本文主要是介绍一次解决ForkJoinPool日志追踪的辛酸经历,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本文主要分享了一次解决ForkJoinPool日志追踪的辛酸经历。历时3个月终于找到通用的解决方案,以此文分享给有需要的你。
一、需求背景
1.某日,某同事根据日志ID排查生产环境问题过程中,发现日志不全
2.经排查发现中间有很多线程为ForkJoinPool.commonPool-worker的日志ID是丢失的
3.经代码review,发现这些丢失日志ID的log.info都是在parallelStream代码块中的
4.经了解,因为使用了parallelStream并发处理集合数据,这样能够提升接口性能,并且这个功能是jdk提供的,使用非常方便
以下为简化版的代码demo
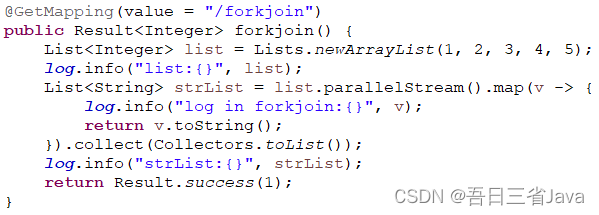
经测试,发现在parallelStream的log.info无法正确的打印日志ID,那么在生产环境中,日志ID的丢失意味着日志排查问题变得困难,如下图所示

二、原因分析
为了提升接口性能,使用并发编程加快查询速度的确是比较不错的方案。
日志ID是使用org.slf4j.MDC进行传递的,经阅读源码,发现底层是使用ThreadLocal来进行数据存储的,多线程情况下,子线程无法访问到主线程的日志ID
并发编程项目中通常有2种用法:
1.使用线程池,如ThreadPoolExecutor、ThreadPoolTaskExecutor,可以自己new一个实例,这样的话可以通过自定义子类来做日志ID传递(这种方式已解决,具体可阅文章,这里就不详说了:https://www.toutiao.com/article/7126056949267268108)
2.使用ForkJoinPool,不是由自己new实例,而是jdk封装好的。例如CompletableFuture、list.parallelStream()、list.stream().parallel()等,底层都是使用了ForkJoinPool作为线程池实现(为了找到通用的解决方案,历时3个月)
>>> 那如何解决ForkJoinPool这个日志ID丢失的问题?
三、临时方案
当时无法在短时间内快速找到通用解决方案,所以想了1种临时方案:通过变量的方式传递到list.parallelStream()内部
如下图,这种方案需要改动代码
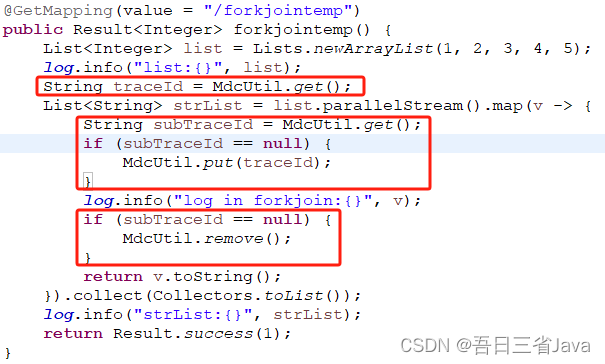
为什么要加subTraceId == null的判断?
答:主线程也会作为ForkJoinPool执行的一部分,主线程的日志ID不能清,否则后续的日志ID会丢失
四、寻找通用方案
1.方向错误,努力白费(辛酸经历,中途还想过放弃寻找通用方案)
方向1:参考ThreadPoolExecutor、ThreadPoolTaskExecutor,想办法自己new一个ForkJoinPool的实例,然后添加到spring容器使用
结果:最终发现ForkJoinPool是内部实现了1个静态的实例common从而告败
方向2:使用javaagent的方式修改ForkJoinPool或者其任务 ForkJoinTask等相关类的字节码,此想法来自一篇好文:一次「找回」TraceId的问题分析与过程思考(一次「找回」TraceId的问题分析与过程思考)
结果:最终发现字节码框架Javassist底层对包名以java.开头的所有类进行了保护,而ForkJoinPool的包名java.util.concurrent,所以字节码修改方案也不通了
2.求助网友,集思广益
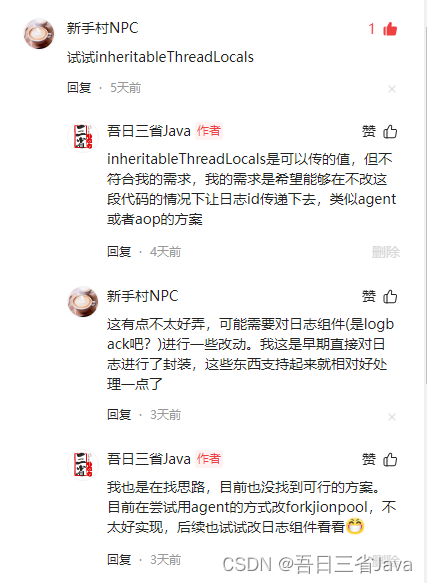
真的挺感谢这位‘新手村NPC’网友,给我提供了1个思路:竟然修改ForkJoinPool的思路走不通,那就尝试修改日志组件
3.修改日志组件
1.前面说过MDC底层是使用ThreadLocal来进行数据存储的,这就让我想到了阿里的TransmittableThreadLocal,能够在父子线程之间传递数据
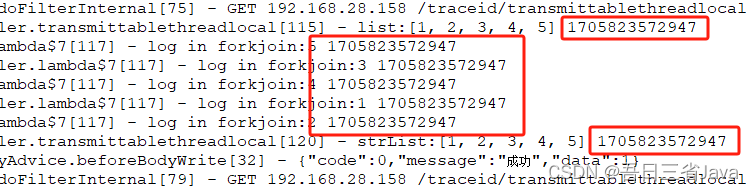
先测试一下TransmittableThreadLocal能否在list.parallelStream()内部正确传递数据
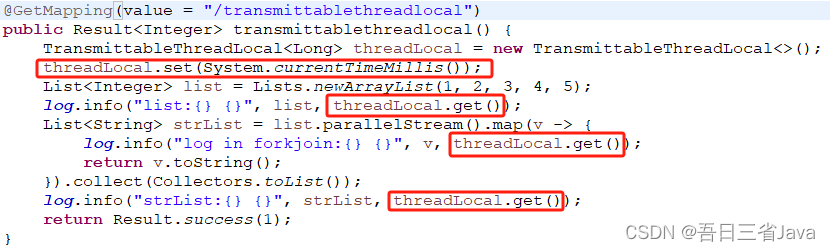
注:需要在启动命令上加上:-javaagent:path/to/transmittable-thread-local-2.x.x.jar(替换为你maven路径中jar路径即可),否则会读取不到,因为TransmittableThreadLocal是基于字节码javaagent来实现的
结果:输出的值始终保持一致
2.修改MDC
MDC的ThreadLocal在哪里?通过断点的方式找到了MDCAdapter的实例LogbackMDCAdapter(其成员变量copyOnThreadLocal)
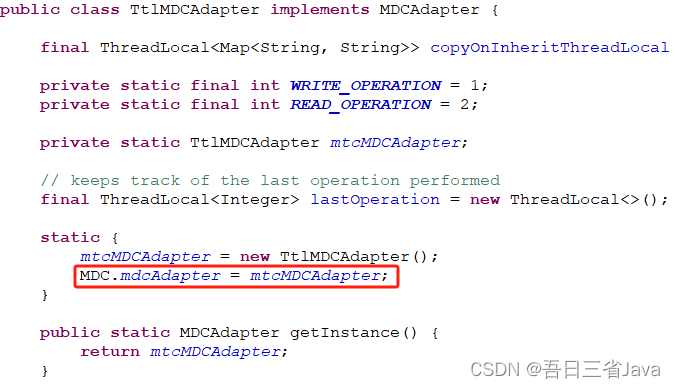
有没有办法在初始化时替换掉这个MDCAdapter的实例?MDCAdapter下面的MDCAdapter不是public的,只有getMDCAdapter方法而没有setMDCAdapter方法。
于是网上查询相关资料,方案是在项目中写个org.slf4j的包,然后通过以下方式赋值,因为同包下可访问(不得不说这操作挺骚的,佩服,这些知识点都忘了)
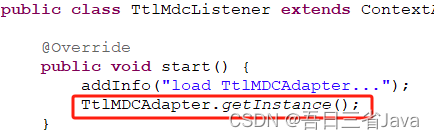
然后通过TtlMdcListener对TtlMDCAdapter进行实例化
logback.xml配置文件中增加TtlMdcListener的实例化
<contextListener class="com.ofpay.logback.TtlMdcListener"/>这2个简单的类,既可以自己实现,也可以使用开源的maven,实现原理是一样的
<dependency><groupId>com.ofpay</groupId><artifactId>logback-mdc-ttl</artifactId><version>1.0.2</version>
</dependency>于是,在完全不改业务代码的情况下,日志ID正确地传递下来了
测试结果:

怎么样?如果你觉得有用的话,还不快快收藏起来!!!
附:涉及的代码目录
github: https://github.com/897665787/springcloud-template
gitee:springcloud-template: 一个基于springcloud netflix微服务框架,记录了关于微服务开发的一些最佳应用,欢迎大家学习指导。
springcloud-template
└── template-common
└──src/main/resources
└── logback-conf-base.xml-- 日志配置
└──pom.xml-- 引用logback-mdc-ttl
└── template-web
└──controller
└── TraceIdController-- 日志ID测试demo
这篇关于一次解决ForkJoinPool日志追踪的辛酸经历的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








