本文主要是介绍一文理解受限玻尔兹曼机(RBM),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一文理解受限玻尔兹曼机(RBM)
- 限制性玻尔兹曼机(RBM)原理
- RBM简单模型
- RBM能量函数和概率分布
- 求极大似然
- 对比散度算法
- RBM用途
- 分布式RBM可能遇到的问题
限制性玻尔兹曼机(RBM)原理
限制性玻尔兹曼机在玻尔兹曼机基础上进一步加一些约束,取消了v,h变量内部的联系,即不存在可见单元与可见单元的链接,也不存在隐含单元与隐含单元的链接,如下图所示:

RBM简单模型
简单 RBM 模型的参数描述如下:可见层与隐层的之间的权值是w_(n×m),注意到上图中h有n个节点,v 有m节点,单个节点用vj和hi描述。该模型∀ⅈ,j,v_j ϵ{0,1},h_i ϵ{0,1},注意{0,1}是个集合,只能取0或者1。还有2个参数是c和b,可以参考神经网络里面的bias,它们都是列向量,每个分量都对应着每个节点的单独偏置量。
RBM能量函数和概率分布
根据前面BM的能量函数以及RBM特性,很容易推出RBM的能量函数为
利用该能量函数,可以给出状态(v,h)的联合概率分布为
其中
对于实际问题,我们最关心的是关于观测数据v的概率分布Pθ(v),它对应Pθ(v, h)的边缘分布,具体为
类似的有
由前面KL距离可知,以上真实的边缘概率分布可转为求某种近似分布的极大似然来估计。
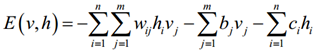
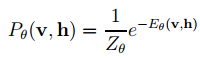
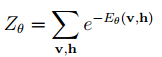
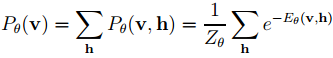
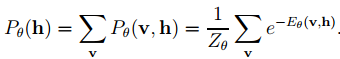
求极大似然
在RBM模型中,其似然函数可表示为
其中θ是要求解的参数,包括w、b、c。
根据前面的能量模型,有:
而要求极大似然,需对似然函数求导,得到如下
带入P(v,h)和P(h|v)的表达式,则有
该式的第一项和第二项是不同的,第一项是求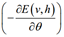
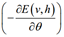
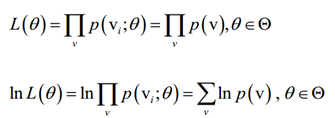



-
对w求导
这里有个小技巧,
最后得到
-
对b求导
-
对c求导
我们发现对3个参数求导后,其第二项均需对整个v进行遍历,这明显是不可行的。于是我们就想到了Gibbs采样的方法来估算第二项。假设训练集为{X1,X2,…,Xl},能得到一组对应符合RBM网络表示的Gibbs分布的样本集{Y1,Y2,…Yl},那么梯度就变为以下的近似公式:

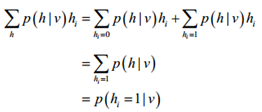
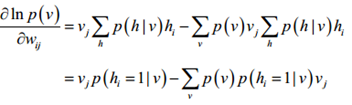


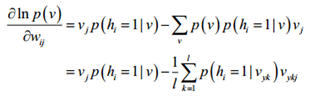
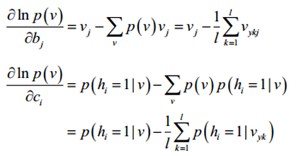
其中p(hi=1|v)可变为以下等式,若记
表示在h中挖掉分量hk后得到的向量,并引入,
以及
这样就有:
那么:
同理可得,
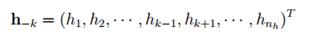
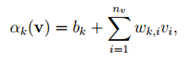
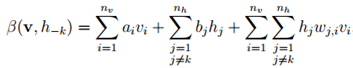
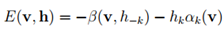

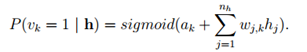
至此,我们已经给出单个训练样本情况下的各表达式,对于多个训练集而言,还需带入L似然函数求解,有:
可得到如下公式,
然而,我们发现每次进行Gibbs采样都要进行足够多的次数的状态转移才能保证采集到的样本符合目标分布,并且样本集也需要很大才能比较精确的进行。由于上述式子中第二项的复杂度为O(2^(n_v+n_h )),在海量样本集情况下会极大加重RBM算法复杂性,降低其效率,因此需要找到更高效的采样算法。
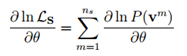

对比散度算法
基于RBM模型的对称结构,以及其中节点的条件独立行,我们可以使用Gibbs抽样方法得到服从RBM定义的分布的随机样本。在RBM中进行k步Gibbs抽样的具体算法为:用一个训练样本(或者可视节点的一个随机初始状态)初始化可视节点的状态v0,交替进行下面的抽样:
在抽样步数n足够大的情况下,就可以得到RBM所定义的分布的样本(即符合参数确定的Gibbs分布的样本)了,得到这些样本我们就可以拿去计算梯度的第二项了。
可以看到,上面进行了k步的抽样,这个k一般还要比较大,所以是比较费时间的,尤其是在训练样本的特征数比较多(可视节点数大)的时候,所以hinton教授就给出一个简化的版本,叫做CD-k,也就是对比散度。
对比散度是英文ContrastiveDivergence(CD)的中文翻译。与Gibbs抽样不同,hinton教授指出当使用训练样本初始化v0的时候,仅需要较少的抽样步数(一般就一步)就可以得到足够好的近似了。
在CD算法一开始,可见单元的状态就被设置为一个训练样本,并用上面的几个条件概率来对隐藏节点的每个单元都从{0,1}中抽取到相应的值,然后再利用 来对可视节点的每个单元都从{0,1}中抽取相应的值,这样就得到了v1了,一般v1就够了,就可以拿来估算梯度了。
下面给出RBM的基于CD-k的快速学习的主要步骤。
图中的从条件分布抽取{0,1}是按如下方式进行:用程序产生一个 0~1的随机数,如果这个随机数小于P(hi=1|v),那么这个隐层节点就取1,反之则取0。假设P(hi=1|v) = 0.6,这时由上面的规则可知,只要随机数小于0.6,这个隐层节点就取1,而恰巧这个随机数小于 0.6 的概率是 0.6(因为0~1的随机数是均匀分布),那么这个事件发生了,就可以认为这个隐层节点取值是1的事件也发生了,所以将隐层取值为1。
上述基于CD的学习算法是针对RBM的可见单元和隐层单元均为二值变量的情形,我们还可以推广到可见单元和隐单元为高斯变量的情形。
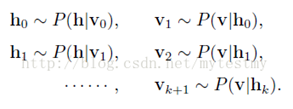

RBM用途
RBM的用途主要是两种,一是对数据进行编码,然后交给监督学习方法去进行分类或回归,二是得到了权重矩阵和偏移量,供BP神经网络初始化训练。
第一种可以说是把它当做一个降维的方法来使用。当使用RBM解决分类任务时,最常见的做法是将RBM视为一个特征提取器,使用观测数据(忽略类别标签)训练RBM,然后用训练好的RBM的隐单元的激活概率和原有的类别标签组成心得训练集,进而使用其他的分类算法训练分类器。
第二种就用途比较奇怪。其中的原因就是神经网络也是要训练一个权重矩阵和偏移量,但是如果直接用BP神经网络,初始值选得不好的话,往往会陷入局部极小值。根据实际应用结果表明,直接把RBM训练得到的权重矩阵和偏移量作为BP神经网络初始值,得到的结果会非常地好。
这就类似爬山,如果一个风景点里面有很多个山峰,如果让你随便选个山就爬,希望你能爬上最高那个山的山顶,但是你的精力是有限的,只能爬一座山,而你也不知道哪座山最高,这样,你就很容易爬到一座不是最高的山上。但是,如果用直升机把你送到最高的那个山上的靠近山顶处,那你就能很容易地爬上最高的那座山。这个时候,RBM就的角色就是那个直升机。
其实还有两种用途的,下面说说。
第三种,RBM可以估计联合概率p(v,h),如果把v当做训练样本,h当成类别标签(隐藏节点只有一个的情况,能得到一个隐藏节点取值为1的概率),就可以利用利用贝叶斯公式求p(h|v),然后就可以进行分类,类似朴素贝叶斯、LDA、HMM。说得专业点,RBM可以作为一个生成模型(Generative model)使用。
第四种,RBM可以直接计算条件概率p(h|v),如果把v当做训练样本,h当成类别标签(隐藏节点只有一个的情况,能得到一个隐藏节点取值为1的概率),RBM就可以用来进行分类。说得专业点,RBM可以作为一个判别模型(Discriminative model)使用。
分布式RBM可能遇到的问题
根据CD-K采样算法来进行的RBM,由于采样过程中,每次迭代均需前一次的抽样结果作为输入,所以该算法模型内部是无法进行模型并行的。
数据并行的设计需要考虑样本数据如何分割以及每次迭代最后的权值更新。
这篇关于一文理解受限玻尔兹曼机(RBM)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




