本文主要是介绍初识机器学习框架:TensorFlow1.X版本 的基础使用,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
学习网站:人工智能教程
TensorFlow的版本查看与安装
查看自己的TensorFlow版本:pip show tensorflow
这是我的:

关于TensorFlow 的安装配置确实有些麻烦,并且由于国外网站的原因,下载速度也许会非常的慢,所以这里推荐一下清华的镜像,TensorFlow的1.X版本和2.X版本有很大不同,这篇文章是介绍如何使用1.X版本的,但是请务必下载更新的版本,因为新版本也是包含旧版本的。
pip --default-timeout=100 install tensorflow==2.4.0 -i https://pypi.tuna.tsinghua.edu.cn/simple当然也可以看一下其他博主的博客,讲解的非常清楚,由于我已经安装过了,就不再重复演示
TensorFlow的基础使用
在Python中使用TensorFlow1.X ,首先需要导入TensorFlow的包:
//由于我下载的是2.X的版本,所以要使用1.X版本的话,需要写下面的语句
import tensorflow.compat.v1 as tf
tf.compat.v1.disable_eager_execution()
//如果本身就是1.X的版本,可以直接使用下面的语句
import tensorflow as tfas tf 的作用是为了方便使用,这样我们在使用TensorFlow的时候就不用写全称了,直接使用tf即可
为了学习TensorFlow的框架,我们可以先实现一个简单的公式;
constant
constant 的作用就是定义一个Tensorflow的常量对象
y_hat = tf.constant(36, name='y_hat') # 定义一个tensorflow常量
y = tf.constant(39, name='y') 可以看到,y_hat 的值就是36,还定义了该Tensorflow常量对象的名称为y_hat,y则同理
Variable
下面计算一下loss:
loss = tf.Variable((y - y_hat)**2, name='loss')这里的Variable就是代表创建一个TensorFlow的常量对象,而loss就是那个常量对象,该对象的值就是执行了(y - y_hat)**2后的结果,此对象名称为loss
global_variables_initializer
global_variables_initializer用于创建TensorFlow的初始化对象,例如:
init = tf.global_variables_initializer()这里创建了init的初始化对象,后面就可以调用init来初始化变量
Session
Session就非常重要了,他可以创建一个TensorFlow的Session对象,通过此对象,可以具体的执行前面的所有操作,我们加上Session来总结一下前面的代码:
y_hat = tf.constant(36, name='y_hat')
y = tf.constant(39, name='y') loss = tf.Variable((y - y_hat)**2, name='loss') init = tf.global_variables_initializer()
with tf.Session() as session: session.run(init) print(session.run(loss)) 前面四行的操作就不说了,我们将TensorFlow的Session对象命名为session,之后使用session的run方法执行init的计算,这里就体现出了一个思想:画图纸->建造
“画图纸->建造”思想
很久之前我们接触过一个叫做计算图的概念,计算图将整个计算的流程画出来,有助于我们一步一步的进行计算,思路更加清晰,而这里的前面四行代码其实就是构建了一个计算图;

但是也只是构建了一个计算图,并没有执行具体的计算,如果需要执行具体的计算,就需要使用TensorFlow中的Session中的run方法,这张计算图的结果才算是被计算出来了,也就是图纸上的建筑被建造出来了
如果我们直接执行对init的输出操作,那输出的结果只会是init的关于TensorFlow的一些属性和信息,像这样:Tensor("Mul:0", shape=(), dtype=int32)
Session的不同写法
方法一;
sess = tf.Session()
result = sess.run(..., feed_dict = {...})
sess.close() 方法二:
with tf.Session() as sess: result = sess.run(..., feed_dict = {...})本质上都是先创建一个Session对象,然后使用run方法执行计算图,需要注意的是Session需要关闭,即执行close,方法一需要手动关闭,方法二计算完成后就自动关闭。
placeholder占位符
占位符可以为一个变量预先留好一个位置,只有在使用时再对占位符进行数值的填充操作;
x = tf.placeholder(tf.int64, name = 'x')
print(sess.run(2 * x, feed_dict = {x: 3}))
sess.close()这里定义了一个x的占位符,数值大小为int64,名称为x
在我们执行2*x的时候,由于x是一个占位符,没有任何数据,所以此时就需要feed_dict语句给x赋值,feed_dict的语法差不多是固定的:feed_dict = {变量名 : 数值},然后将赋值后的变量带入到2*x中的x去,可以理解为一个从后到前的过程。
matmul
在机器学习中,我们对大量数据的操作一般都是使用的矩阵运算,在TensorFlow中,提供了一个矩阵运算的方法matmul
假如我们现在需要构建一个线性函数Z = WX + b ,其中W是特征向量,X是数据集,b是阈值向量,他们都需要进行矩阵运算,此时我们就可以使用matpul了:
def linear_function(): X = tf.constant(np.random.randn(3, 1), name = "X") W = tf.constant(np.random.randn(4, 3), name = "W")b = tf.constant(np.random.randn(4, 1), name = "b")Z = tf.add(tf.matmul(W, X), b)# tf.matmul函数会执行矩阵运算sess = tf.Session()result = sess.run(Z)sess.close()return result这里的X是一个维度为(3,1)的常量,使用randn来随机产生值,下面同理
注意这里的Z,add顾名思义就不用多说了,相加操作,WX与b进行相加,matpul(X,W)则是执行了矩阵相乘。稍微思考一下,最后输出的result应该是一个(4,1)维度的向量
实现Sigmoid函数
在前面,我们大费周章讲解了Sigmoid的底层计算原理,但是在TensorFlow框架中,短短几行就完成了计算:
def sigmoid(z):x = tf.placeholder(tf.float32, name="x") sigmoid = tf.sigmoid(x) # 调用tensorflow的sigmoid函数,并且将占位符作为参数传递进去with tf.Session() as sess:result = sess.run(sigmoid, feed_dict = {x: z}) return result回忆一下Sigmoid函数,它是需要我们的Z来执行计算的,所以显示定义了一个占位符,以便于后续填充Z的值,至于Sigmoid,只需要短短的一行代码就解决了战斗:tf.sigmoid(x),这里的x是在后面用run执行的时候填充进去的参数Z的值。
实现Cost函数
Cost是损失值,在前面的文章中,Cost我们使用纯数学公式和纯Python代码将其实现了,而使用TensorFlow,却只需要短短一行:
tf.nn.sigmoid_cross_entropy_with_logits(logits = ..., labels = ...)这里的logits指的是神经网络中最后一层输出的Z,label就是真实的标签y,不知道你们细不细心,为什么执行Cost计算只需要最后的Z就可以了呢?难道不是计算Sigmoid之后的A吗?其实这个函数除了帮我们执行计算损失之外,也自动为我们最后一层的Z执行了Sigmoid的计算
当然,如果你最后一层不想用Sigmoid,而是想用多分类函数SoftMax,TensorFlow也提供了方法:
tf.nn.softmax_cross_entropy_with_logits(logits = ..., labels = ...)One-hot 独热编码
假设我们要执行这样的操作:

这在一些多分类模型中经常使用,在TensorFlow中,也有对应的函数帮我们完成了:one_hot
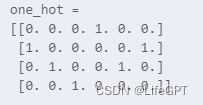
def one_hot_matrix(labels, C_in):C = tf.constant(C_in, name='C')one_hot_matrix = tf.one_hot(indices=labels, depth=C, axis=0)sess = tf.Session()one_hot = sess.run(one_hot_matrix)sess.close()return one_hot我们传入的label参数就是真实的标签,C_in就是一共有几个类别,比如上面那张图,只有0~3四个数字,那就是4类,C_in就是4,其他部分其实前面都讲过了,简单的一行tf.one_hot,就帮我们把所有的工作做完了,假如我们有label为:labels = np.array([1,2,3,0,2,1])
那我们执行:one_hot = one_hot_matrix(labels, C_in=4)
最后的输出就是这样的;
这篇关于初识机器学习框架:TensorFlow1.X版本 的基础使用的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



