本文主要是介绍邮政快递查询,邮政快递单号查询,将提前签收件筛选出来,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
批量查询邮政快递的物流信息,并将提前签收件分析筛选出来。
所需工具:
一个【快递批量查询高手】软件
邮政快递单号若干
操作步骤:
步骤1:运行【快递批量查询高手】软件,第一次使用的伙伴记得先注册,然后登录
步骤2:点击主界面左上角的“添加单号”,在打开的窗口里把邮政快递单号复制粘贴进去,然后选择单号相对应的快递公司——邮政快递,再点击“保存”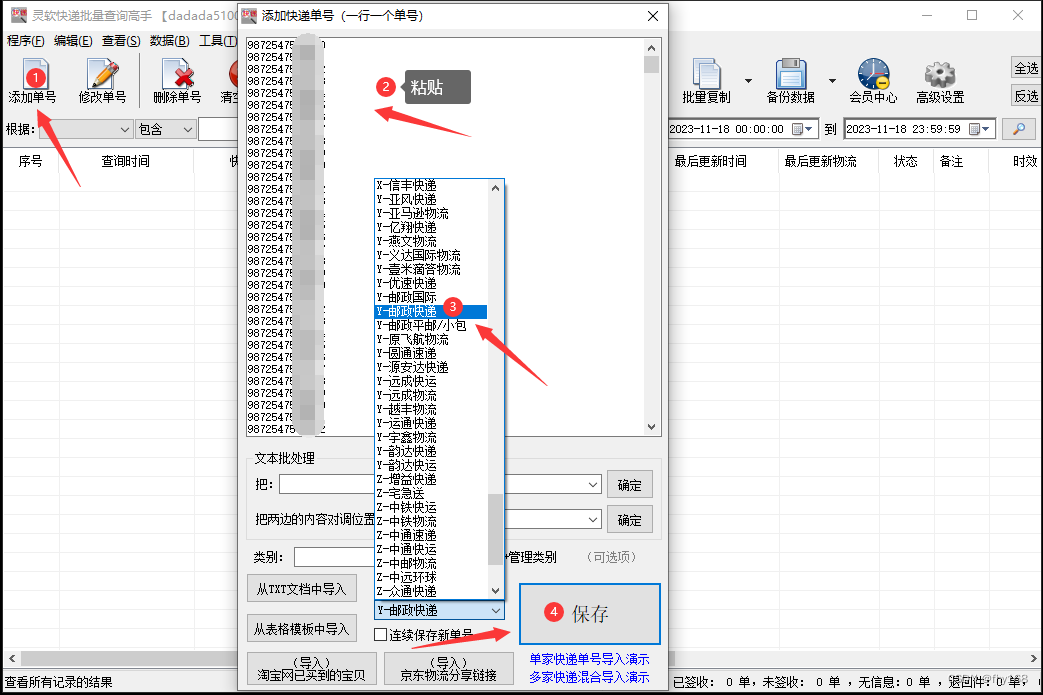
步骤3:保存后,进度条一直在滚动,是软件在批量查询各个快递单号的物流信息
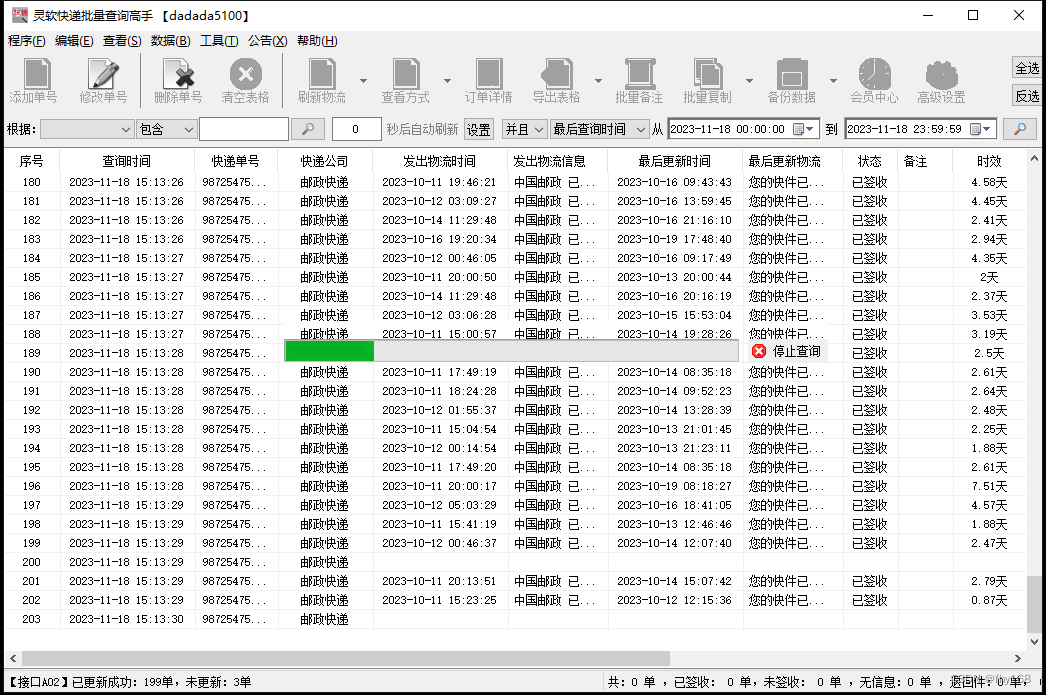
步骤4:查询完成后,软件会自动统计所查询快递的信息结果,以本次为例,共查询邮政快递单号998单,其中已签收972单、未签收2单、无信息17单、退回件7单
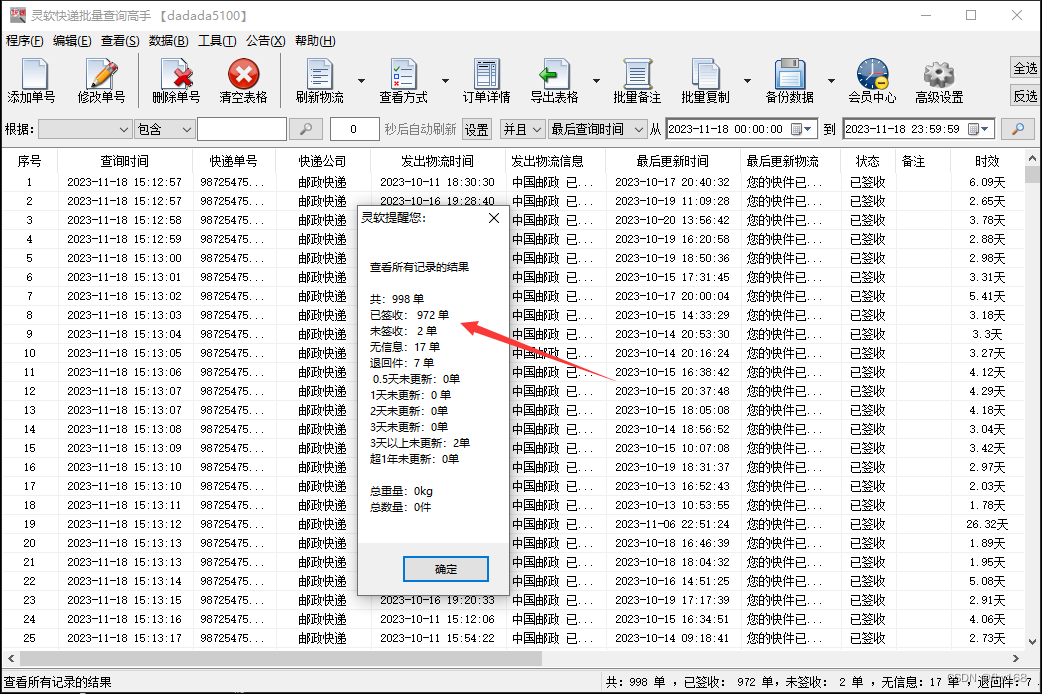
步骤5:点击主界面上方的“工具”,接着点击下级目录的“提前签收分析”
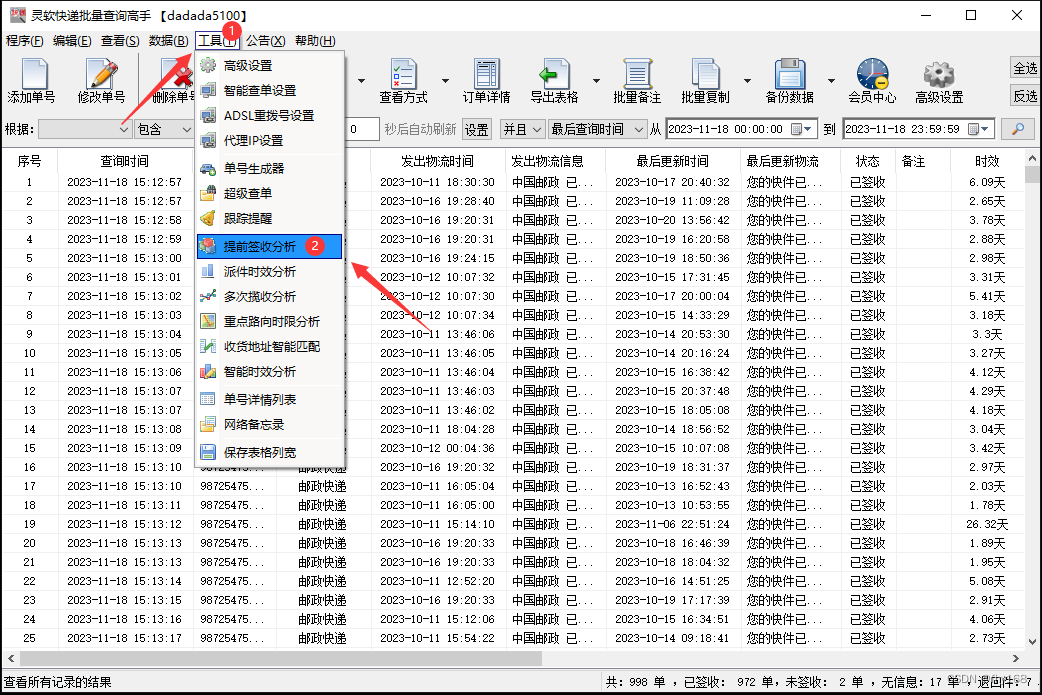
步骤6:软件很快就将提前签收件分析筛选出来了,如图所示
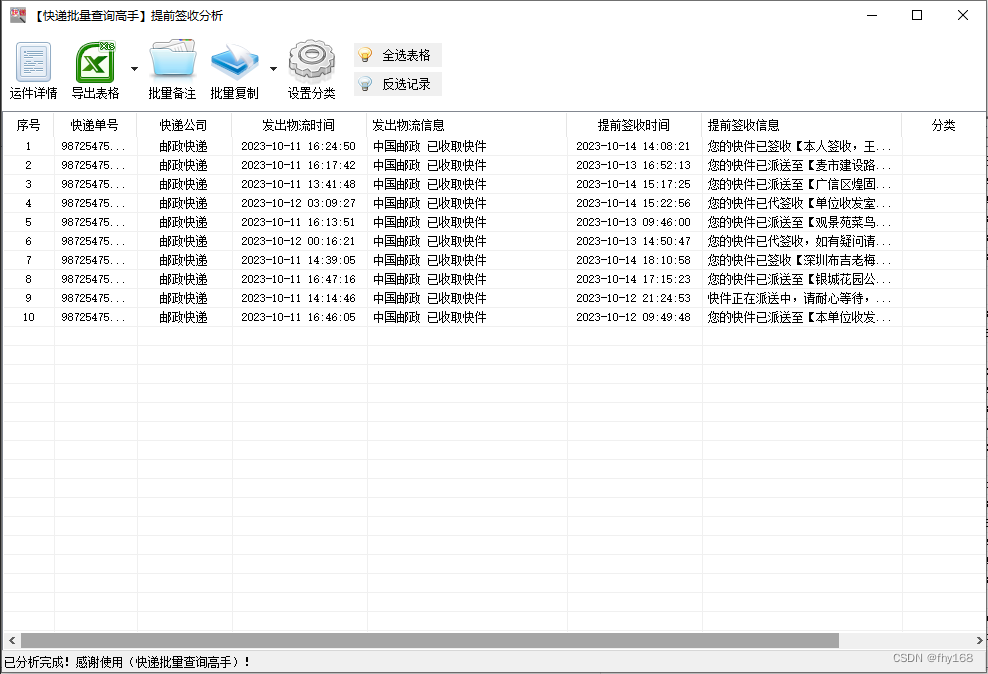
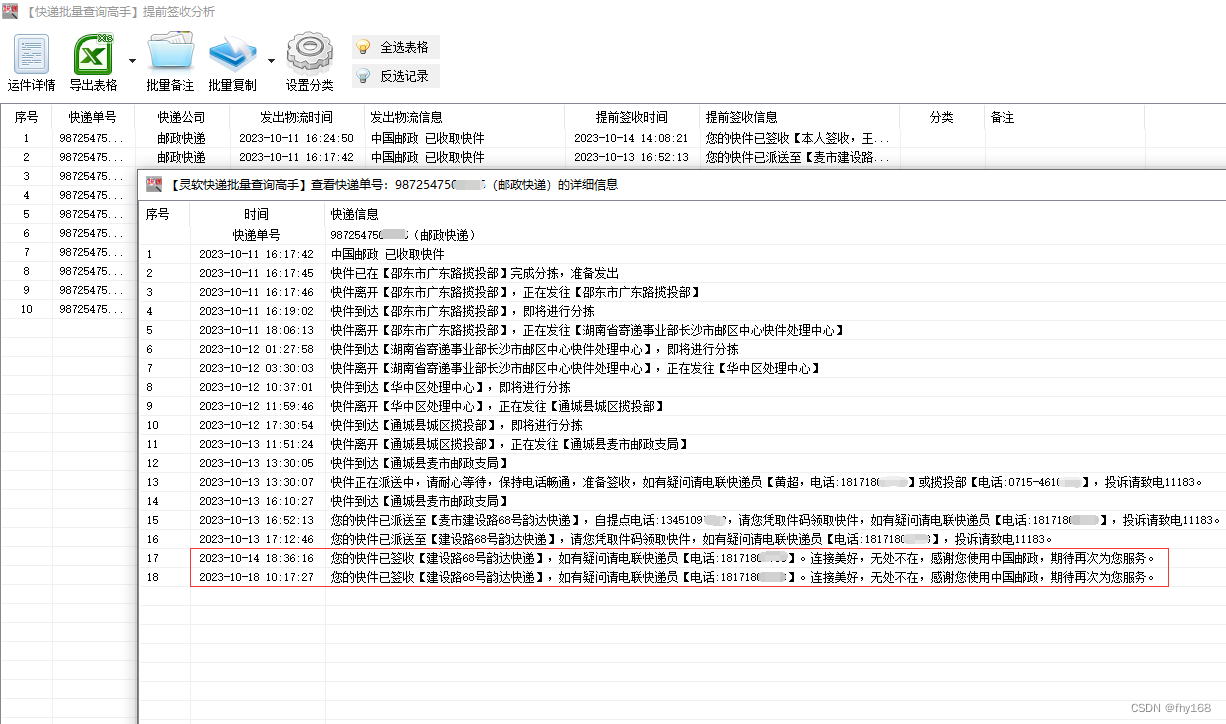
步骤7:双击任意一行,查看该邮政快递单号的详细物流信息,可以看到该单确实属于提前签收件,软件分析筛选成功
这篇关于邮政快递查询,邮政快递单号查询,将提前签收件筛选出来的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







