本文主要是介绍面试题浅解,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1.题 考查隐式数据类型转换 , C 默认的是将需要自动转换的从低级转换为高级具体情况如下:

那么什么时候会发生隐式数据类型转换呢 , 主要有下列的情况 ~:
a>算数运算式中低类型能转换为高类型.
b>复制表达式,右边表达式的值自动转换为左边变量的类型并赋值给它.
c>函数调用中参数传递时,系统隐式地将实参转换为形参类型,并赋值给形参.
d>函数有返回值时, 系统将隐式地返回值表达式类型转换为返回值类型,复制给调用函数.
注:不同的数据类型的数据进行操作时,应该先将其转换成相同的数据类型,然后进行操作,转换规则是由低级转换为高级.
2. 考查sizeof 计算结构和联合所占的字节数
3.考查位运算
看到题目,开始是让求平均数, 我们可以很简单地进行相加除以2,这里却用 a + (b-a)/2 这样做的好处就是防止相加的时候两个数过大, 上溢出.关于下面的功能(当然,需要给后面整体加上括号,符号优先级问题).关于这个为什么这样写, (a&b) + ((a^b)>>1) , 大家知道右移1位 , 相当于除以二. 但是 a&b和a^b是什么意思呢. 我们先来看一个用位运算时现任何两个数的加法的操作.
:
首先一位的加法(不产生进位的情况), 用^处理就好了. 关于处理进位情况,当两个位都为1的时候,产生进位. 那么这时就可以用&操作, 保留所有需要进位的位 , 然后对结果进行一次左移, 我们知道左移就相当于进位了. 然后其它位的处理,就使用^进行, 我们把操作分为了两部分, 一部分用来处理进位情况, 一部分用来处理不进位的那些位. 然后我们进行迭代. 直到不产生进位的时候, 也就是& <<1 操作的值为0 的时候. 代码附一下 :
这是一个迭代的操作, 所以我们可以使用递归来完成 . 同样的想实现减法, 给b取非 +1, 很简单就完成了.01 #include <stdio.h>0203intcal (inta ,intb) {0405returnb ? cal ((a ^ b) , (a & b)<<1) : a ;06 }0708intmain(intargc,char*argv[])09 {10inta , c ;1112scanf("%d%d",&a , &c) ;1314printf("val = %d\n", cal (a , c) );1516return0;17 }
然后大家再看这个题 前面那个a&b同样的是判断有没有进位, 如果有进位,那么就保留那一位,因为要除以二,所以不用向左平移 , 后面是处理不用进位的部分 , 同样的需要除以二 , 用向右移位完成. 好啦 ~ 就是这个思路. 至于乘法 , 除法 ,我就没有写了.大家可以研究研究.
4.考查sizeof与strlen的区别,大家应该都知道了. sizeof 在编译后就已经没有了, 已经被计算出来的值替换了. 而strlen则是运行时计算的.sizeof计算的是后面对应的数据类型的字节大小,值得一提的是数组是一个构造数据类型,它是一个整体.应该以整体计算.可以看一个例子.
看一下反汇编以后的代码:01 #include <stdio.h>0203intmain( )04 {05inta=3 , b ;0607 b = a +sizeof(a) ;0809return0;10 }
080483f0 <main>:80483f0: 55 push ebp80483f1: 89 e5 mov ebp,esp80483f3: 83 ec 10 sub esp,0x1080483f6: c7 45 fc 03 00 00 00 mov DWORD PTR [ebp-0x4],0x380483fd: 8b 45 fc mov eax,DWORD PTR [ebp-0x4]8048400: 83 c0 04 add eax,0x48048403: 89 45 f8 mov DWORD PTR [ebp-0x8],eax8048406: b8 00 00 00 00 mov eax,0x0804840b: c9 leave 804840c: c3 ret 804840d: 66 90 xchg ax,ax804840f: 90 nop可以看到,add后面的源操作数直接就是4了.
5.考查位域
C 不允许每个位域成员超过基类型的大小.使用sizeof计算位域的大小,将返回基类型的大小,即字节对其以后的大小.关于位域,这里有很多需要注意的点,我在这一一列举一下:
1>.linux下位域可以横跨两个字节,即一个位域可以超过8bit , 但是不能超过自己的类型的sizeof.
2>.不允许对位域成员进行取地址.
3>.如果相邻字段位域类型相同,且前后加起来的大小不超过sizeof类型的大小 , 则后面字段将紧临前一字段存储.
4>.如果相邻字段类型相同但是前后加起来大于类型的sizeof大小,则另起炉灶.
5>.相邻字段间的类型不同,则不同的编译器处理不同.
6>.整个结构体大小为最宽的类型的大小的整数倍.
5.考查位域
C 不允许每个位域成员超过基类型的大小.使用sizeof计算位域的大小,将返回基类型的大小,即字节对其以后的大小.关于位域,这里有很多需要注意的点,我在这一一列举一下:
1>.linux下位域可以横跨两个字节,即一个位域可以超过8bit , 但是不能超过自己的类型的sizeof.
2>.不允许对位域成员进行取地址.
3>.如果相邻字段位域类型相同,且前后加起来的大小不超过sizeof类型的大小 , 则后面字段将紧临前一字段存储.
4>.如果相邻字段类型相同但是前后加起来大于类型的sizeof大小,则另起炉灶.
5>.相邻字段间的类型不同,则不同的编译器处理不同.
6>.整个结构体大小为最宽的类型的大小的整数倍.
当然 , 这里说的这些也不能完全概括,之后的需要大家去补充。 关于上面的字节大小, 大家可以自己去验证。
下面再给大家加一点点东西,比特序(wiki给的定义):
In computing , bit numbering (or sometimes bit endianness ) is the convention used to identify the bit positions in a binary number or a container for such a value. The bit number starts with zero and is incremented by one for each subsequent bit position.
大概意思和little-edian和big-endian一样, 不过前者是针对于字节为单位的,现在则讨论的是以bit为单位的。先来看看这样的一道题:
猜猜结果会是怎么样,我给大家画一下(字符0对应的ASCII 值为48 也就是00110000)1 #include <iostream>2 #include <cstring>3usingnamespacestd;4structA5 {6inta:5;7intb:3;8 };9intmain(void)10 {11charstr[100] ="012345";12structA c;13memcpy(&c, str,sizeof(A));14 cout << c.a << endl;15 cout << c.b << endl;16return0;17 }

这里就涉及到LSB(least signficant bit) , MSB(most signficant bit),小端的CPU 一般采用的都是LSB 0位序 。大端的cpu可能采取LSB也可能采取MSB 。 (关于大端小端,下面会讲)
其实LSB也就是一个“高高低低”的的原则,即数据的最低位放在字节的第0位,从又至左一次递增,所以后面5位是a的数据,前面3位是b的数据,这样就可以解释结果(-16 1)了。所以MSB就和LSB相反喽 。好了,就扯这么多,详细的大家参考这个链接 http://en.wikipedia.org/wiki/Bit_numbering和这位前辈的博客 http://blog.chinaunix.net/uid-25909722-id-2749575.html(注意自己去考证里面的内容哦!实践是检验真理的唯一标准哦。)
6.考查while , do-while 这个 , 就不用多讲了吧 ~ , 相信大家都狠狠懂。
7.考查逗号表达式和switch语句特点,这道题详细的可以参考C99ISO文档 (135页), 里面有详细的说明,我就不赘述了。简单说说吧。
首先逗号表达式大家应该狠是清楚吧, 整个表达式的值是最后一个子表达式的值。而且switch后面的表达式必须是interger类型。 case标签必须是constant expression , 也会发生整型提升。在switch的域内 ,case标签外部的语句,均为无效语句,若是有定义语句,是允许的 , 如果是数据定义,则无论其初始化与否,其值在未重新赋值之前,都是未定义的。(GCC允许在switch中定义函数,clang则不允许,这个行为应该是未定义吧, 由编译器实现决定。尽量避免这样做。)
8.这个题就不用细讲了吧 , 记住这个就行了:a[1] = *(a+1) = *(1+a) = 1[a] ;数组元素的定位也是通过指针实现的。
9.考查数组和指针的联系。
10.考查float和double的精度问题。
都知道的是float的精度小于double的精度,很简单么,double占得字节多呗!
默认的float小数点后最多有7位有效数字,但是能保证精度准确的只有前6位, 从第7位开始就是不确定的了。但是double就不一样了,double默认的小数点后可以有16位,但是能保证精度的只有前15位,所以,拿一个float与一个字面值常量进行比较,当然得不到你想要的结果。因为字面值常量在C里面是做为double类型来处理的。这样去比较是肯定会出问题的。所以我们比较两个数的时候最好做到类型统一,减少隐式转换带来的副作用。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | #include <stdio.h> int main () { float PI = 3.14000000000000000; printf ( "PI = %.10f \n" , PI) ; printf ( "double PI = %.10lf \n" , 3.14) ; if (PI == 3.14) { printf ( "That's impossible !\n" ) ; } return 0 ; } |
结果很明显了[tutu@localhost 面试]$ ./a.out PI = 3.1400001049 double PI = 3.1400000000 [tutu@localhost 面试]$
11题考查系统栈的一些知识, 首先我们应该知道,局部变量的值是存储在栈里面的。而且栈是向下增长的。看一下反汇编以后的代码~ , (推荐大家去读一下刘欢学长的 浅谈缓冲区溢出之栈溢出 ) :
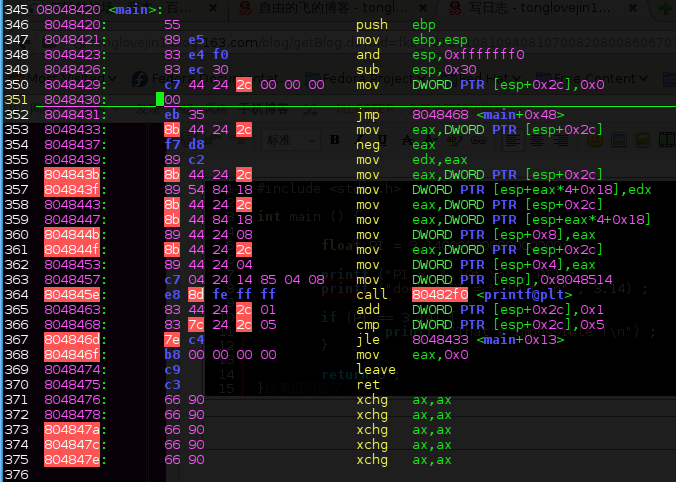
然后内存中的占空间图如下:
关于i为什么分配在数组之前,我测试过放在数组后定义,但是汇编代码是一样的.在崔娇娇学姐那里却不对了,i分配的时候分在了数组的下面.呵呵, 这个就有些让人费解了,找原因,最后看看gcc版本不同. 还有,在64位gcc编译的时候,不会出现这样的溢出.详细的有兴趣大家去研究研究吧~~~ .
12题考查的还是缓冲区问题,但是这个是输入缓冲区
gets是有缓冲的函数,意思是输入会先保存到一个buffer中,当buffer满或者强制刷新的时候(如:换行,fclose操作),buffer会刷新.
缓冲分为:全缓冲,行缓冲,无缓冲 .分别举例说一下吧.
全缓冲: 指的是系统在填满标准IO缓冲区之后才进行实际的IO操作;注意,对于驻留在磁盘上的文件来说通常是由标准IO库实施全缓冲。
行缓冲: 标准IO在输入和输出中遇到换行符时执行IO操作;注意,当流涉及终端的时候,通常使用的是行缓冲。
无缓冲: 无缓冲指的是标准IO库不对字符进行缓冲存储;注意,标准出错流stderr通常是无缓冲的。
我们可以分别实验一下:(摘UNIX环境高级编程8章)
12题考查的还是缓冲区问题,但是这个是输入缓冲区
gets是有缓冲的函数,意思是输入会先保存到一个buffer中,当buffer满或者强制刷新的时候(如:换行,fclose操作),buffer会刷新.
缓冲分为:全缓冲,行缓冲,无缓冲 .分别举例说一下吧.
全缓冲: 指的是系统在填满标准IO缓冲区之后才进行实际的IO操作;注意,对于驻留在磁盘上的文件来说通常是由标准IO库实施全缓冲。
行缓冲: 标准IO在输入和输出中遇到换行符时执行IO操作;注意,当流涉及终端的时候,通常使用的是行缓冲。
无缓冲: 无缓冲指的是标准IO库不对字符进行缓冲存储;注意,标准出错流stderr通常是无缓冲的。
我们可以分别实验一下:(摘UNIX环境高级编程8章)
#include <stdio.h> #include <string.h> #include <unistd.h> char buf[] = "Let's start !\n"; int main() { pid_t pid; if(write(STDOUT_FILENO, buf, strlen(buf)) != strlen(buf)) { fprintf(stderr, "write error"); return 0; } printf("before fork()...\n"); if((pid = fork()) == -1) { fprintf(stderr, "fork error"); return 0; } sleep(2); printf("parent process id:%d ", getppid()); printf("process id:%d\n", getpid()); return 0; } tutu@localhost 面试]$ ./a.out
Let's start !
before fork()...
parent process id:2004 process id:2991
parent process id:2991 process id:2992
[tutu@localhost 面试]$ [tutu@localhost 面试]$ ./a.out > test.txt
[tutu@localhost 面试]$ vim test.txt
Let's start !
before fork()...
parent process id:2004 process id:2996
before fork()...
parent process id:2996 process id:2997
[tutu@localhost 面试]$还有要注意的时gets函数,绝对不推荐大家使用,因为这货不对输入长度检查,输入多少就往栈里尽可能扔多少,完全不估计溢出的情况,所以就是这货引发了1988年一次规模比较大的蠕虫病毒.原因什么的,大家有兴趣可以自己研究,欢学长的博客建议大家一定要看看.以后就赶快扔了gets吧,全部使用fgets (char *s , int size , FILE *stream) .
13.就不用讲了, 大家都会的 . 排序重组么.
14.考查static 的作用, 首先应该知道的是static 变量保存在全局静态区 , 是全局静态区 , 生存期整个程序 , 全局静态变量作用域本文件.局部的那就只能在局部.需要注意的是static 变量初始化的时候必须以常量或者常量表达式.不初始化时,编译器给你自动初始化为0 .
题目中的初始化方式不对, 由于逗号表达式的值是不定的,并非常量或者常量的表达式.
15. 考查大端小端,实际上就是数据在内存中的存放顺序. 不同的处理器生产商有自己不同的设计. 可以参见这位大神的 ce123的博客,很经典的说.我在这里也是retell.
一般小端的机器有:x86 DEC
大端机器有:POWER PC , IBM , SUN
可能是大端也可能是小端:ARM MAC
现代的CPU都可以大端小端共存的 , 通过跳线来对不同的情况作出处理. 现在我们来大概看一下自己的pc是哪种endian .
#include <stdio.h>int main(int argc, char *argv[])
{int a = 0x12345678 ; char * p = (char *) &a ;printf ("%x\n" , *p) ;printf ("%x\n" , *(p+1)) ;printf ("%x\n" , *(p+2)) ;printf ("%x\n" , *(p+3)) ;return 0;
}[tutu@localhost 面试]$ ./a.out
78
56
34
12
[tutu@localhost 面试]$
可以看到高位自己放在了高地址, 低位字节放在了低地址.这是典型的高高低低.我们这里的单位是字节即8bit为atomic elements.
对应大端呢, 就是倒过来了.
JAVA和网络传输都使用的大端, 所以,我们在做网络相关的开发时, 总是需要这几个函数:htonl(), htons(), ntohs(),ntohl() , 就是用来转换字节序的.详细的大家自己去google吧.
16题考查C预处理都做了什么即 , 宏替换在先还是去除注释在先 .这个在C99文档里(147页左右)有相关说明.这里我大概说一下这里有前辈的链接 C预处理的步骤
1.三连符替换成相应的单字符
2.把用
\字符续行的多行代码接成一行比如 #define STR "hello, "\"world"替换成一行
3.把注释(不管是单行注释还是多行注释)都替换成一个空格。
4.处理Token(记号)和空白字符 (即分割)
5.宏展开,包含源文件
...
后面的大家去研究吧,更细的东西在链接里.大家有兴趣去看看吧.
17题考查枚举常量,这个相信大家都会了 , 就不多讲了.
18题又考查sizeof , 这个上面已经给大家将了,可以参照上面的方法.做一下,一目了然.
19.纯粹时考查你的细心程度. 当然这也告诉大家 , 注意自己的代码风格,格式.别到最后自己都看不懂自己的代码了.
21题 我相信大家一定会的.
20题23题24题25题都是编程题目, 这个我觉得要是我讲的画, 你的思路就会被我的想法占据. 我也相信大家都会的. 这里只简单说一下.
int my_strcmp (const char * dest ,const char * source ) {if ( NULL == dest || NULL == source ) {printf ("error\n") ;exit (-1) ;}while (( 0 != *dest ) && ( 0 != *source )) {if (tolower(*dest) == tolower(*source)) {dest++ ;source++ ;}else break ;}return *dest - *source ;}
23题 用两个变量(max , less_max)分别保存最大和次大,假定第一个节点最大,赋值给max , 并初始化less_max为INT_MIN , 每次向前比较, 发现比当前最大值大 , 将max更新,并同时更新less_max为max之前值, 当发现当前值比max小,这时也要比较是否比less_max大,如果大,则更新less_max.嗯 , 思路就是这样.
24.字符串匹配问题,有库函数可以调的 char * strstr(const char * , const char *),返回第一次出现子串的地址. 这里让大家手动实现,有两种方法, BF , KMP , 这是两种不同的思想.BF 是暴力去匹配, 也是我们平时用的多的. KMP则是使用一定的算法(呜呜, 有点难理解) . 这个有小组张续学长的博客在,大家上去可以仔细研究. KMP详细过程
25.实现一个范型的swap , 方法很多, 我这里直接调的库函数
void swap (void * dest , void * source , int size ) {void * p = malloc (size) ;memcpy (p , dest , size) ;memcpy (dest , source , size) ;memcpy (source , p , size) ;free (p) ;
}这篇关于面试题浅解的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






