本文主要是介绍Python爬虫:教你如何使用Python解析HAR请求文件(附源码),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

点击上方“python学习与大数据分析”关注
一、什么是HAR文件?
在Web开发和网络性能测试中,Har文件是一个非常重要的工具。Har文件是HTTP Archive的缩写,它是一个格式化的文件,包含了HTTP请求和响应的所有信息,对于我们来说,我们就可以通过解析这些请求获取到其中的请求头、请求方法、请求参数、响应内容。
二、如何获取到HAR文件?
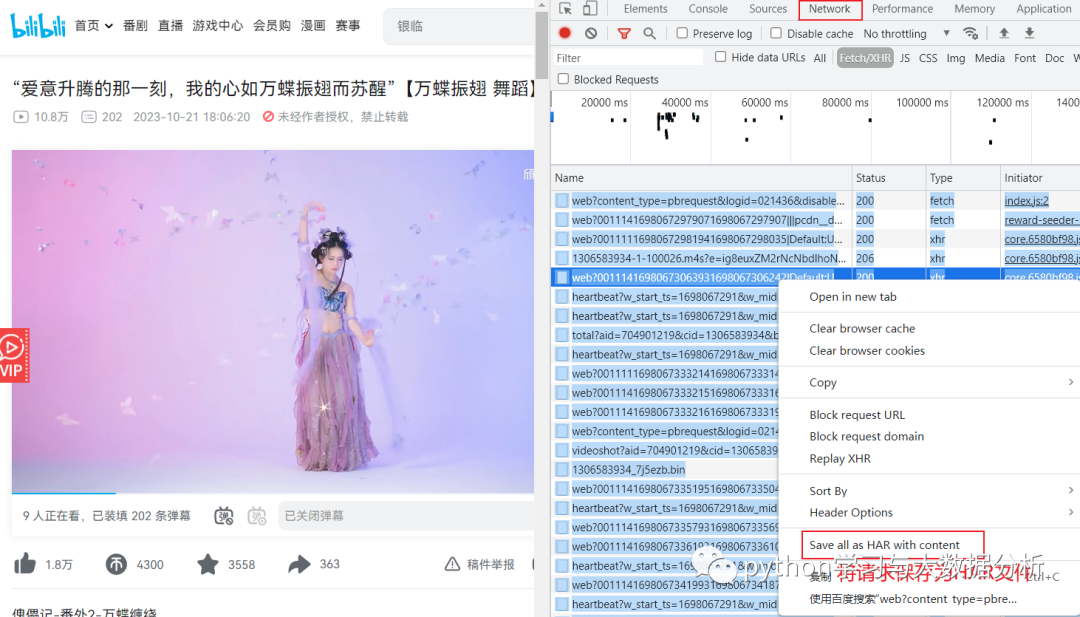
要将网络请求保存为HAR文件,您可以使用浏览器的开发者工具。以下是我笔记本自带的联想浏览器中执行此操作的步骤(其他浏览器应该也差不多):
-
打开联想浏览器并进入开发者工具。您可以通过按下F12键或右键单击页面并选择“检查”来打开开发者工具。
-
在开发者工具中,转到“Network”选项卡。
-
在页面上执行所需的网络请求。例如,您可以在页面上单击链接或提交表单。
-
在Network选项卡中,您将看到所有网络请求的列表。选择您想要保存为HAR文件的请求。
-
右键单击选定的网络请求并选择“Save all as HAR with Content”。
-
选择保存文件的位置,然后单击“保存”。
三、使用Python解析HAR文件
由于工作原因,我之前写过解释HAR文件的函数,这里直接贴出来给大家直接使用:
'''
describe:
date:2023/10/23
'''
import json# 传入
def har_analyze(harfile):print(f"开始处理HAR文件:{harfile}")try:with open(harfile, 'r', encoding='utf-8') as harfile:conent = harfile.read()if conent.startswith(u'\ufeff'):conent = conent.encode('utf8')[3:].decode('utf8')har_dict = json.loads(conent)requestList = har_dict['log']['entries']if len(requestList) == 0:msg = "HAR文件中无请求内容!"return msgtest_data_list = [['No', 'case_name', 'url', 'method', 'headers', 'req_params', 'req_data', 'req_json','assert_method', 'expect_data', 'req_var', 'resp_var', 'result']]No = 1for i in range(len(requestList)):item = requestList[i]method = item['request']['method']if method.lower() not in ['get', 'post']:continueurlString = item['request']['url']start = urlString.index('://')tempStr = urlString[start + 3:]url_start = tempStr.index('/')protocol = urlString[:start + 3]domain = tempStr[:url_start]host = protocol + domainURL = tempStr[url_start:]requst_type = item['request']['postData']['mimeType']request_data = item['request']['postData']['text']req_params,req_json,req_data = '', '', ''if request_data and requst_type:# get请求URL中已经携带参数,此处不再提取参数if method.lower() == 'post' and requst_type == 'application/json':req_json = request_dataelse:req_data = request_datanew_headers = {}headers = item['request']['headers']for j in headers:# try:# if j['name'] == 'Cookie' :# j['value'] = '${Cookie}'# if j['name'] == 'Authorization':# j['value'] = '${Authorization}'# except Exception as e:# passnew_headers[j['name']] = j['value']response = item['response']['content']['text']if not response:continuenew_list = [f'{No}', f'testcase_{No}', f'{URL}', f'{method}', f'{json.dumps(new_headers)}', f'{req_params}',f'{req_data}', f'{req_json}', 'AssertJsonTree', f'{response}', '', '', '']test_data_list.append(new_list)No +=1if len(test_data_list)>1:print(f"HAR文件解析成功,共有:{len(test_data_list)-1}个请求")return test_data_list,hostelse:print("HAR解析出来的数据为0个请求")returnexcept Exception as e:print("HAR文件解析失败")
感兴趣的小伙伴,赠送全套Python学习资料,包含面试题、简历资料等具体看下方。

一、Python所有方向的学习路线
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。


二、Python必备开发工具
工具都帮大家整理好了,安装就可直接上手!
三、最新Python学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。

四、Python视频合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

六、面试宝典


简历模板
若有侵权,请联系删除这篇关于Python爬虫:教你如何使用Python解析HAR请求文件(附源码)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



