本文主要是介绍Loguru:更为优雅、简洁的Python 日志管理模块,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

在 Python 开发中涉及到日志记录,我们或许通常会想到内置标准库 —— logging 。虽然logging 库采用的是模块化设计,可以设置不同的 handler 来进行组合,但是在配置上较为繁琐。同时在多线程或多进程的场景下,若不进行特殊处理还会导致日志记录会出现异常。
本文将介绍一个十分优雅、简洁的日志记录第三方库—— loguru ,我们可以通过导入其封装的logger 类的实例,即可直接进行调用。
安装
使用 pip 安装即可,Python 3 版本的安装如下:
pip3 install loguru
基本使用
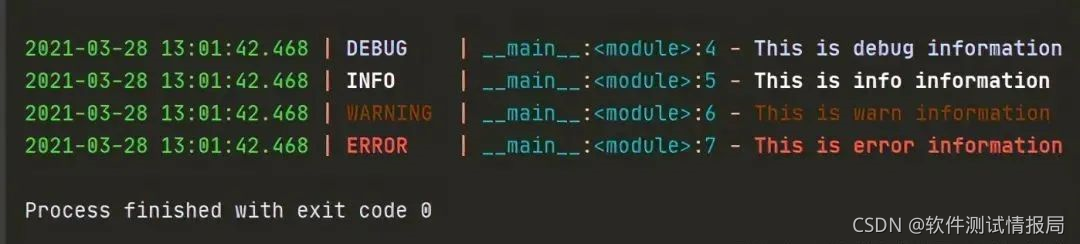
我们直接通过导入loguru 封装好的logger 类的实例化对象,不需要手动创建 logger,直接进行调用不同级别的日志输出方法。我们先用一个示例感受下:
from loguru import loggerlogger.debug('This is debug information')
logger.info('This is info information')
logger.warning('This is warn information')
logger.error('This is error information')
在 IDE 或终端运行时会发现,loguru 在输出的不同级别信息时,带上了不同的颜色,使得结果更加直观,其中也包含了时间、级别、模块名、行号以及日志信息。
loguru 中不同日志级别与日志记录方法对应关系 如下:

loguru 配置日志文件
logger 默认采用 sys.stderr 标准错误输出将日志输出到控制台中,假如想要将日志同时输出到其他的位置,比如日志文件,此时我们只需要使用一行代码即可实现。
例如,将日志信息输出到 2021-3-28.log 文件中,可以这么写:
from loguru import loggerlogger.add("E:/PythonCode/MOC/log_2021-3-28.log",rotation="500MB", encoding="utf-8", enqueue=True, retention="10 days")logger.info('This is info information')
如上,loguru直接通过 add() 方法,完成了日志文件的配置。
日志内容的字符串格式化
loguru 在输出 日志的时候,还提供了非常灵活的字符串格式化输出日志的功能,如下:
import platform
from loguru import loggerrounded_value = round(0.345, 2)trace= logger.add('2021-3-28.log')logger.info('If you are using Python {version}, prefer {feature} of course!', version=platform.python_version(), feature='f-strings')# 执行上述代码,输出结果为
2021-03-28 13:43:26.232 | INFO | __main__:<module>:9 - If you are using Python 3.7.6, prefer f-strings of course!
loguru日志常用参数配置解析
sink:可以传入一个 file 对象(file-like object),或一个 str 字符串或者 pathlib.Path 对象,或一个方法(coroutine function),或 logging 模块的 Handler(logging.Handler)。
level (int or str, optional) :应将已记录消息发送到接收器的最低严重级别。
format (str or callable, optional) :格式化模块,在发送到接收器之前,使用模板对记录的消息进行格式化。
filter (callable, str or dict, optional) :用于决定每个记录的消息是否应该发送到接收器。
colorize (bool, optional) – 是否应将格式化消息中包含的颜色标记转换为用于终端着色的Ansi代码,或以其他方式剥离。如果None,根据水槽是否为TTY自动作出选择。
serialize (bool, optional) :在发送到接收器之前,记录的消息及其记录是否应该首先转换为JSON字符串。
backtrace (bool, optional) :格式化的异常跟踪是否应该向上扩展,超出捕获点,以显示生成错误的完整堆栈跟踪。
diagnose (bool, optional) :异常跟踪是否应该显示变量值以简化调试。在生产中,这应该设置为“False”,以避免泄漏敏感数据。
enqueue (bool, optional) :要记录的消息在到达接收器之前是否应该首先通过多进程安全队列。当通过多个进程将日志记录到文件中时,这是非常有用的。这还具有使日志调用非阻塞的优点。
catch (bool, optional) :是否应该自动捕获接收器处理日志消息时发生的错误。如果True上显示异常消息 sys.stderr。但是,异常不会传播到调用者,从而防止应用程序崩溃。
如果当接收器(sink)是文件路径( pathlib.Path )时,可以应用下列参数,同时add() 会返回与所添加的接收器相关联的标识符:
rotation:分隔日志文件,何时关闭当前日志文件并启动一个新文件的条件,;例如,“500 MB”、“0.5 GB”、“1 month 2 weeks”、“10h”、“monthly”、“18:00”、“sunday”、“monday at 18:00”、“06:15”
retention (str, int, datetime.timedelta or callable, optional) ,可配置旧日志的最长保留时间,例如,“1 week, 3 days”、“2 months”
compression (str or callable, optional) :日志文件在关闭时应转换为的压缩或归档格式,例如,“gz”、“bz2”、“xz”、“lzma”、“tar”、“tar.gz”、“tar.bz2”、“tar.xz”、“zip”
delay (bool, optional):是否应该在配置了接收器之后立即创建文件,或者延迟到第一个记录的消息。默认为’ False '。
mode (str, optional) :与内置open()函数一样的打开模式。默认为’ “a”(以附加模式打开文件)。
buffering (int, optional) :内置open()函数的缓冲策略,它默认为1(行缓冲文件)。
encoding (str, optional) :文件编码与内置的’ open() ‘函数相同。如果’ None ',它默认为’locale.getpreferredencoding() 。
loguru 日志常用方式
停止日志记录到文件中
add 方法 添加 sink 之后我们也可以对其进行删除, 删除的时候根据刚刚 add 方法返回的 id 进行删除即可,还原到标准输出。如下:
from loguru import loggertrace= logger.add('2021-3-28.log')
logger.error('This is error information')logger.remove(trace)
logger.warning('This is warn information')
控制台输出如下:
2021-03-28 13:38:22.995 | ERROR | __main__:<module>:7 - This is error information2021-03-28 13:38:22.996 | WARNING | __main__:<module>:11 - This is warn information
日志文件 2021-3-28.log 内容如下:
2021-03-28 13:38:22.995 | ERROR | __main__:<module>:7 - This is error information
将 sink 对象移除之后,在这之后的内容不会再输出到日志文件中。
只输出到文本,不在console输出
通过 logger.remove(handler_id=None) 删除以前添加的处理程序,并停止向其接收器发送日志。然后通过add 添加输出日志文件,即可 实现 只输出到文本,不在console输出,如下:
from loguru import logger
# 清除之前的设置
logger.remove(handler_id=None) trace= logger.add('2021-3-28.log')logger.error('This is error information')
logger.warning('This is warn information')
filter 配置日志过滤规则
如下,我们通过实现自定义方法error_only,判断日志级别,当日志级别为ERROR,返回TRUE,我们在add方法设置filter参数时,设置为error_only,即可过滤掉ERROR以外的所有日志 。
from loguru import loggerdef error_only(record):"""error 日志 判断 Args:record: Returns: 若日志级别为ERROR, 输出TRUE"""return record["level"].name == "ERROR"# ERROR以外级别日志被过滤掉
logger.add("2021-3-28.log", filter=error_only)logger.error('This is error information')
logger.warning('This is warn information')
在 2021-3-28.log 日志中,我们可以看到仅记录了ERROR级别日志。
2021-03-28 17:01:33.267 | ERROR | __main__:<module>:11 - This is error information
format 配置日志记录格式化模板
from loguru import loggerdef format_log():"""Returns:"""trace = logger.add('2021-3-28.log', format="{time:YYYY-MM-DD HH:mm:ss} {level} From {module}.{function} : {message}")logger.warning('This is warn information')if __name__ == '__main__':format_log()如下,我们可以看到在 2021-3-28.log 日志文件中,如 “{time:YYYY-MM-DD HH:mm:ss} {level} From {module}.{function} : {message}” 格式模板进行记录:
# 2021-3-28.log
2021-03-28 14:46:25 WARNING From 2021-3-28.format_log : This is warn information
其它的格式化模板属性 如下:

通过 extra bind() 添加额外属性来为结构化日志提供更多属性信息,如下:
from loguru import loggerdef format_log():"""Returns:"""trace = logger.add('2021-3-28.log', format="{time:YYYY-MM-DD HH:mm:ss} {extra[ip]} {extra[username]} {level} From {module}.{function} : {message}")extra_logger = logger.bind(ip="192.168.0.1", username="张三")extra_logger.info('This is info information')extra_logger.bind(username="李四").error("This is error information")extra_logger.warning('This is warn information')if __name__ == '__main__':format_log()
如下,我们可以看到在 2021-3-28.log 日志文件中,看到日志按上述模板记录,如下:
2021-03-28 16:27:11 192.168.0.1 张三 INFO From 2021-3-28.format_log : This is info information
2021-03-28 16:27:11 192.168.0.1 李四 ERROR From 2021-3-28.format_log : This is error information
2021-03-28 16:27:11 192.168.0.1 张三 WARNING From 2021-3-28.format_log : This is warn information
level 配置日志最低日志级别
from loguru import loggertrace = logger.add('2021-3-29.log', level='ERROR')
rotation 配置日志滚动记录的机制
我们想周期性的创建日志文件,或者按照文件大小自动分隔日志文件,我们可以直接使用 add 方法的 rotation 参数进行配置。
例如,每 200MB 创建一个日志文件,避免每个 log 文件过大,如下:
from loguru import loggertrace = logger.add('2021-3-28.log', rotation="200 MB")
例如,每天6点 创建一个日志文件,如下:
from loguru import loggertrace = logger.add('2021-3-28.log', rotation='06:00')
例如,每隔2周创建一个 日志文件,如下:
from loguru import loggertrace = logger.add('2021-3-28.log', rotation='2 week')
retention 配置日志保留机制
通常,一些久远的日志文件,需要周期性的去清除,避免日志堆积,浪费存储空间。我们可以通过add方法的 retention 参数可以配置日志的最长保留时间。
例如,设置日志文件最长保留 7 天,如下:
from loguru import loggertrace = logger.add('2021-3-28.log', retention='7 days')
compression 配置日志压缩格式
loguru 还可以配置文件的压缩格式,比如使用 zip 文件格式保存,示例如下:
from loguru import loggertrace = logger.add('2021-3-28.log', compression='zip')
serialize 日志序列化
如果我们希望输出类似于Json-line格式的结构化日志,我们可以通过 serialize 参数,将日志信息序列化的json格式写入log 文件,最后可以将日志文件导入类似于MongoDB、ElasticSearch 中用作后续的日志分析,代码示例如下:
from loguru import logger
import platformrounded_value = round(0.345, 2)trace= logger.add('2021-3-28.log', serialize=True)logger.info('If you are using Python {version}, prefer {feature} of course!', version=platform.python_version(), feature='f-strings')
在2021-3-28.log日志文件,我们可以看到每条日志信息都被序列化后存在日志文件中,如下:
{"text": "2021-03-28 13:44:17.104 | INFO | __main__:<module>:9 - If you are using Python 3.7.6, prefer f-strings of course!\n","record": {"elapsed": {"repr": "0:00:00.010911","seconds": 0.010911},"exception": null,"extra": {"version": "3.7.6","feature": "f-strings"},"file": {"name": "2021-3-28.py","path": "F:/code/MOC/2021-3-28.py"},"function": "<module>","level": {"icon": "\u2139\ufe0f","name": "INFO","no": 20},"line": 9,"message": "If you are using Python 3.7.6, prefer f-strings of course!","module": "2021-3-28","name": "__main__","process": {"id": 22604,"name": "MainProcess"},"thread": {"id": 25696,"name": "MainThread"},"time": {"repr": "2021-03-28 13:44:17.104522+08:00","timestamp": 1616910257.104522}}
}
Traceback 记录(异常追溯)
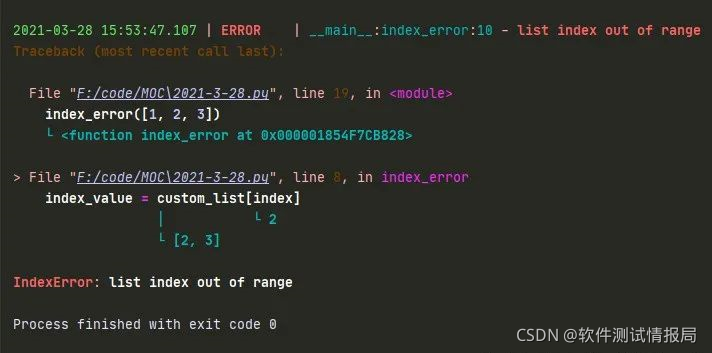
loguru集成了一个名为 better_exceptions 的库,不仅能够将异常和错误记录,并且还能对异常进行追溯,如下,我们通过在遍历列表的过程中删除列表元素,以触发IndexError 异常,
通过catch装饰器的方式实现异常捕获,代码示例如下:
from loguru import loggertrace= logger.add('2021-3-28.log')@logger.catch
def index_error(custom_list: list):for index in range(len(custom_list)):index_value = custom_list[index]if custom_list[index] < 2 :custom_list.remove(index_value)print(index_value)if __name__ == '__main__':index_error([1,2,3])运行上述代码,我们可以发现loguru输出的 Traceback 日志信息, Traceback 日志信息中同时输出了当时的变量值,如下:

在 2021-3-28.log 日志文件中也同样输出了上述格式的异常追溯信息,如下。
2021-03-28 13:57:13.852 | ERROR | __main__:<module>:16 - An error has been caught in function '<module>', process 'MainProcess' (7080), thread 'MainThread' (32280):
Traceback (most recent call last):> File "F:/code/MOC/2021-3-28.py", line 16, in <module>index_error([1,2,3])└ <function index_error at 0x000001FEB84D0EE8>File "F:/code/MOC/2021-3-28.py", line 9, in index_errorindex_value = custom_list[index]│ └ 2└ [2, 3]IndexError: list index out of range
同时,附上对类中的类方法和静态方法的代码实例,以供参考
from loguru import loggertrace = logger.add('2021-3-28.log')class Demo:@logger.catchdef index_error(self, custom_list: list):for index in range(len(custom_list)):index_value = custom_list[index]if custom_list[index] < 2:custom_list.remove(index_value)@staticmethod@logger.catchdef index_error_static(custom_list: list):for index in range(len(custom_list)):index_value = custom_list[index]if custom_list[index] < 2:custom_list.remove(index_value)if __name__ == '__main__':# Demo().index_error([1, 2, 3])Demo.index_error_static([1, 2, 3])
通过 logger.exception 方法也可以实现异常的捕获与记录:
from loguru import loggertrace = logger.add('2021-3-28.log')def index_error(custom_list: list):for index in range(len(custom_list)):try:index_value = custom_list[index]except IndexError as err:logger.exception(err)breakif custom_list[index] < 2:custom_list.remove(index_value)if __name__ == '__main__':index_error([1, 2, 3])
运行上述代码,我们可以发现loguru输出的 Traceback 日志信息, Traceback 日志信息中同时输出了当时的变量值,如下:

下面是配套资料,对于做【软件测试】的朋友来说应该是最全面最完整的备战仓库,这个仓库也陪伴我走过了最艰难的路程,希望也能帮助到你!
最后: 可以在公众号:伤心的辣条 ! 免费领取一份216页软件测试工程师面试宝典文档资料。以及相对应的视频学习教程免费分享!,其中包括了有基础知识、Linux必备、Shell、互联网程序原理、Mysql数据库、抓包工具专题、接口测试工具、测试进阶-Python编程、Web自动化测试、APP自动化测试、接口自动化测试、测试高级持续集成、测试架构开发测试框架、性能测试、安全测试等。
学习不要孤军奋战,最好是能抱团取暖,相互成就一起成长,群众效应的效果是非常强大的,大家一起学习,一起打卡,会更有学习动力,也更能坚持下去。你可以加入我们的测试技术交流扣扣群:914172719(里面有各种软件测试资源和技术讨论)
喜欢软件测试的小伙伴们,如果我的博客对你有帮助、如果你喜欢我的博客内容,请 “点赞” “评论” “收藏” 一键三连哦!
好文推荐
转行面试,跳槽面试,软件测试人员都必须知道的这几种面试技巧!
面试经:一线城市搬砖!又面软件测试岗,5000就知足了…
面试官:工作三年,还来面初级测试?恐怕你的软件测试工程师的头衔要加双引号…
什么样的人适合从事软件测试工作?
那个准点下班的人,比我先升职了…
测试岗反复跳槽,跳着跳着就跳没了…
这篇关于Loguru:更为优雅、简洁的Python 日志管理模块的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




