本文主要是介绍go 语言爬虫库goquery介绍,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 爬虫介绍
- goquery介绍
- 利用NewDocumentFromReader方法获取主页信息
- Document介绍
- 通过查询获取文章信息
- css选择器介绍
- goquery中的选择器
- 获取主页中的文章链接
- 爬取
- 总结
爬虫介绍
爬虫,又称网页抓取、网络蜘蛛或网络爬虫,是一种自动浏览互联网并从网站上获取信息的程序或脚本。它通过模拟人类浏览器的行为,按照预设的规则和策略遍历互联网上的网页,并将所获取的数据存储下来进行进一步处理和分析。
爬虫在我们生活中可以产生的东西有很多
-
搜索引擎索引构建:搜索引擎会使用爬虫抓取互联网上的网页,分析其内容并建立索引,以便用户在搜索时能够快速找到相关结果。
-
数据分析与研究:数据分析师和研究人员可以编写爬虫来收集特定领域的信息,如电子商务网站的商品价格、评论等,用于市场趋势分析、竞品监测、消费者行为研究等。
-
新闻聚合:新闻聚合类应用通过爬虫从多个新闻网站获取最新的文章标题、摘要以及链接,为用户提供一站式的新闻阅读体验。
-
社交媒体监控:针对社交媒体平台的爬虫可以抓取公开的帖子、评论等内容,用于舆情分析、热点话题追踪、品牌口碑监测等。
-
企业信息抓取:商业情报机构或公司可能需要抓取工商注册、专利申请、招聘信息等公开的企业数据,进行行业分析、潜在客户挖掘等工作。
-
教育资源整理:教育领域中,爬虫可以用来搜集网络课程资源、学术论文、图书资料等,并进行整理归类。
-
网站性能检测:某些类型的爬虫(例如蜘蛛侠)用于模拟大量用户访问以测试网站性能,检查是否存在服务器响应延迟、页面加载慢等问题。
-
法律合规审计:在网络合规性审查中,爬虫可以用于查找非法或侵权内容,协助监管部门进行网络环境净化。
在生活中爬虫其实可以做很多事情,鉴于本文是一个入门教程,就接下来会以一个爬取csdn网页增加流量的列子逐步介绍和完善我们的爬虫程序。
goquery介绍
GoQuery是专为Go(Golang)语言设计的一个强大的HTML解析和查询库。它模仿了jQuery的API风格,使得在Go中处理HTML文档变得简单且直观。
GoQuery主要用于网页抓取(Web Scraping),能够通过CSS选择器来定位、遍历和操作HTML元素。你可以使用它来提取网页中的特定数据、修改DOM结构或进行其他与HTML文档相关的操作。
利用NewDocumentFromReader方法获取主页信息
NewDocumentFromReader 是GoQuery库中的一个函数,用于从io.Reader接口读取的HTML数据创建一个新的文档对象。对于文档对象是什么我们会在下文经性讲解。
func NewDocumentFromReader(reader io.Reader) (*Document, error)
以下我们查找主页信息的代码,studycodeday是博主本人的主页,想要访问自己的主页,只需要把studycodeday改成自己的用户id就行。
func main() {// 通过http发送get请求req, err := http.Get("https://blog.csdn.net/studycodeday")if err != nil {slog.Error("访问主页失败")}defer req.Body.Close()// 解析请求体doc, err := goquery.NewDocumentFromReader(req.Body)// 让请求体按照html格式输出,也有Text()按照文本输出的方法fmt.Println(doc.Html())
}
效果
Document介绍
在GoQuery库中,Document是代表整个HTML文档的对象。它是对原始HTML内容解析后形成的DOM树的抽象表示,提供了与jQuery类似的接口来操作和查询HTML元素。
*goquery.Document主要有以下特点和功能:
- 初始化:
从本地文件或io.Reader读取:使用goquery.NewDocumentFromReader(reader io.Reader)从任何实现了io.Reader接口的对象(如文件、HTTP响应体等)创建一个Document对象。 - 查找元素:
使用CSS选择器进行查找:doc.Find(selector string)返回一个新的Selection对象,该对象包含了所有匹配给定CSS选择器的元素。 - 遍历和操作元素:
Each(func(int, *goquery.Selection))方法用于迭代选区中的每个元素,并对其执行回调函数。
提供了类似jQuery的方法,如.Children()获取子元素、.Parents()获取父元素等。 - 属性操作:
Attr(name string) (string, bool):获取首个匹配元素的指定属性值及其是否存在。
SetAttr(name, value string):为所有匹配元素设置指定属性的值。 - 文本和HTML内容操作:
Text() string:获取所有匹配元素的合并文本内容。
Html() string:获取首个匹配元素的HTML内容。
其他功能:
goquery.Document对象是GoQuery库的核心组成部分,它封装了对HTML文档进行各种复杂查询和操作的能力。
通过查询获取文章信息
css选择器介绍
获取文章需要我们通过查询的方式,goquery提供了能够通过CSS选择器来定位元素。
其类型包括但不限于以下几种:
- 基本选择器:
- *:匹配所有元素。
- element:匹配所有指定类型的元素,如 div、span 等。
- .class:匹配具有指定类名的元素,如 .myClass。
- #id:匹配ID为指定值的元素,如 #header。
- 属性选择器:
- [attribute]:匹配具有指定属性的元素,不论该属性值为何。
- [attribute=value]:匹配属性值等于指定值的元素,如 [href=“http://example.com”]。
- [attribute^=value]、[attribute$=value]、[attribute*=value]:分别匹配属性值以指定值开头、结尾或包含指定值的元素。
- 层次选择器:
- parent > child:匹配作为指定父元素直接子元素的所有child元素。
- ancestor descendant:匹配在ancestor元素内的所有descendant元素(无论嵌套多深)。
- prev + next:匹配紧跟在prev元素之后的next元素。
- prev ~ siblings:匹配prev元素之后的所有同辈siblings元素。
- 伪类选择器:
- :first-child、:last-child、:nth-child(n):匹配某个元素在其父元素内是第一个、最后一个或第n个子元素的情况。
- :not(selector):排除匹配给定选择器的元素。
goquery中的选择器
Find():
doc.Find(selector string)
根据给定的CSS选择器在当前选区(Selection)中查找匹配的元素。例如,doc.Find(“h1”)会找到所有
标签。
Filter():
selection.Filter(selector string)
在当前选区中过滤出符合指定CSS选择器的元素子集。
Eq():
selection.Eq(index int)
返回当前选区中索引为index的单个元素。索引从0开始。
First() 和 Last():
selection.First()
selection.Last()
分别返回当前选区中的第一个或最后一个元素。
Next() 和 Prev():
selection.NextAll()
selection.PrevAll()
获取当前元素之后的所有同辈元素或之前的所有同辈元素。
Children():
selection.Children()
获取当前选区中所有直接子元素。
Parents() 和 Closest():
selection.Parents()
selection.Closest(selector string)
Parents()返回当前选区中所有父级元素,而Closest()返回最近的且匹配给定CSS选择器的祖先元素。
Attr():
attr, exists := selection.Attr(attributeName string)
获取当前选区中首个元素的属性值,exists用于判断该属性是否存在。
Each():
selection.Each(func(i int, s *goquery.Selection) {})
遍历当前选区中的每一个元素,并对每个元素执行一个函数。
获取主页中的文章链接
首先我们要打开f12调试工具,找到我们需要爬取数据的所在的具体位置。
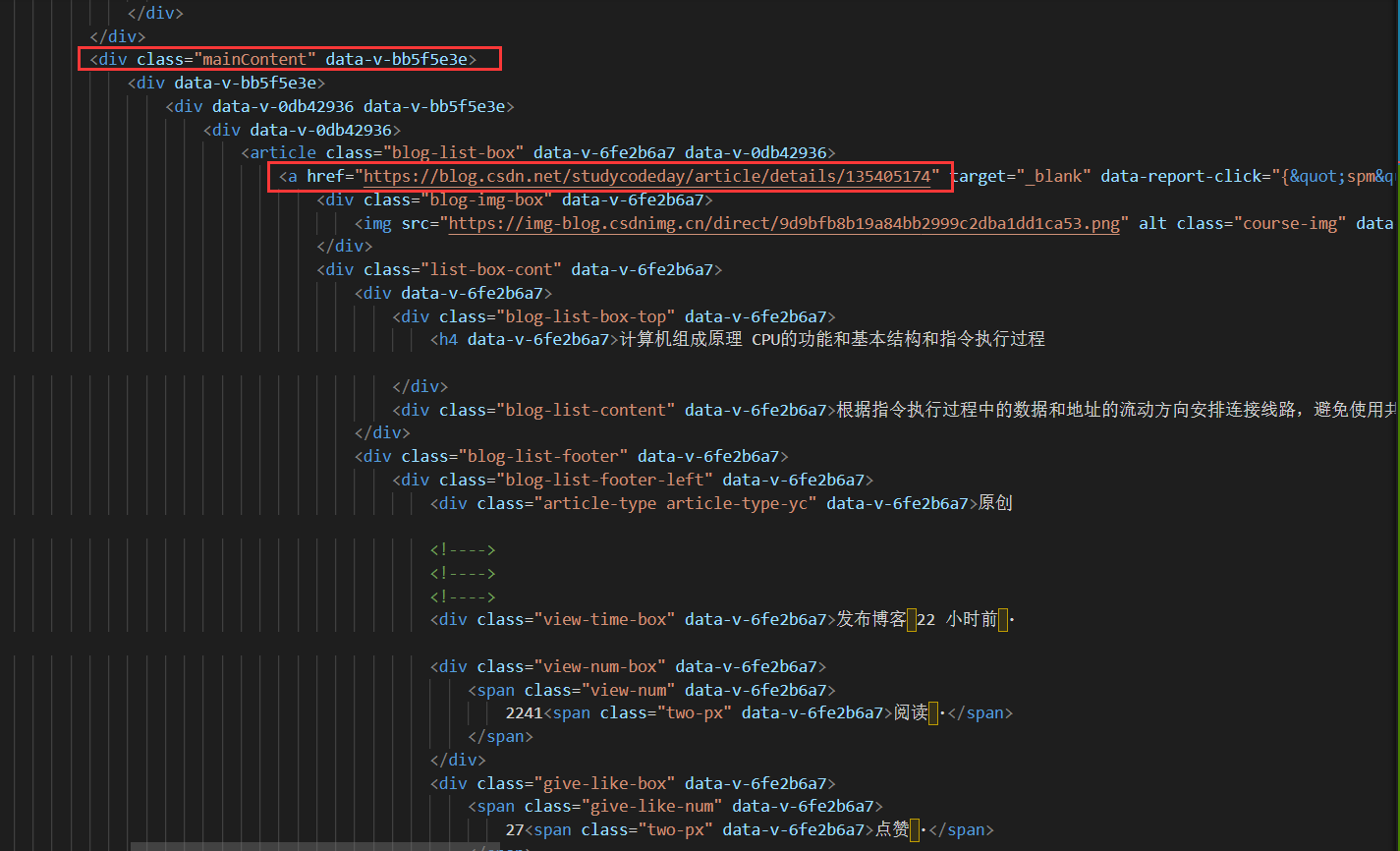
由上图可知我们的文章连接在拥有class=“mainContent” 的div盒子里,这个盒子包括了二十个含有 class=“blog-list-box” 的article标签,我们所需要的内容就在article标签下面的a标签的herf中。
这里我们采用层次原则器 ancestor descendant:匹配在ancestor元素内的所有descendant元素(无论嵌套多深)。把文章盒子提取来之后我们还需要通过Each方法遍历输出a标签中的href属性的值
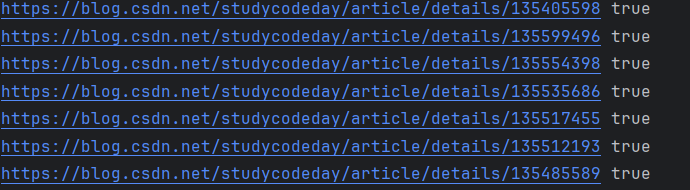
// 通过http发送get请求req, err := http.Get("https://blog.csdn.net/studycodeday")if err != nil {slog.Error("访问主页失败")}defer req.Body.Close()// 解析请求体doc, err := goquery.NewDocumentFromReader(req.Body)//fmt.Println(doc.Find(".mainContent .blog-list-box").Length())doc.Find(".mainContent .blog-list-box").Each(func(i int, s *goquery.Selection) {fmt.Println(s.Find("a").Attr("href"))})
效果
爬取
以上我们就完成了主页文章信息的爬取,我们只需要吧内容存在数组中,经行爬取访问即可。
代码
func main() {var urls = make([]string, 0, 20)// 通过http发送get请求req, err := http.Get("https://blog.csdn.net/studycodeday")if err != nil {slog.Error("访问主页失败")}defer req.Body.Close()// 解析请求体doc, err := goquery.NewDocumentFromReader(req.Body)//fmt.Println(doc.Find(".mainContent .blog-list-box").Length())doc.Find(".mainContent .blog-list-box").Each(func(i int, s *goquery.Selection) {url, _ := s.Find("a").Attr("href")//添加到数组中urls = append(urls, url)})for _, url := range urls {_, err = http.Get(url)if err != nil {slog.Error("访问网页失败:" + url)}fmt.Println("访问成功:" + url)time.Sleep(time.Duration(rand.Int31n(60)) * time.Second)}
}效果

总结
虽然我们实现了爬取csdn网页,但是仍然存在许多问题:
- 没有代理频繁访问容易封ip,造成无法访问csdn
- 爬取只能爬取前二十篇文章,该解决方法是参考该api,只需要把username改成自己的id即可https://blog.csdn.net/community/home-api/v1/get-business-list?page=2&size=20&businessType=lately&noMore=false&username=studycodeday"
- 没有进行请求伪装,随时可能被封
这篇关于go 语言爬虫库goquery介绍的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






