本文主要是介绍LLM:Sinusoidal位置编码,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1:什么是大模型的外推性?
外推性是指大模型在训练时和预测时的输入长度不一致,导致模型的泛化能力下降的问题。例如,如果一个模型在训练时只使用了512个 token 的文本,那么在预测时如果输入超过512个 token,模型可能无法正确处理。这就限制了大模型在处理长文本或多轮对话等任务时的效果。
2:为什么要位置编码PE?
Transformer结构:并行输入。所以需要让输入的内容具有一定的位置信息。
句子1:我喜欢吃洋葱
句子2:洋葱喜欢吃我
3:绝对位置编码:
训练式位置编码:模型只能感知到每个词向量所处的绝对位置,无法感知词向量之间的相对位置。广泛应用于早期的transformer类型的模型,如BERT、GPT、ALBERT等。但其缺点是模型不具有长度外推性。因为位置编码矩阵的大小是预设的,若对其进行扩展,将会破坏模型在预训练阶段学习到的位置信息。例如将512*768扩展为1024*768,新拓展的512个位置向量缺乏训练,无法正确表示512~1023的位置信息。
Sinusoidal位置编码:这一点得到了缓解,模型一定程度上能够感知相对位置。Sinusoidal位置编码的每个分量都是正弦或余弦函数,所有每个分量的数值都具有周期性,并且越靠后的分量,波长越长,频率越低。
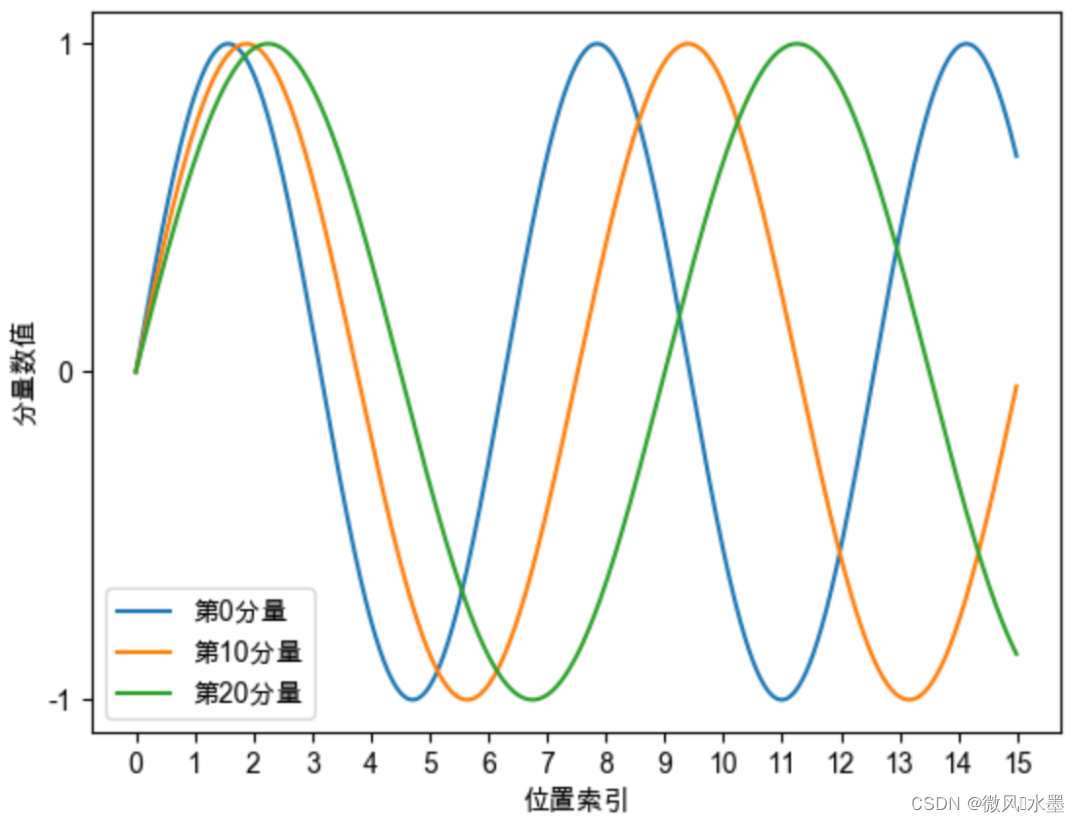
Sinusoidal位置编码还具有远程衰减的性质,具体表现为:对于两个相同的词向量,如果它们之间的距离越近,则他们的内积分数越高,反之则越低。如下图所示,我们随机初始化两个向量q和k,将q固定在位置0上,k的位置从0开始逐步变大,依次计算q和k之间的内积。我们发现随着q和k的相对距离的增加,它们之间的内积分数震荡衰减。
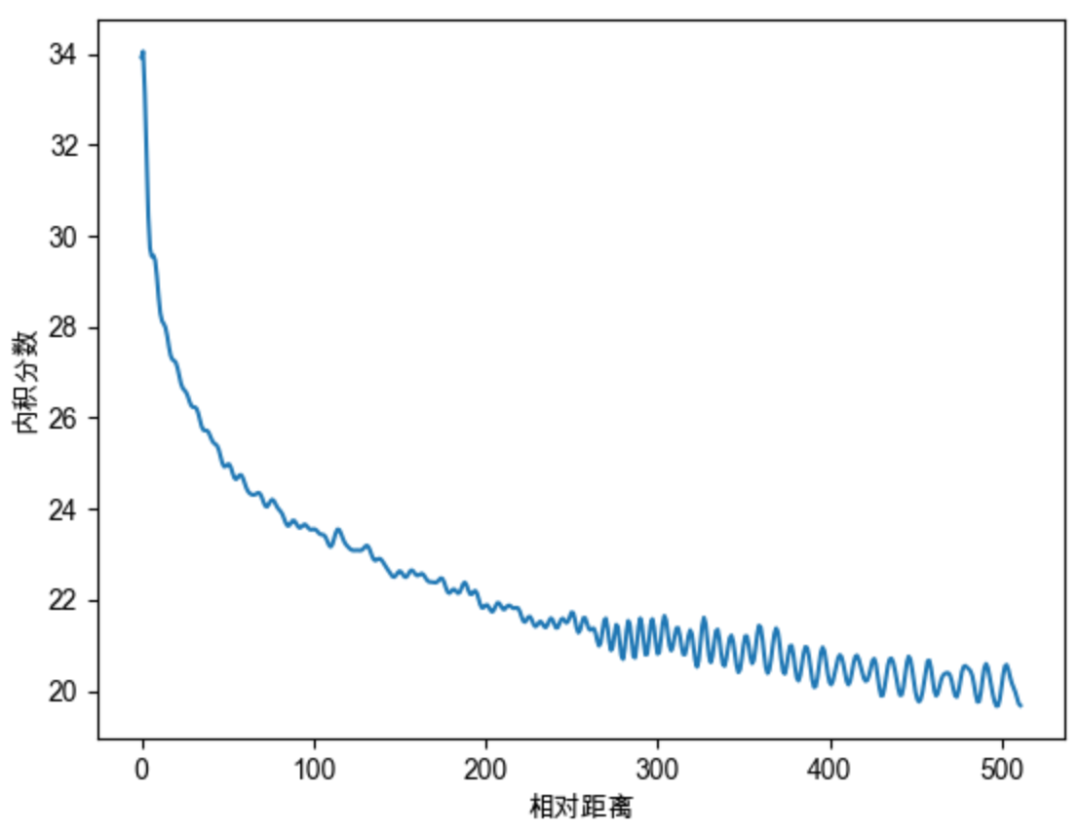
因为Sinusoidal位置编码中的正弦余弦函数具备周期性,并且具备远程衰减的特性,所以理论上也具备一定长度外推的能力。
4:Sinusoidal位置编码

:表示位置编码
:表示当前字符在输入sequence中的位置
:表示该字符嵌入的维度。
偶数位置使用sin, 奇数位置使用cos
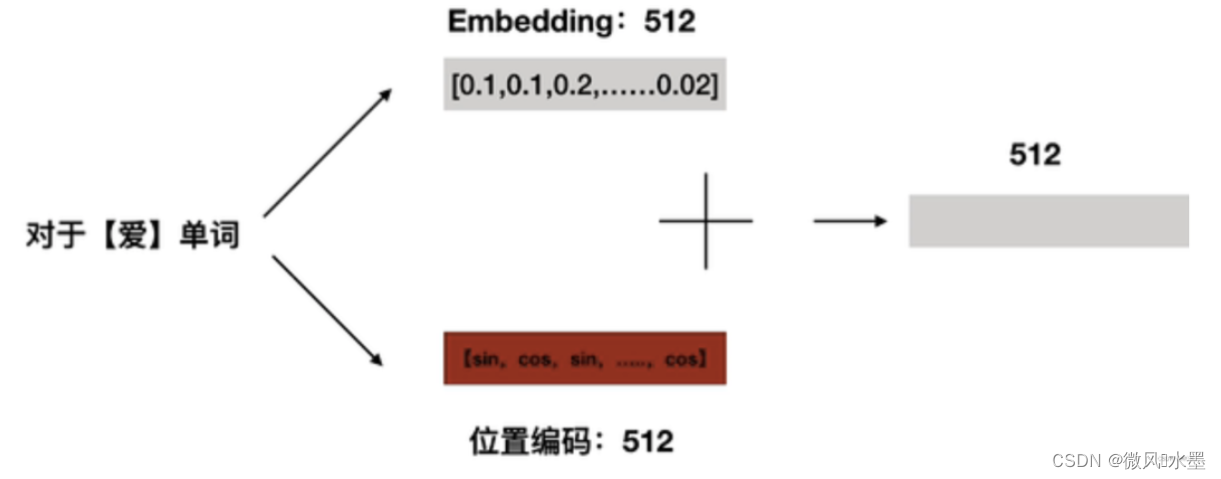
举例:假设每个词嵌入维度为512,如图所示:
[我, 喜,欢,你] <-----输入sequence
[0, 1, 2, 3] <-----对应位置

注:如果sequence长度不够,那么不足就直接使用padding用0填充。

这里以“爱”为例,pos = 1,来说明PE的计算:

计算完所有的PE后,将词嵌入与PE进行相加,即可得到带有位置信息的embedding。
ps:这里有一个小trick:
当emb和位置编码相加了之后,我们希望emb占多数,比如将emb放大10倍,那么在相加后的张 量里,emb就会占大部分。因为主要的语义信息是蕴含在emb当中的,我们希望位置编码带来的影响不要超过emb。所以对 emb进行了缩放再和位置编码相加。
python 代码1如下:更加直观
# position 就对应 token 序列中的位置索引 i
# hidden_dim 就对应词嵌入维度大小 d
# seq_len 表示 token 序列长度
def get_position_angle_vec(position):return [position / np.power(10000, 2 * (hid_j // 2) / hidden_dim) for hid_j in range(hidden_dim)]# position_angle_vecs.shape = [seq_len, hidden_dim]
position_angle_vecs = np.array([get_position_angle_vec(pos_i) for pos_i in range(seq_len)])# 分别计算奇偶索引位置对应的 sin 和 cos 值
position_angle_vecs[:, 0::2] = np.sin(position_angle_vecs[:, 0::2]) # dim 2t
position_angle_vecs[:, 1::2] = np.cos(position_angle_vecs[:, 1::2]) # dim 2t+1# positional_embeddings.shape = [1, seq_len, hidden_dim]
positional_embeddings = torch.FloatTensor(position_angle_vecs).unsqueeze(0)python 代码2如下:
def sinusoidal_position_embedding(batch_size, nums_head, max_len, output_dim, device):# (max_len, 1)position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(-1)# (output_dim//2)ids = torch.arange(0, output_dim // 2, dtype=torch.float) # 即公式里的i, i的范围是 [0,d/2]theta = torch.pow(10000, -2 * ids / output_dim)# (max_len, output_dim//2)embeddings = position * theta # 即公式里的:pos / (10000^(2i/d))# (max_len, output_dim//2, 2)embeddings = torch.stack([torch.sin(embeddings), torch.cos(embeddings)], dim=-1)# (bs, head, max_len, output_dim//2, 2)embeddings = embeddings.repeat((batch_size, nums_head, *([1] * len(embeddings.shape)))) # 在bs维度重复,其他维度都是1不重复# (bs, head, max_len, output_dim)# reshape后就是:偶数sin, 奇数cos了embeddings = torch.reshape(embeddings, (batch_size, nums_head, max_len, output_dim))embeddings = embeddings.to(device)return embeddings参考:
https://kaiyuan.blog.csdn.net/article/details/119621613
https://blog.csdn.net/qq_41915623/article/details/125166309
https://zhuanlan.zhihu.com/p/352233973
https://blog.csdn.net/u013853733/article/details/107853989
https://spaces.ac.cn/archives/8130
这篇关于LLM:Sinusoidal位置编码的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!