本文主要是介绍67.基于控制流编程,优化Go代码可读性,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 一:简介
- 二、代码整洁小技巧:基于控制流编程
- 三、总结
代码地址:https://gitee.com/lymgoforIT/golang-trick/tree/master/40-clean-code-controll-flow
一:简介
如何写好代码,一千个人眼中有一千个哈姆雷特,但是我认为有一点的是写好代码的公理,不可撼动,即对代码可读性以及可扩展性的追求。工作中很容易遇到可读性不佳的代码,使得对于旧有代码的维护和分析困难重重,心力憔悴。
基于“严于律己,宽以待人”的思想,遇到这种旧有代码尚可以接受,但为了避免未来这种可读性不佳的代码出于己手,我们不得不认识到一个问题——如何提高代码的可读性,使得代码变得整洁,甚至赏心悦目。
下面就从“控制流”的角度分享一下对提高代码可读性的一些思考。
什么是控制流
什么是控制流?狭义上理解来说控制流是计算机程序中的一种基本概念,它指的是程序执行的顺序和方式。在编码中,控制流用于控制程序的执行流程,包括条件判断、循环、函数调用等。
狭义上的理解过于底层,但从本质上来说,控制流其实就是一段执行流程。如果站在业务系统层面对控制流进行广义层面理解:控制流是对于任意一个系统的任意系统行为的步骤化拆解。
例如对于用户详细信息查询行为进行步骤化拆解,可以拆解为:查询条件校验 -> 查询用户基本信息 -> 根据用户基本信息查询用户详细信息 -> 结果校验 -> 返回。以上对于系统行为的步骤拆解方式,拆解出来的步骤1 -> 步骤2 -> 步骤3 -> ……,总结起来其实就是行为的控制流。
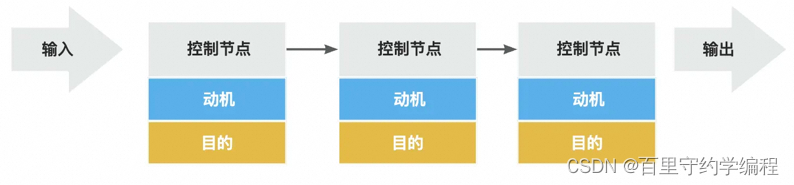
即任何系统行为都可以拆解为一段控制流。 而我理解的业务系统层面广义控制流具有以下特性:
-
控制流描述目的或动机,对于控制流中的任意流程节点,其只关心该步骤的目的或者动机,与实现目的的过程没有关系,于此相反,控制节点反而是对一段过程的总结。 -
控制流与实现细节无关, 对于控制流中的任意流程节点,无论你如何实现它,流程节点的目的和意义都不会发生变化。例如对于用户详情查询控制流中的“查询用户基本信息”节点而言,无论你的实现细节是从缓存中查询还是从数据库中查询,其目的就是“输出用户信息交付给控制流下一流程节点”,不会随着存储源的变化而发生改变。
总结起来就是抽象,抽出函数、抽出接口,面向对象、面向接口编程
二、代码整洁小技巧:基于控制流编程
基于控制流编程可以极大的提升代码的可读性。下面通过一个简单的例子来看看如何找到控制流以此对一个冗长混沌的代码一步一步进行可读性的优化的。
假如有一个 场景,将用户信息拆分为了用户基本信息和用户详情信息,有一个接口需要返回用户全部信息。如下:
domain/user.go
package domaintype User struct {Id stringName stringAge int64NickName stringPhone stringAddress string}
type UserDo struct {UserId stringUserName stringUserAge int64
}type UserDetailDo struct {NickName stringPhone stringAddress string
}
两个dao
dao/user_detail.go
package daoimport "golang-trick/40-clean-code-controll-flow/domain"type UserDetailDao struct {
}func (d *UserDetailDao) QueryUserDetailByCondition(param interface{}) *domain.UserDetailDo {return nil
}dao/user_info.go
package daoimport "golang-trick/40-clean-code-controll-flow/domain"type UserInfoDao struct {
}func (d *UserInfoDao) QueryUserByCondition(param interface{}) *domain.UserDo {return nil
}
service/user_service.go
package serviceimport ("errors""golang-trick/40-clean-code-controll-flow/dao""golang-trick/40-clean-code-controll-flow/domain"
)type UserService struct {UserInfoDao dao.UserInfoDaoUserDetailDao dao.UserDetailDao
}func NewUserService() *UserService {return &UserService{}
}func (us *UserService) queryUserDetail(queryCondition domain.UserDo) (*domain.User, error) {if queryCondition.UserId == "" {return nil, errors.New("用户Id不能为空")}if queryCondition.UserName == "" {return nil, errors.New("用户名不能为空")}paramMap := make(map[string]interface{})paramMap["username"] = queryCondition.UserNameparamMap["userId"] = queryCondition.UserIduserDo := us.UserInfoDao.QueryUserByCondition(paramMap)if userDo == nil {return nil, errors.New("该用户基本信息不存在")}paramMap = make(map[string]interface{})paramMap["userId"] = queryCondition.UserIduserDetailDo := us.UserDetailDao.QueryUserDetailByCondition(paramMap)if userDetailDo == nil {return nil, errors.New("该用户详情不存在")}return &domain.User{Id: userDo.UserId,Name: userDo.UserName,Age: userDo.UserAge,NickName: userDetailDo.NickName,Phone: userDetailDo.Phone,Address: userDetailDo.Address,}, nil}上述service/user_service.go用户信息查询代码是我们在工作中可能真实遇到的例子的简化版,这种“流水账”似的代码在工程开发中比比皆是,造成代码流水账的原因往往是二次扩展时采取在代码的原有基础上进一步堆叠逻辑的方式,让方法的进一步熵增,逐渐混沌,导致一个方法几百上千行,失去维护价值。
描述目的与动机
基于控制流编程,首先是找到一个系统行为的控制流。那么如何将一个系统行为翻译成为一段控制流呢,这其中其实分为两种模式:正向拆解、逆向还原。
正向拆解
正向拆解比较好理解,我们只需要对系统行为进行合理的推演,再根据过往的经验,总结出一段控制流程即可。比如还是这个例子:用户信息的查询行为,根据数据查询的通用模版,分为前置校验、查询、后置校验、返回结果几个步骤,我们可以得到用户查询行为的控制流:查询条件校验 -> 查询用户基本信息 -> 根据用户基本信息查询用户详细信息 -> 结果校验 -> 返回。
逆向还原
逆向还原稍微复杂一点,非常考验程序员的抽象总结能力,即给你一段冗长混沌的流水账过程代码,对其中的控制流进行总结和提取,这种情况一般发生在对一段“散发着陈年香气”的老代码进行重构的时候。但万变不离其宗,依旧是对代码进行整体分析,对动机一致、目的一致的段落进行提取,抽象为控制流节点。将整段冗长的代码总结为几个关键步骤,组合成为控制流。
套用这个方法,可以通过控制流构建对于上述冗长代码进行可读性上的进行极大优化:
package serviceimport ("errors""golang-trick/40-clean-code-controll-flow/dao""golang-trick/40-clean-code-controll-flow/domain"
)type UserService struct {UserInfoDao dao.UserInfoDaoUserDetailDao dao.UserDetailDao
}func NewUserService() *UserService {return &UserService{}
}func (us *UserService) queryUserDetail(queryCondition domain.UserDo) (*domain.User, error) {// 1. 参数校验err := us.validateQueryCondition(queryCondition)if err != nil {return nil,err}// 2. 查询用户基本信息userDo, err := us.queryUserInfo(queryCondition.UserName, queryCondition.UserId)if err != nil {return nil,err}// 3. 查询用户详细信息userDetailDo, err := us.queryUserDetailInfo(queryCondition.UserId)if err != nil {return nil,err}// 4. 返回结果return &domain.User{Id: userDo.UserId,Name: userDo.UserName,Age: userDo.UserAge,NickName: userDetailDo.NickName,Phone: userDetailDo.Phone,Address: userDetailDo.Address,}, nil}// ----------------------私有方法:步骤实现细节-------------------------func (us *UserService) validateQueryCondition(queryCondition domain.UserDo) error {if queryCondition.UserId == "" {return errors.New("用户Id不能为空")}if queryCondition.UserName == "" {return errors.New("用户名不能为空")}return nil
}func (us *UserService) queryUserInfo(name,id string ) (*domain.UserDo ,error){paramMap := make(map[string]interface{})paramMap["username"] = nameparamMap["userId"] = iduserDo := us.UserInfoDao.QueryUserByCondition(paramMap)if userDo == nil {return nil, errors.New("该用户基本信息不存在")}return userDo,nil
}func (us *UserService) queryUserDetailInfo(id string ) (*domain.UserDetailDo ,error){paramMap := make(map[string]interface{})paramMap["userId"] = iduserDetailDo := us.UserDetailDao.QueryUserDetailByCondition(paramMap)if userDetailDo == nil {return nil, errors.New("该用户详情不存在")}return userDetailDo,nil
}
上述代码看似只是抽了几个方法抽象,实则不然,深挖这背后的动机,这其实隐含着解构过程的思想。为什么声明式编程比命令式编程更加具有优势,究其本质就是其面向目的而不是过程的宗旨,这不仅仅是避免了复杂的过程带来的副作用,而且增加了代码整体的可读性。而此处我们将过程细节进行分类封装于以目的命名的方法中,而在主流程中只留下各种以目的作为命名的方法的编排,使得系统行为的控制流程得以凸显,能够让代码读者迅速抓取整段代码各个部分的目的和动机。这其实和声明式编程的内核不谋而合。
以上,我们可以得到提高代码可读性一个很重要的技巧:以描述目的和动机的方式解构过程,而不是盲目堆叠过程。
藏在暗处的维护隐患
但仅此而已吗,只是做了几个方法的拆分就足够吗。此时我们只要往代码的长尾运维角度进行思索,就能立刻找到破绽——“流程怎么进行扩展呢?”。目前我们控制流实现方式存在一个很大的隐患:控制流节点的实现依赖于源码细节。
这一点几乎是致命的,由于控制流节点只描述目的和动机,过程的实现方式必然不止一种,假如后期运维时需要对控制流节点的过程进行二次扩展,就会立刻回到堆叠过程的混沌状态,可读性急剧下降。关于这一点,控制流的第二特性:细节无关原则给出了解法。
细节无关原则
早在三四十年前,当面向对象编程还没有兴起的时候,那时的程序员都是采用面向过程的C语言进行技术研发。对于一段程序的控制流来说,想要实现细节无关原则是一件极其困难的事情。缺少了面向对象的多态特性,接口概念的缺失让一段控制代码无可避免的会依赖于源码细节。而正是由于面向对象的一系列编程语言的出现让控制流脱离源码细节成为了可能。这其中的关键秘诀就是依赖反转。
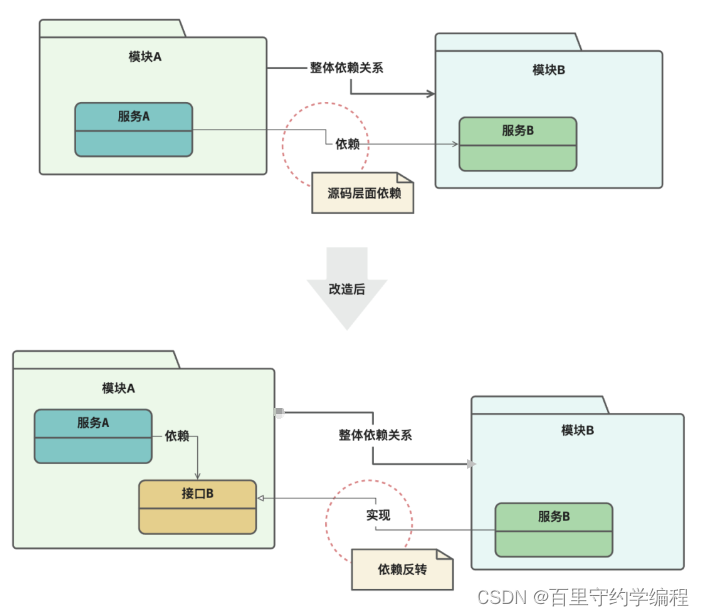
在面向过程编程的时代,控制流的特性就是控制流的方向和实现细节的依赖方向是相同的。而不幸的是,我们第一版的控制流的依赖状态也是控制流程和实现细节的依赖方向吻合,也就是说,我们的初版代码依旧没有摆脱面向过程编程的思想桎梏。
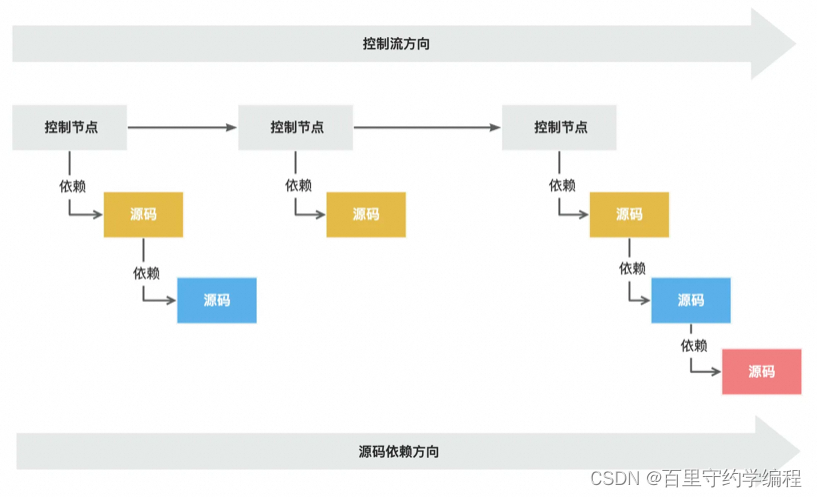
但别忘了,我们可是使用的Go这一面向对象编程的语言利器,我们完全可以通过多态将这种依赖关系进行反转。
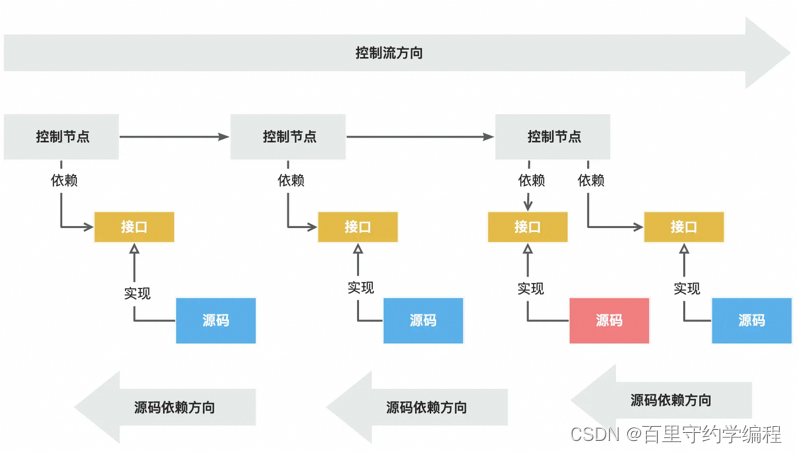
图中可以看到,源码(具体实现)依赖了接口的存在,因为业务依赖的是接口,使用的是接口,不依赖具体实现,所以是具体实现依赖了接口,只有符合了接口,才能用到业务代码中,否则具体实现没有用处,这就是依赖倒转,即不是业务流程依赖具体的实现,而是具体的实现通过实现接口依赖了业务的存在。
利用依赖反转实现细节无关原则,体现到代码上如下所示:
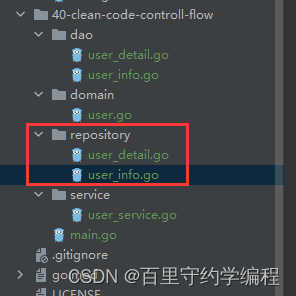
建立了两个repository接口
repository/user_detail.go
package repositoryimport "golang-trick/40-clean-code-controll-flow/domain"type UserDetailQueryRepository interface {QueryUserDetailByCondition(param interface{}) *domain.UserDetailDo
}repository/user_info.go
package daoimport "golang-trick/40-clean-code-controll-flow/domain"type UserInfoDao struct {
}func (d *UserInfoDao) QueryUserByCondition(param interface{}) *domain.UserDo {return nil
}UserService中也就不要依赖具体的实现了,而是依赖接口,改动如下: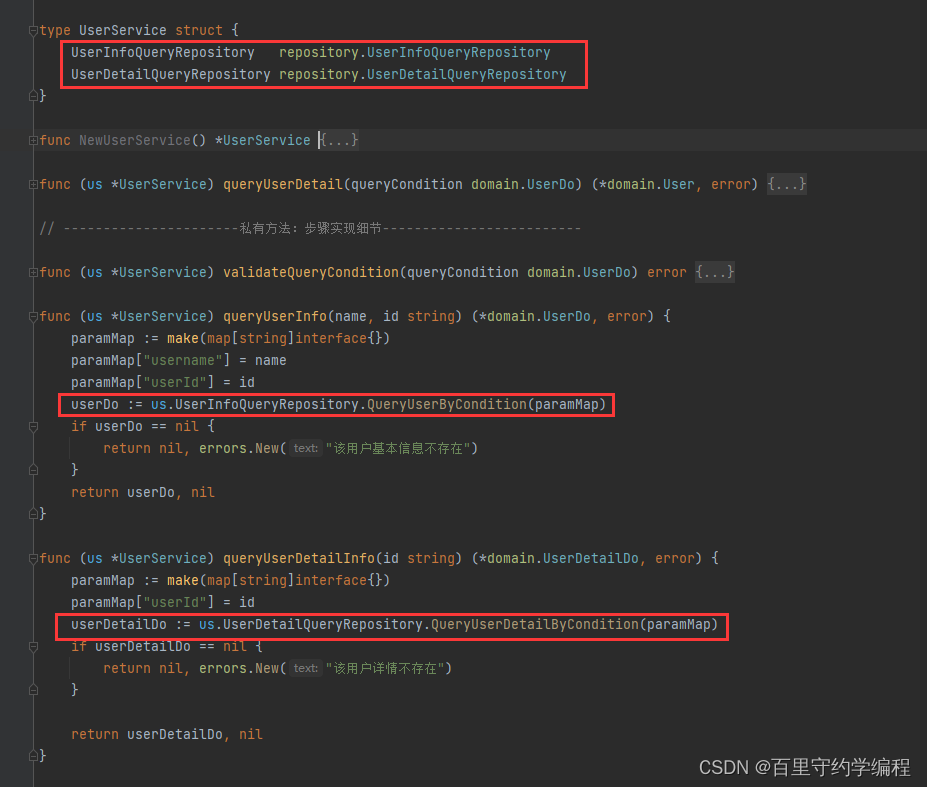
这段代码里面利用多态做了一件事: 将DAO封装为Repository仓储接口层,其背后的动机是对设备无关原则的遵循。
关于设备无关原则,这里展开来多说一点。
为什么UNIX操作系统会将IO设备设计成插件形式呢,因为自20世纪50年代末期以来,我们学到了一个重要经验:程序应该与设备无关。这个经验从何而来呢?因为一度所有程序都是设备相关的,但是后来我们逐渐发现其实真正需要的事情是在不同的设备上实现同样的功能。
——《架构整洁之道》
因此,以设备无关原则作为出发点,仓储层在系统中应该作为外部存储的准入标准而存在。我们通过分析系统IO交互诉求在仓储层中构建具体的、包含动机和目的的访问接口,外部存储必须实现仓储层以集成到系统的核心领域中。
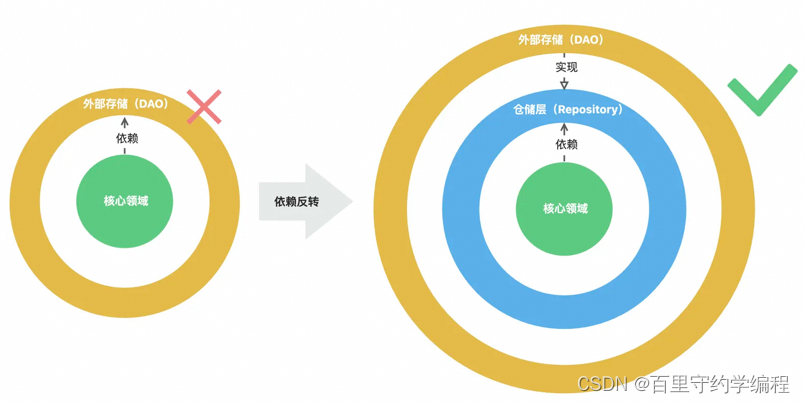
将系统的用户信息查询诉求抽象为了repository的方法,规定的入参和出参,以此在仓储层留落领域信息,如果需要通过关系型数据库实现用户信息查询功能,就应该实现该仓储层接口,于此封装存储过程的源码细节,而不是直接将源码细节耦合在系统核心领域中。这样的话后期如果我们需要扩展用户信息的IO方式,比如从缓存中获取,可以非常轻松的进行扩展并替换核心领域中的存储来源。
所以仓储层是由其存在于系统中并扮演关键性角色的价值的,但很可惜的是,在工作中很多工程系统都没有认真构建仓储层,导致后期扩展出现困难,以至于加一个缓存需要大刀阔斧的对系统核心流程进行重构。
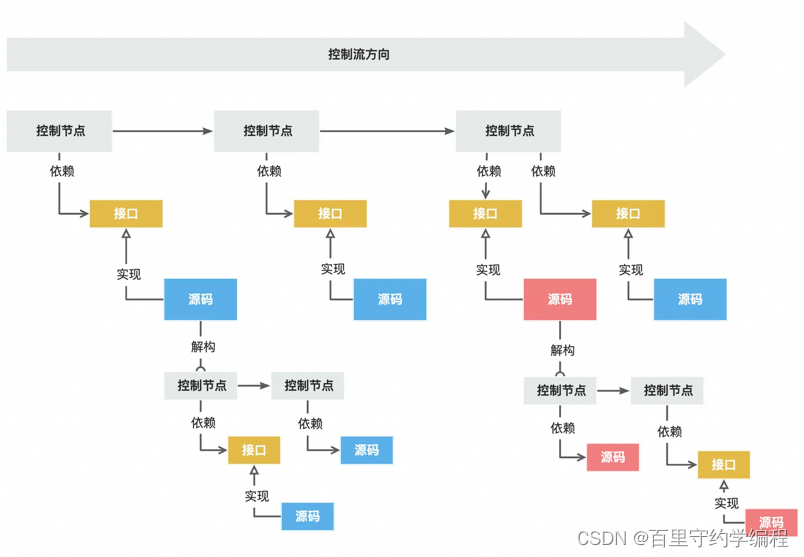
这里扯远了,我们回到正题上来,通过多态进行依赖反转,我们使得源码细节脱离了控制流的实现,这样做有什么好处呢?好处就是脱离了控制流实现的源码也可以通过控制流进行过程解构,比如脱离了控制流的Repository具体实现可以提炼自己的控制流,以此面对后续可能出现的能力扩展
控制流对于过程的解构其实就是一个递归的过程,逐步将长流程解构为一个个独立存在,保证可扩展性的流程子节点。
三、总结
上述的所有内容涉及到了3种代码的组织方式:
- 过程堆叠模式
- 基于目的和动机描述的控制流模式
- 基于目的和动机描述并且细节无关的控制流模式
对于这三种代码组织方式应该辩证看待,不是说后一种方式就比前一种好,细节无关的控制流就一定优于细节相关的控制流,因为系统复杂度随着代码过程的抽象和拆解增加了,而系统的复杂度的增加不一定就意味着可读性的提升,两者不是正相关关系,而是非线性的:随着系统复杂度的增加可读性会提升,但随着系统复杂度达到一个阈值,复杂度继续增加时可读性反而降低了。
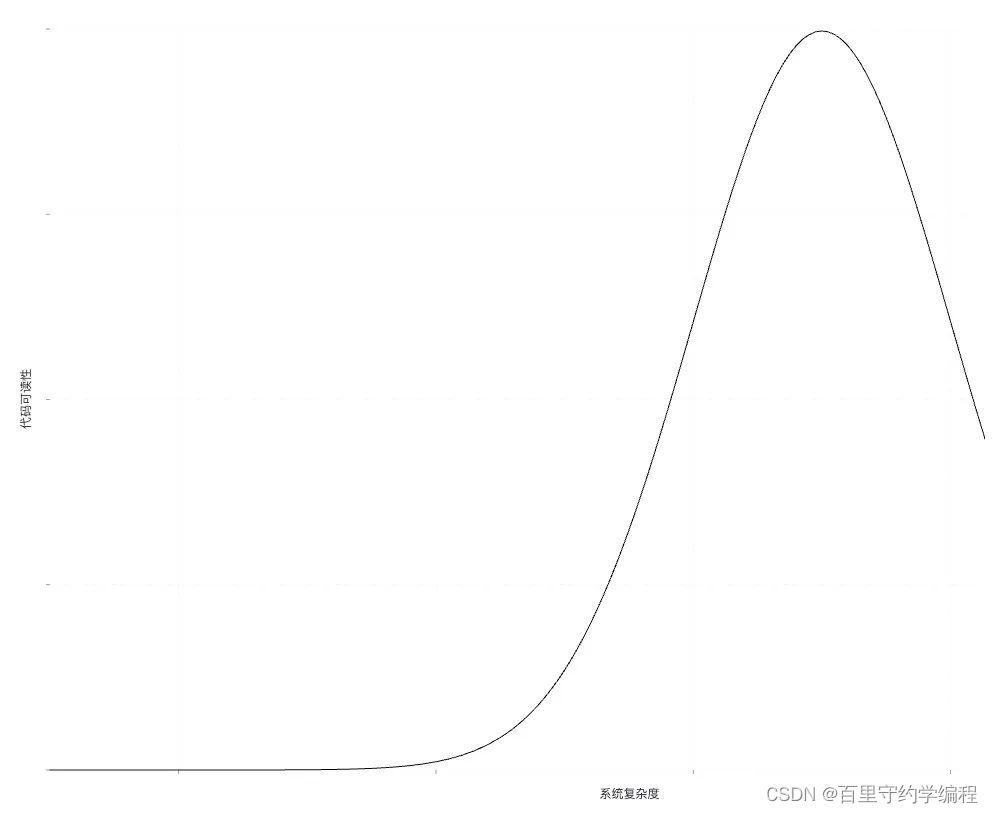
对于简单的方法,过程堆叠无伤大雅;如果一个方法的过程堆叠到了几百行,可以试试对过程基于动机和目的进行过程拆解;如果扩展频率很高,试着用依赖反转对细节进行抽象和封装。
我们对于系统代码组织的方式其实并不固定,但唯一不变的宗旨是对高可读性代码的追求。
这篇关于67.基于控制流编程,优化Go代码可读性的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



