本文主要是介绍基于Python(Pandas+Pyecharts)实现全国热门旅游景点数据可视化【500010037】,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
导入模块
import jieba
import pandas as pd
from collections import Counter
from pyecharts.charts import Line,Pie,Scatter,Bar,Map,Grid
from pyecharts.charts import WordCloud
from pyecharts import options as opts
from pyecharts.globals import ThemeType
from pyecharts.globals import SymbolType
from pyecharts.commons.utils import JsCode
数据说明
全国热门旅游景点数据,包含城市、名称、星级、评分、价格、销量、省/市/区、坐标、简介、是否免费、具体地址等字段信息
字段:城市、名称、星级、评分、价格、销量、省/市/区、坐标、简介、是否免费、具体地址
| 字段 | 数据类型 |
|---|---|
| 城市 | string |
| 名称 | string |
| 星级 | string |
| 评分 | float |
| 价格 | float |
| 销量 | int |
| 省/市/区 | string |
| 坐标 | string |
| 简介 | string |
| 是否免费 | bool |
| 具体地址 | string |
数据处理
读取数据
df = pd.read_excel(r'./data/旅游景点.xlsx')
df.head()

查看索引、数据类型和内存信息
df.info()

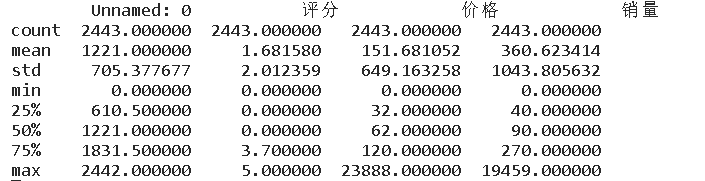
查看数值型列汇总统计
df.describe()
查看销量为0的行
df.loc[df['销量']==0,:].head()

一共有123行。
去除销量为0的行数据
df = df[df['销量']!=0]
去除后还剩下2320行数据。
统计各列空值
df.isnull().sum()

星级存在1407个空值,简介37个空值,具体地址2个空值,其他列不存在空值,数据还算比较完整。
将缺失值用‘未知’填充
df.fillna('未知', inplace=True)

按销量排序
df.sort_values('销量', ascending=False).head()

数据可视化
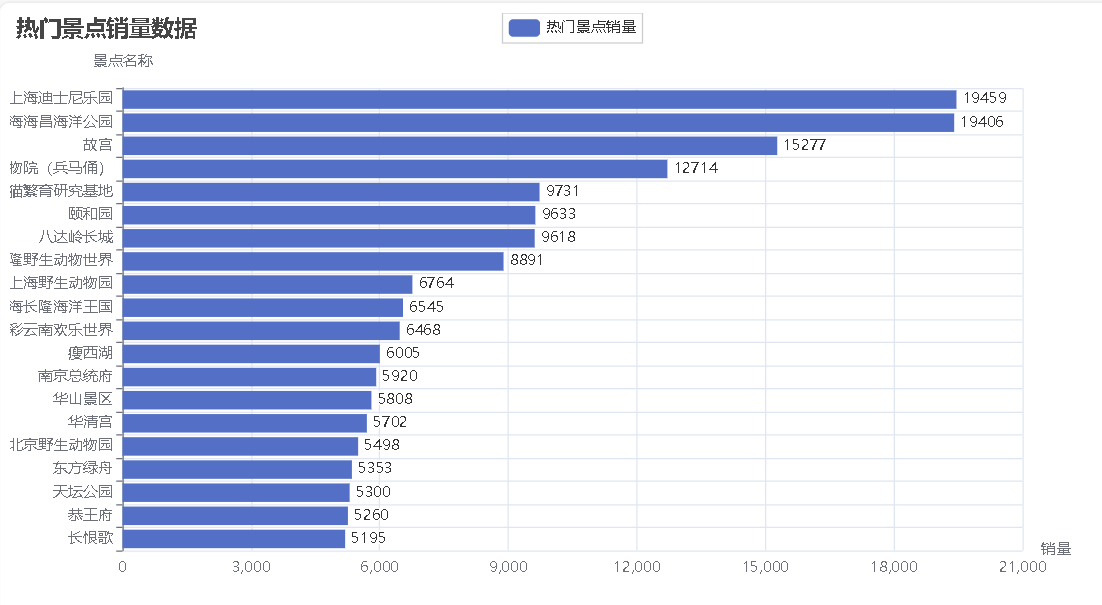
销量前20热门景点数据
假期出行数据全国地图分布
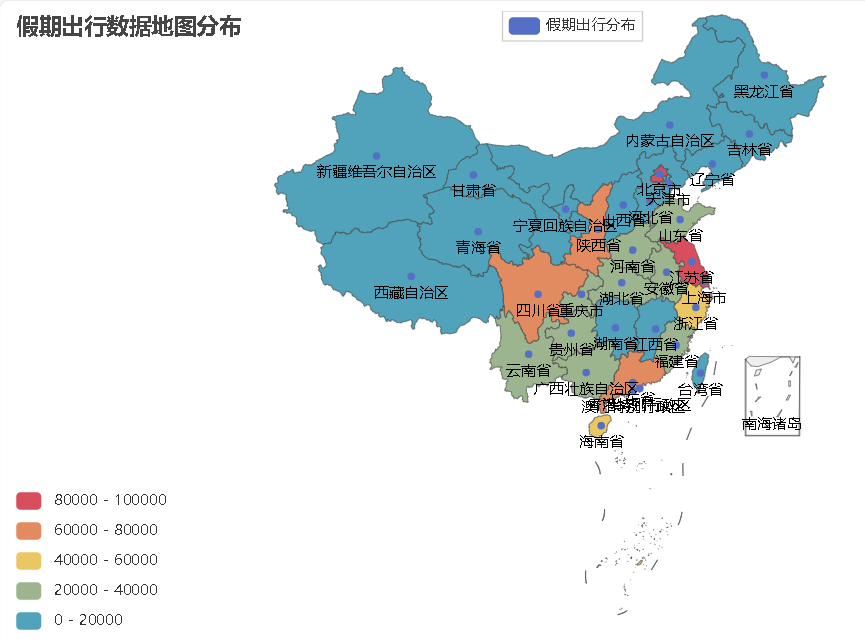
华东、华南、华中等地区属于国民出游热点地区,尤其是北京、上海、江苏、广东、四川、陕西等地区出行比较密集。
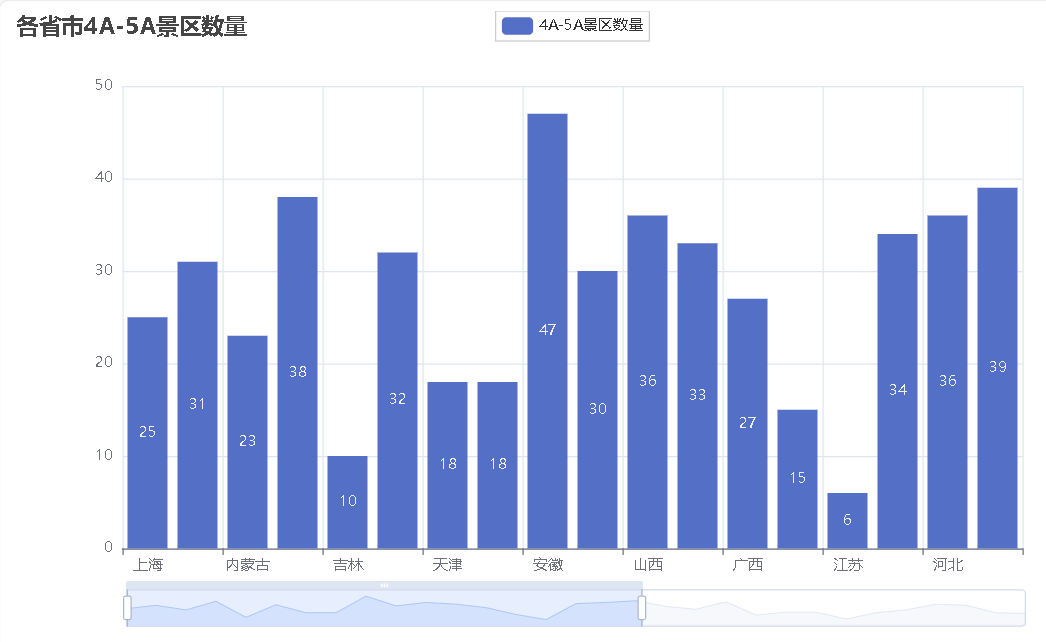
各省市4A-5A景区数量柱状图
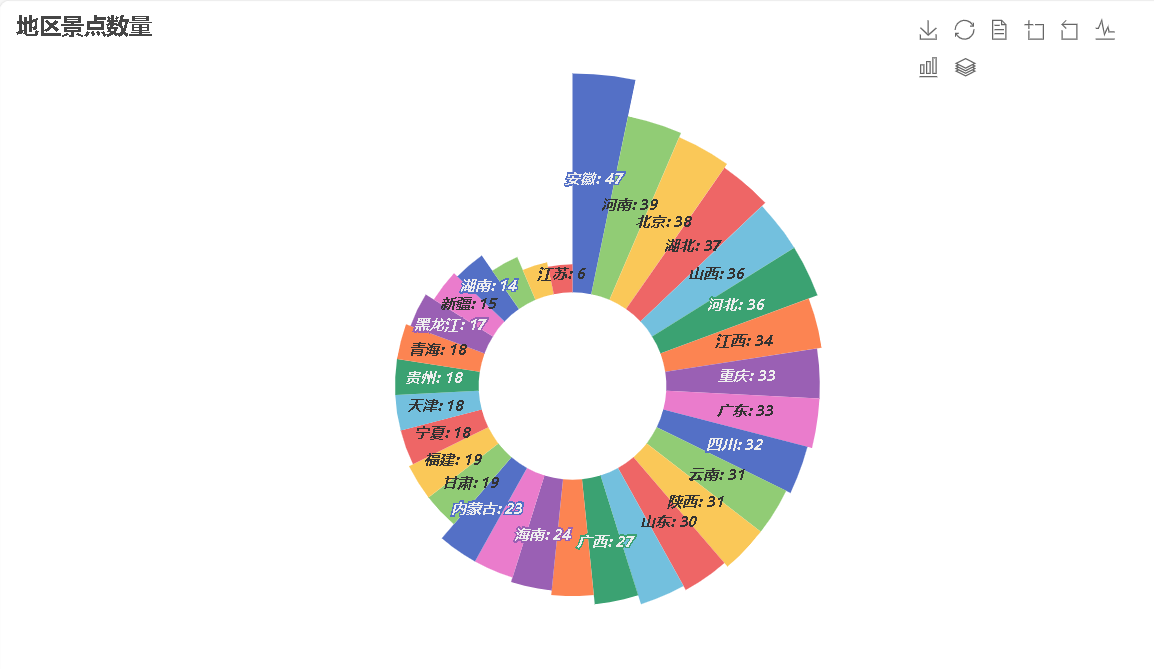
各省市4A-5A景区数量玫瑰图
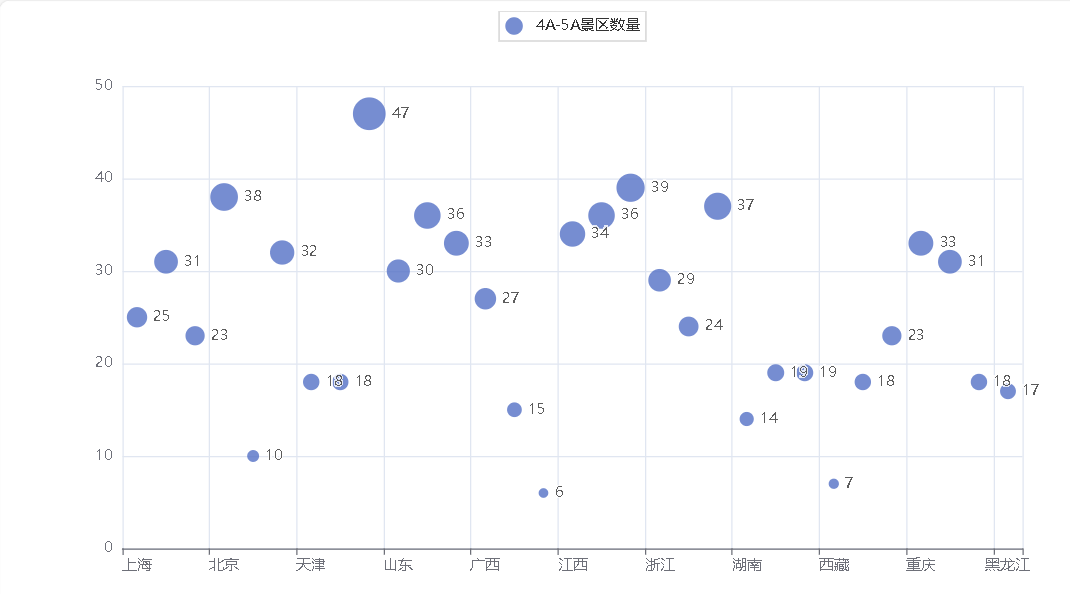
各省市4A-5A景区数量阴影散点图
各省市4A-5A景区地图分布

江苏、安徽、河南、北京、湖北等地区4A、5A级景区数量比较多。
门票价格区间占比玫瑰图
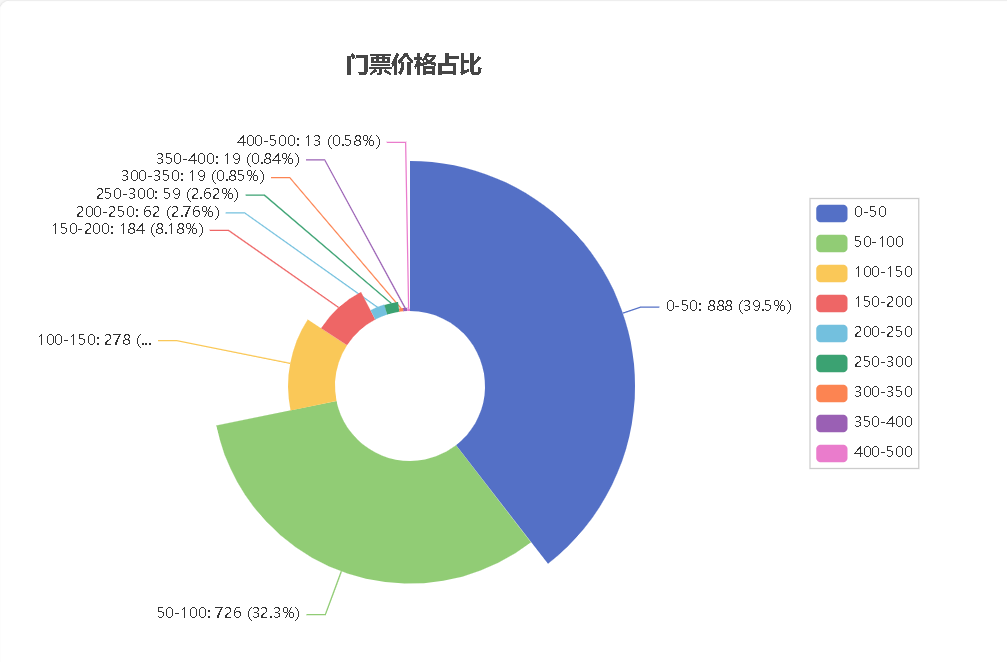
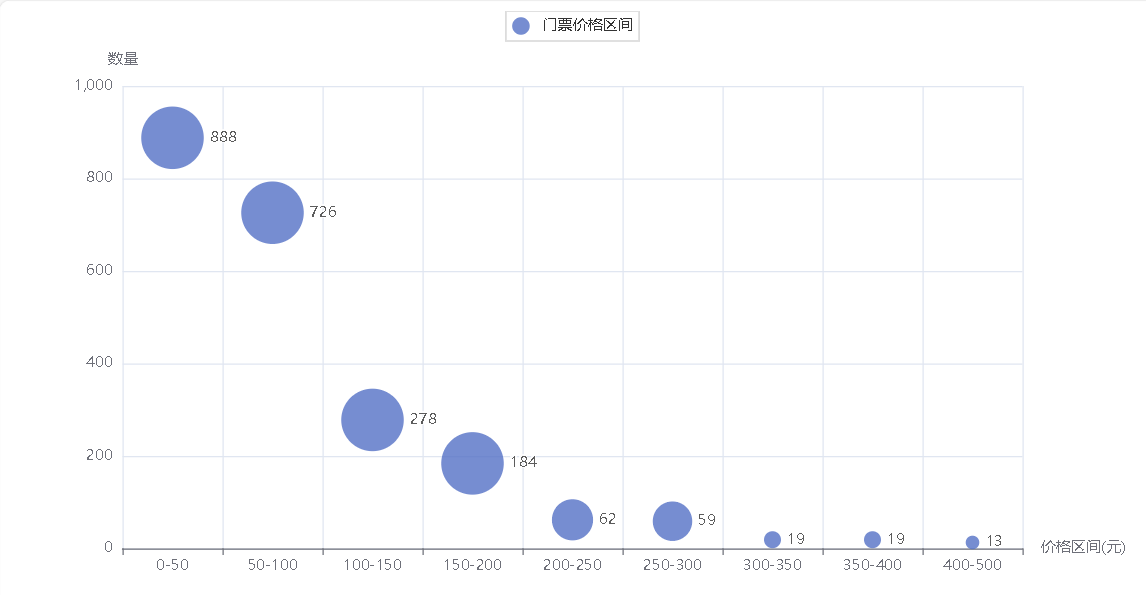
门票价格区间数量散点图
景点简介词云

这篇关于基于Python(Pandas+Pyecharts)实现全国热门旅游景点数据可视化【500010037】的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





