示这个包安装成功了。
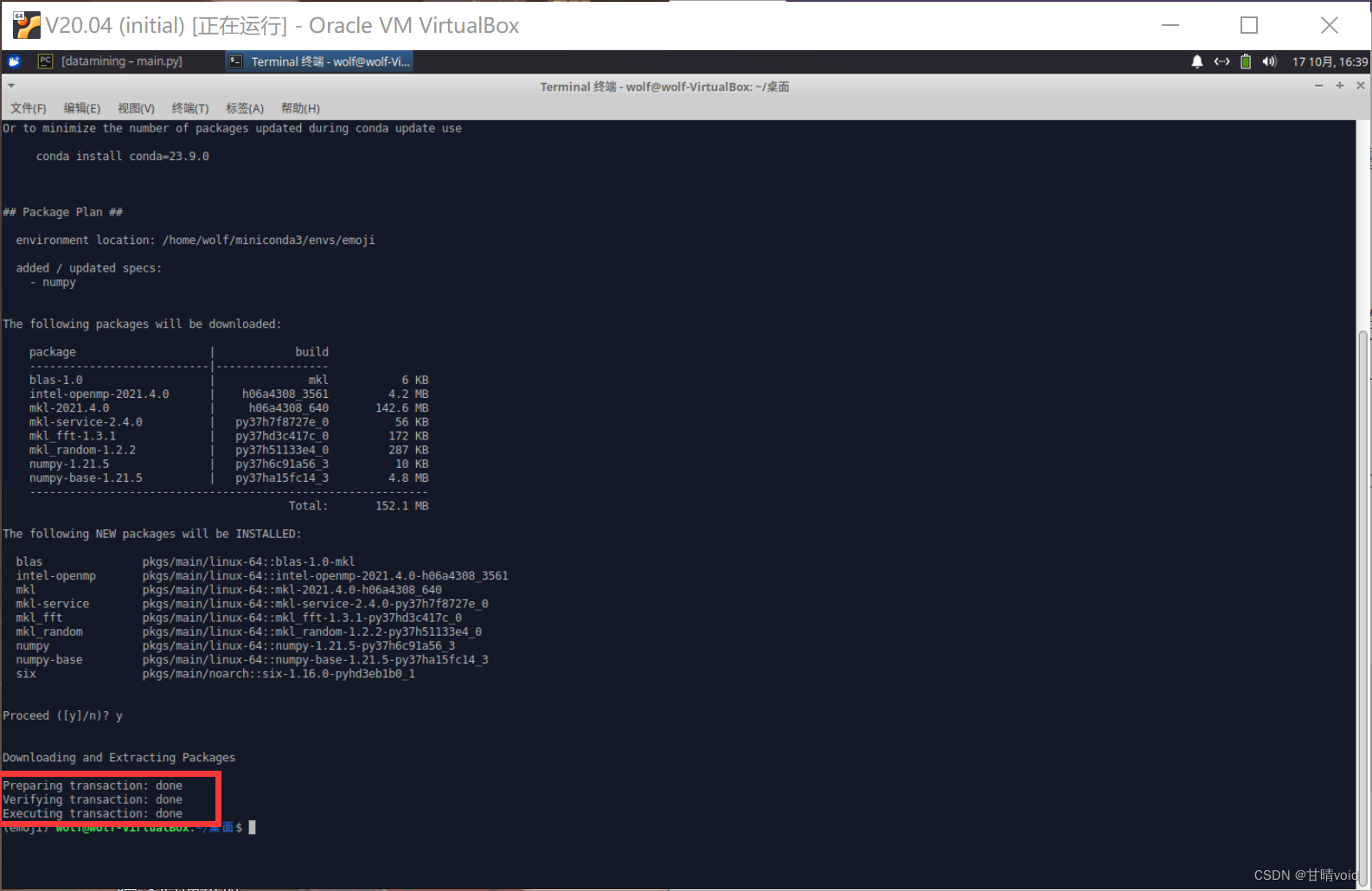
其中tensorflow没有成功安装,故使用pip进行安装。
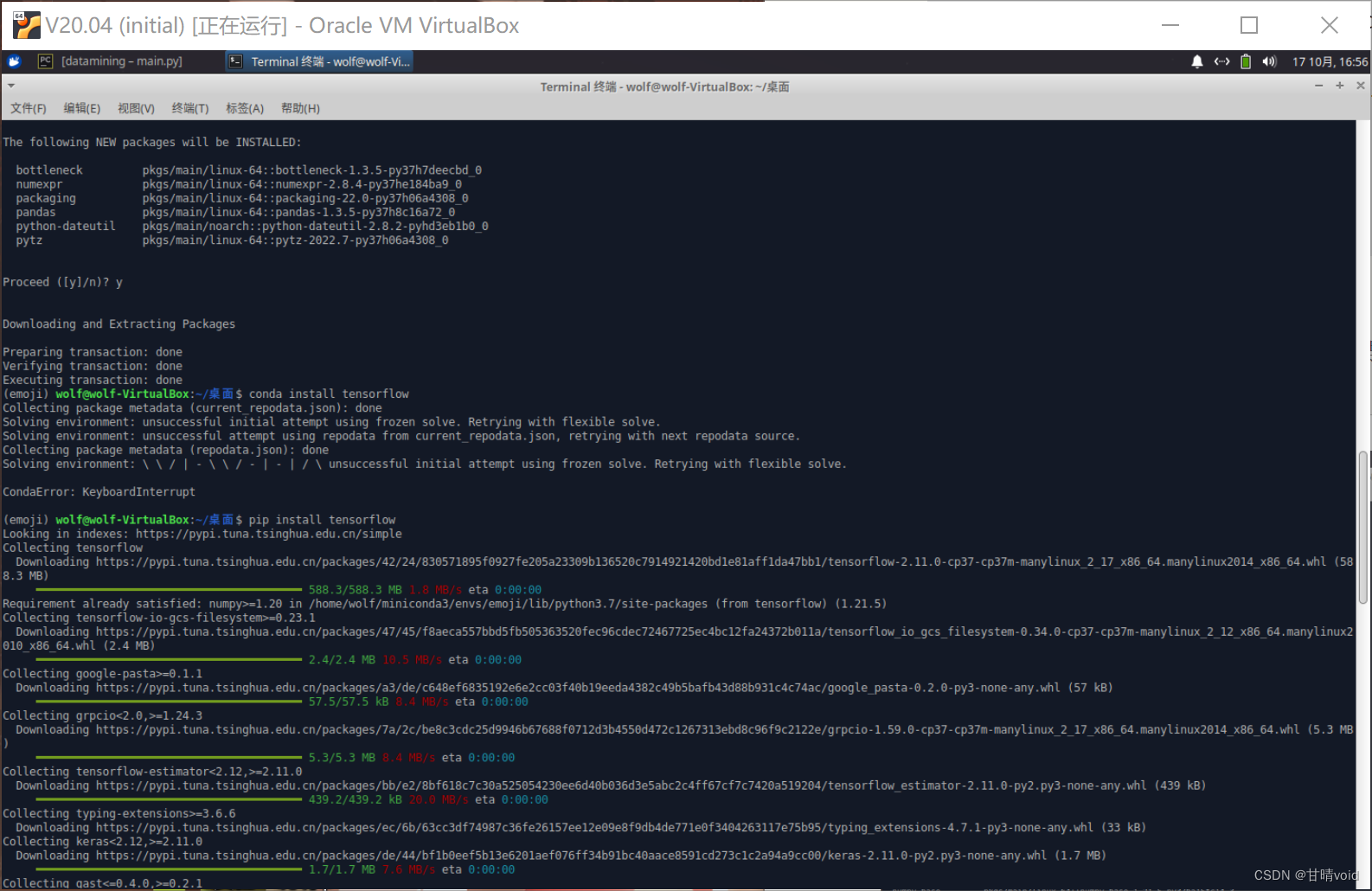
其他都成功安装。
安装完毕之后使用
df -TH
conda list
分别查看Linux文件系统剩余空间和conda列表
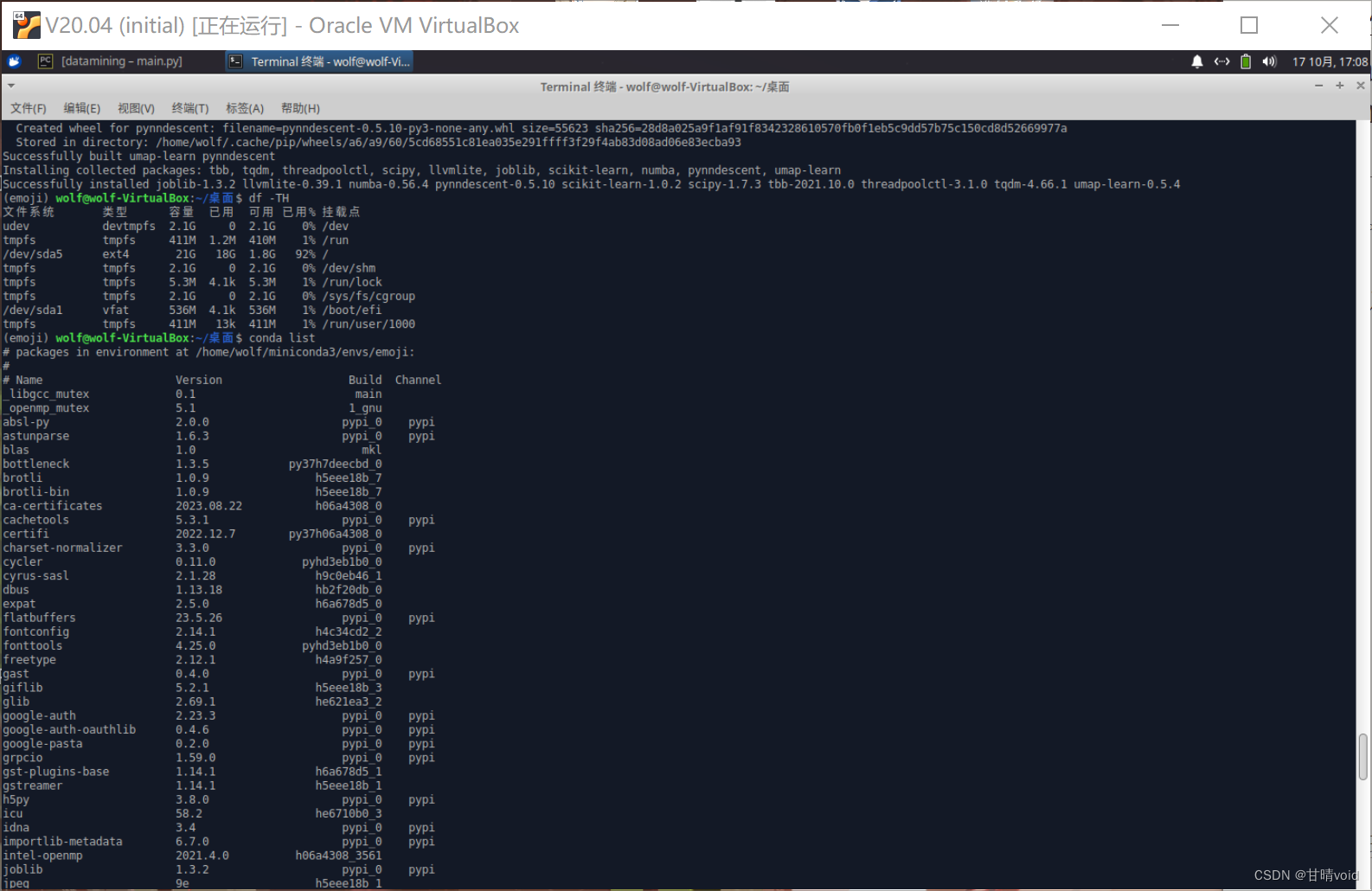
可以看到我20G的空间啊!!!都被装满了。
这篇关于HNU-数据挖掘-实验1-实验平台及环境安装的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








