本文主要是介绍从潮汐架构和安第斯大模型,看智能手机的未来演进,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
好久没聊手机了,今天聊聊手机。
最近这段时间,手机厂商纷纷发布了自家最新的旗舰系列。其中,有一些技术,蛮值得关注的。
大家都知道,手机行业是出了名的“内卷”,厂商之间的竞争非常激烈。但从本质来说,让人眼前一亮的创新,其实是越来越少的。所以,很多网友调侃,现在的手机发布会,就像相机发布会,除了聊拍照,还是聊拍照。
说实话,手机技术经过多年的发展,已经非常成熟。想要有颠覆式的创新,确实会越来越难。
但大家如果细致观察的话,会发现,手机已经进入了一个微创新时代。颠覆式创新也许不多,但厂商在性能提升和功能拓展方面,仍然是在不断向前探索的。
前几天,OPPO发布了自家的Find X7系列手机。我关注到它所提及的两个技术,非常有代表性,那就是——潮汐架构和安第斯大模型。
我个人觉得,潮汐架构和安第斯大模型,隐约预示了智能手机未来发展的两个重要趋势。
什么趋势呢?且听我逐一解读。
█ 潮汐架构
首先说说潮汐架构。
智能手机发展到今天,其实本质上就是一个用户侧(端侧)算力及交互平台。它集算力与通信能力于一体,搭配了摄像头、触摸屏、传感器、音频等“插件”,让用户可以实现多种多样的互联网应用场景,包括社交、视频、游戏等。
手机的算力,不仅直接影响到OS和App的运行速度,也关系到视频、影像以及游戏等核心能力的体验,是整个手机性能的基础。手机算力又由什么决定呢?当然是手机SoC主芯片。
这些年,手机的升级演进,一直都是围绕SoC主芯片进行的。每当有新的芯片平台发布,各大手机厂商都会及时跟进,推出一批新的旗舰型号。

5G SoC芯片(MediaTek)
以前,手机厂商对于芯片,基本上就是拿来就用。就像发动机一样,直接往车里塞,能跑就行。现在,随着市场竞争的不断加剧,为了更好地发挥芯片的能力,也为了让用户有明显的体验差异化提升,手机厂商们开始投入更多资源,对芯片进行适配、调优。
OPPO作为手机一线大厂,在芯片联合研发方面很早就采取了行动,也积累了丰富的经验。这次,他们一如既往地与MediaTek进行深度合作,成立联合芯片技术实验室,针对天玑9300移动平台进行定制化设计。
而潮汐架构,就是深度联合设计的最新成果之一。
想要解释什么是潮汐架构,我们还是要从手机的核心原理说起。
手机,其实就是一台微型计算机。它的SoC主芯片里面,包括CPU和GPU等计算芯片。CPU和GPU的里面,又包括了运算单元和控制单元等。
手机和普通PC一样,也是遵照著名的冯·诺依曼架构进行工作。这种架构,属于存算分离。运算单元负责计算,存储器负责存储。计算时,需要先将数据从存储器调用到运算单元,完成计算后,再送回存储器。
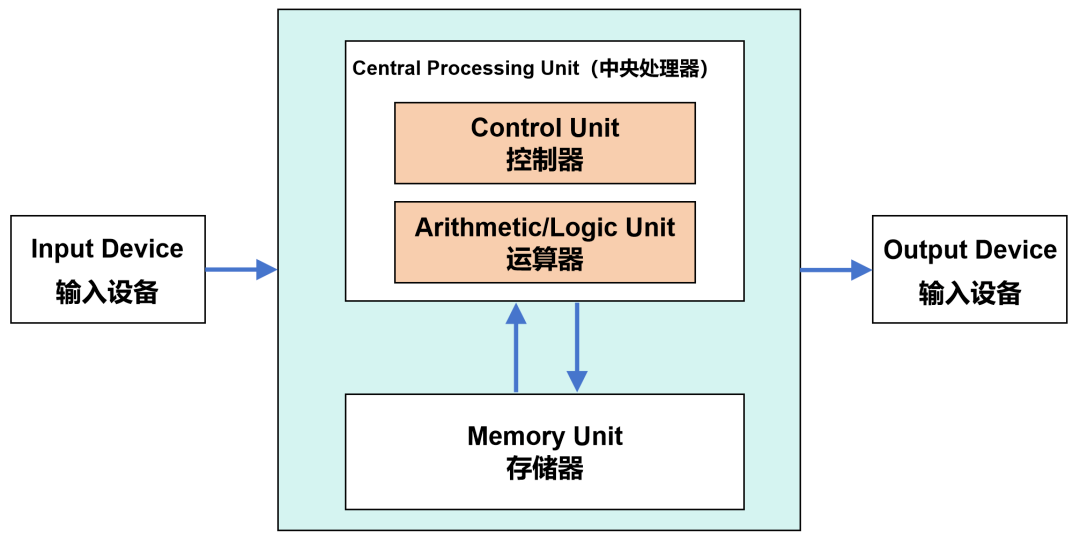
冯·诺依曼架构
随着摩尔定律的发展,手机芯片的CPU和GPU都有了长足的进步,性能非常强劲。但是,存储器的性能,却始终没有办法跟上CPU和GPU的步伐。这是冯·诺依曼架构最主要的瓶颈。
性能越强的存储技术,价格成本就越高。于是,就出现多级存储架构。除了传统ROM/RAM之外,又有了缓存。缓存,还分为L1/L2/L3三级。说白了,缓存就是运算单元和传统存储之间的一个过渡。它的性能很强,读写速率快,但是成本高,所以容量不大。
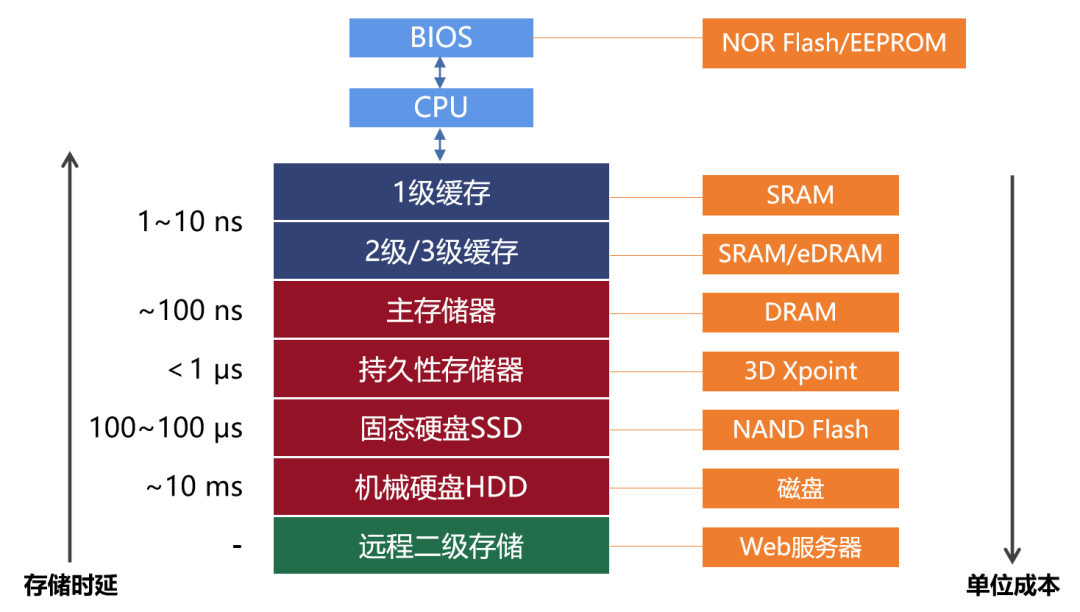
多级存储架构
一直以来,传统手机厂商的技术区,是在Flash存储和主存储器(DDR或UFS层级)。而一级缓存到系统缓存这几个层级,是芯片公司的技术区,存在难以逾越的技术壁垒。
OPPO提出的潮汐架构,打破了这个壁垒,往前又迈了一大步,直接参与到SoC的SLC(系统级缓存)设计之中。CPU核之间的共用数据缓存,以及CPU与异构核(例如GPU)之间的缓存,都可以被OPPO定制化设计。
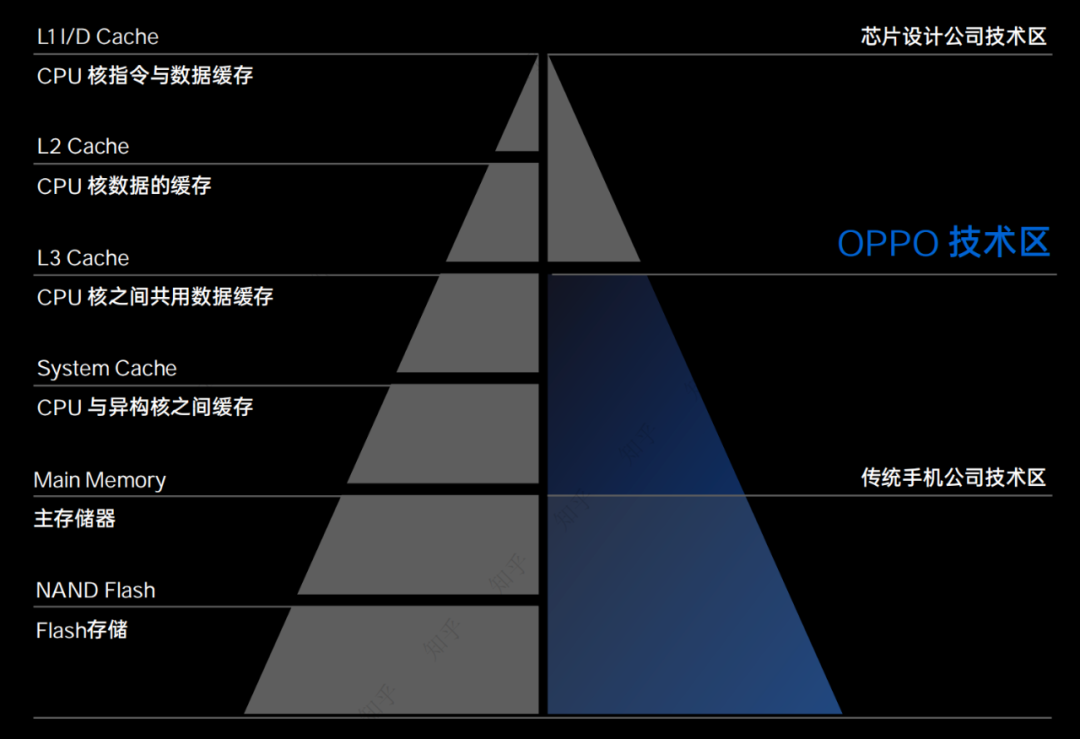
OPPO可以根据应用侧的需求,合理规划CPU、GPU等运算单元对SLC缓存的使用量和利用方式,从而最大程度地发挥硬件资源的性能,实现极致的软硬件协同。
举个例子,如果我们把CPU、GPU看作是“算力大脑”,那么,SLC就是给大脑输送数据的“高速公路”。
传统方案里,芯片厂商无法确定各个运算单元的数据量比例。于是,只能采用固定分配方案。当手机使用不同的应用时,就会出现“部分公路拥塞、部分公路空闲”的情况。
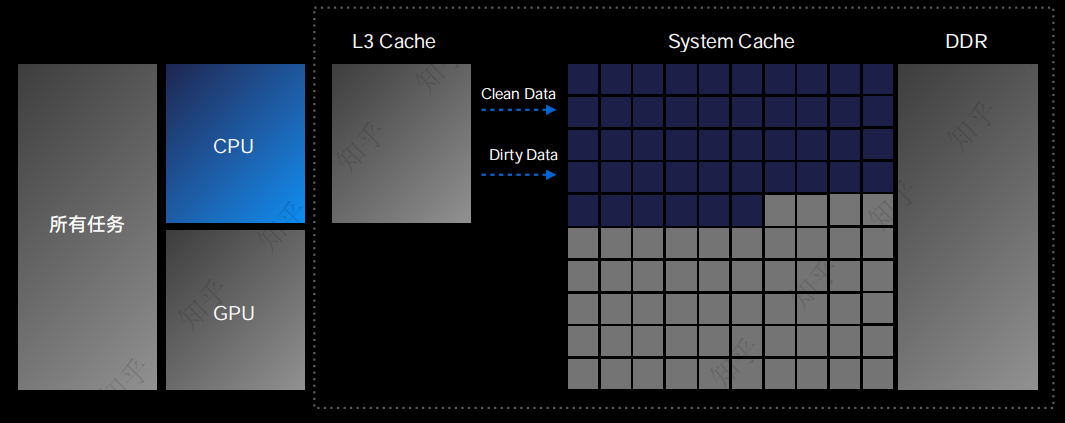
有了潮汐架构,OPPO可以根据应用场景的不同,灵活调整SLC缓存的配比,实现车道的合理优化,进而让CPU和GPU发挥最强性能。
比如,在运行大型手游时,图像渲染的工作会更多。这时,可以给GPU分配更多的系统缓存,从而降低对DDR和UFS的读写频率。应用运行速度能够得到明显提升,计算链路整体能效也有明显改善。
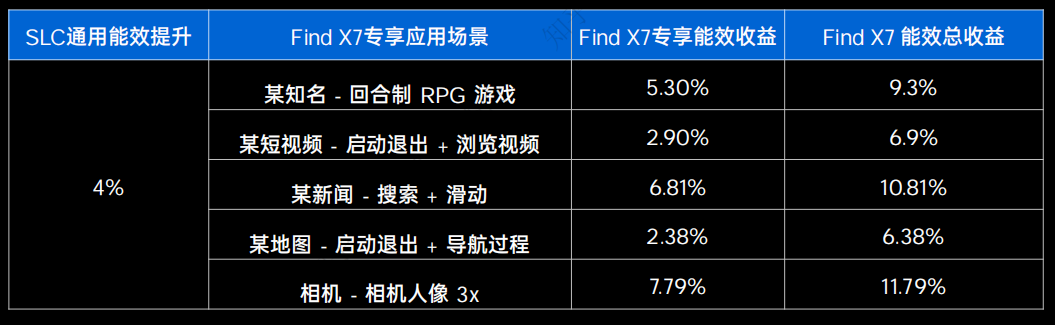
经过测算,潮汐架构SLC技术可以为Find X7带来4%的通用能效提升,以及2.38~7.79%的专享应用场景能效提升。整体的平均能效提升,约为8%。这是非常了不起的成就。
Find X7发售后,我第一时间下单了一台。
经过多日的实际使用,我明显能够感受到系统在应用启动、加载和切换时,响应速度更快、更流畅。
天玑9300是全大核架构(4超大核+4大核),性能本来就很强。潮汐架构的加持,让手机的性能如虎添翼,有比其它旗舰更出色的体验。

长期以来,安卓机在启动性能一致性上都不如苹果手机。这次,Find X7彻底打破了这一魔咒。它始终可以保持极高的流畅度,即使后台有多个App运行,也能够极速启动新App,启动速度稳如直线。这就是得益于芯片强劲的性能,以及潮汐架构的深度优化加持。
潮汐架构也帮助提升了Find X7的续航。根据实测数据,基于潮汐架构以及一系列新技术,Find X7的续航比Find X6标准版提升了20%。
最近几年,手机厂商在芯片联合调校上的投入,变得越来越大。参与的深度,也越来越深。
厂商们都意识到,在芯片平台既有性能的基础上,进行深入挖潜,是实现差异化竞争的有力手段。在OPPO的引领下,相信会有更多的厂商走上“联合调校”这条路。相关的技术创新,也会越来越多地出现在我们面前。
█ 安第斯大模型
潮汐架构是算力底层技术。接下来,我们看看算力最有潜力的应用——大模型。
刚刚过去的2023年,被公认为是大模型年。以ChatGPT为代表的AIGC大模型,火遍全球,成为最引人注目的科技热点。
手机终端作为普通用户最常用的数码设备,在拥抱大模型上也不甘落后。2023年下半年开始,陆续有手机型号开始引入大模型,并推出一些AIGC应用。
OPPO Find X7系列所采用的安第斯大模型(AndesGPT),是他们自研的最新技术成果,是行业首个端侧部署70 亿参数大模型。
这个大模型具备对话增强、个性专属、端云协同三大尖刀能力,从基础能力到应用落地,都相比竞争对手有更多的看点。
从参数规模上来看,安第斯大模型一共有3个版本:

Tiny版本,拥有至多70亿参数,可以直接部署在Find X7这样的终端上,特点是轻量高效,支持离线运行,且隐私数据隔离。
Turbo版本,700亿参数,可以部署在安第斯智能云,支持快速响应,体验更加均衡,也能够适配多个场景。
Titan版本,参数最多,可以达到1800亿,同样可以部署在云端。庞大的参数规模,使其完全可以胜任深度推理工作以及高度复杂任务,效果最优。
手机本地部署模型不能支持更大的参数,因为参数越多,对内存的占用就越大。
本地模型70亿参数,搭配云端更大的模型,通过加密通信,可以实现端云协同,灵活支撑多样化的AI应用。
OPPO在人工智能领域起步较早。2018年,他们就成立了人工智能团队。2020年,他们将语音、建议、指令、识屏等能力进行整合,推出了对话式人工智能助手——小布助手。次年,就实现了上亿月活。
大模型崛起后,OPPO基于自己多年的技术沉淀和数据积累,很快跟进,并推出了安第斯大模型。2023年9月,安第斯大模型小试牛刀,在SuperCLUE能力排行榜知识与百科评比中,获得98.33的高分,仅次于GPT4,位列国内模型第一。
大模型的参数规模是基础,关键还是要看应用落地。
在Find X7发布会上,OPPO提到了智能摘要、AIGC消除、闪速抠图等应用。我试用了一下,效果确实不错,响应速度很快,处理的质量也很高,确实达到了真正的智能水平。

前面我说过,手机是一个交互工具。在数字时代,人与数字世界之间最主要的沟通渠道,就是手机。很多的应用,都是通过手机实现的。所以,AI与手机的结合,充满了无限的想象空间。
大模型在手机落地,其实会分为多个阶段。
首先,最浅的阶段,是像ChatGPT一样,通过与App之间的SDK接口,进行调用。这种能力调用比较生硬,玩法也很有限。
再深一点,是手机本地部署外部大模型。融合度虽然有提升,但毕竟是非自研大模型,简单的植入,无法和厂商自有的独立硬件体系相结合,也很难发挥处理器的推理性能。
更深一点,就是像OPPO这样,搞自研大模型。自研大模型彻底突破了底层API和功能限制,与硬件体系结合更加紧密,开发自由度也更高,研发进度也不受外部限制。
这种方式,在落地玩法上,也更具灵活性。它属于系统级的融合,在系统生态底层进行大模型能力扩展,可以实现原生AI能力。
换言之,OPPO的安第斯自研大模型,是可以对操作系统、所有原生App,以及所有硬件进行AI赋能的。在拍照、音视频录制、知识整理、交互增强等方面,大模型都可以提供辅助,成为真正的智能管家。用户的工作效率和生活品质可以大幅提升,相互之间的沟通乐趣也无限增加。
█ 最后的话
很多人都说,未来的手机之争,就是智能算力之争。谁家的终端AI算力强、算法好,谁就掌握了主动权。
我非常认同这一点。潮汐架构和安第斯大模型所代表的趋势,分别是:
1、手机厂商在芯片联合调校上,将会投入更多资源。相比自研芯片,联合调校更有可行性,能够发挥手机厂商和芯片厂商各自的优势。
2、手机在应用侧,将会持续加大与AI的融合。手机的端侧AI能力,很可能会重塑现在所有的App应用,让手机变成真正的“智能手机”。
面向2024,希望手机技术的微创新,能从量变走向质变,带来更多的惊喜。

这篇关于从潮汐架构和安第斯大模型,看智能手机的未来演进的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








