本文主要是介绍LeetCode、2300. 咒语和药水的成功对数【中等,排序+二分】,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 前言
- LeetCode、2300. 咒语和药水的成功对数【中等,排序+二分】
- 题目及类型
- 思路及代码
- 资料获取
前言
博主介绍:✌目前全网粉丝2W+,csdn博客专家、Java领域优质创作者,博客之星、阿里云平台优质作者、专注于Java后端技术领域。
涵盖技术内容:Java后端、算法、分布式微服务、中间件、前端、运维、ROS等。
博主所有博客文件目录索引:博客目录索引(持续更新)
视频平台:b站-Coder长路
LeetCode、2300. 咒语和药水的成功对数【中等,排序+二分】
来源:LeetCode专题《LeetCode 75》
题目及类型
题目链接:LeetCode、2300. 咒语和药水的成功对数
类型:基础算法/二分
思路及代码
思路:
首先对药水能量强度数组进行排序,接着我们去遍历所有的咒语,接着我们对药水能量数组进行二分,通过使用咒语与药水能量乘积来进行二分寻找边界值,来确定成功对数。
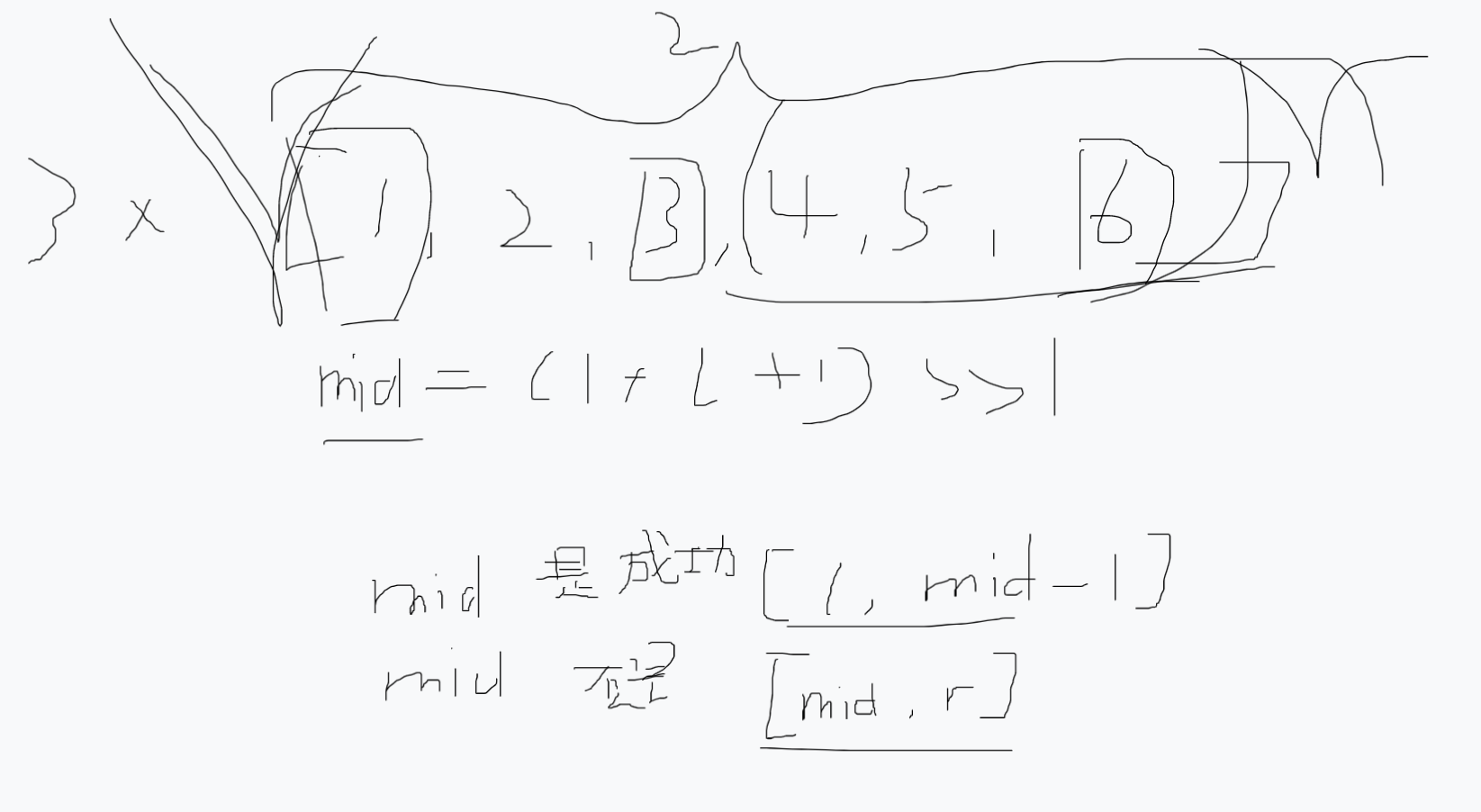
代码:
复杂度分析:时间复杂度O(n.logn);空间复杂度O(1)
class Solution {//排序+二分//找到最右边不成功的组合的最后一个位置public int[] successfulPairs(int[] spells, int[] potions, long success) {int n = spells.length, m = potions.length;//结果数组int[] res = new int[n];//对potions升序Arrays.sort(potions);//遍历所有的药水for (int i = 0; i < n; i ++) {int ans = 0;//二分int l = 0, r = m - 1;while (l < r) {//若是拆分为[l, mid - 1]、[mid, r],那么一旦有r = mid - 1,需要+1为l + r + 1int mid = (l + r + 1) >> 1;// System.out.printf("mid=%d\n", mid);if (check(1L * spells[i] * potions[mid], success)) {r = mid - 1;}else {l = mid;}}//找到目标值// System.out.printf("%d %d\n", l, r);//全部成功(根据r的情况值来判定)if (r < 0 || (r == 0 && 1L * spells[i] * potions[0] >= success)) {ans = m;}else if (l >= m || (l == m - 1 && 1L * spells[i] * potions[m - 1] < success)) { //全部不匹配(根据l的情况值来判定)ans = 0;}else {//若是找到区间范围的ans = m - l - 1;}//将结果添加到结果集res[i] = ans;}return res;}//检测public boolean check(long cur, long success) {if (cur >= success) return true;return false;}}
资料获取
大家点赞、收藏、关注、评论啦~
精彩专栏推荐订阅:在下方专栏👇🏻
- 长路-文章目录汇总(算法、后端Java、前端、运维技术导航):博主所有博客导航索引汇总
- 开源项目Studio-Vue—校园工作室管理系统(含前后台,SpringBoot+Vue):博主个人独立项目,包含详细部署上线视频,已开源
- 学习与生活-专栏:可以了解博主的学习历程
- 算法专栏:算法收录
更多博客与资料可查看👇🏻获取联系方式👇🏻,🍅文末获取开发资源及更多资源博客获取🍅
整理者:长路 整理时间:2024.1.19
这篇关于LeetCode、2300. 咒语和药水的成功对数【中等,排序+二分】的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




