本文主要是介绍【计算机硬件】2、指令系统、存储系统和缓存,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 指令系统
- 计算机指令的组成
- 计算机指令执行过程
- 指令的寻址方式(怎么样找到操作数?)
- 1、顺序寻址
- 2、跳跃寻址
- 指令操作数的寻址方式(怎么样找到操作数?)
- 1、立即寻址方式
- 2、直接寻址方式
- 3、间接寻址方式
- 4、寄存器寻址方式
- 5、*基址寻址方式
- 6、*变址寻址方式
- 指令系统的类型
- 1、复杂指令系统(CISC)
- 2、精简指令系统(RISC)
- 二者对比
- 指令流水线原理
- RISC中的流水线技术
- 超流水线( Super Pipe Line) 技术
- 超标(Super Scalar) 技术
- 超长指今字( Very Long InstructionWord,VLIW) 技术(未理解)
- 流水线时间计算
- 1、流水周期
- 2、流水线执行时间
- 3、流水线吞吐率计算
- 4、流水线加速比计算
- 存储系统和缓存
- 两级存储
- 局部性原理
- 时间局部性原理
- 空间局部性原理
- Cache
- 地址映射
- 1、直接映射
- 2、全相联映射
- 3、组组相联映射
- 替换算法
- 1、 随机替换算法
- 2、先进先出算法
- 3、近期最少使用算法
- 4、优化替换算法
- 命中率
- 磁盘
- 磁盘的结构和参数
- 磁盘调度算法
- 1、先来先服务FCFS
- 2、最短寻道时间优先SSTF
- 3、扫描算法SCAN
- 4、单向扫描调度算法CSCAN
指令系统
计算机指令的组成
1、操作码——需要完成什么样的操作
2、操作数——参与运算的数据以及单元地址
以上两个都是由二进制编码存储
计算机指令执行过程
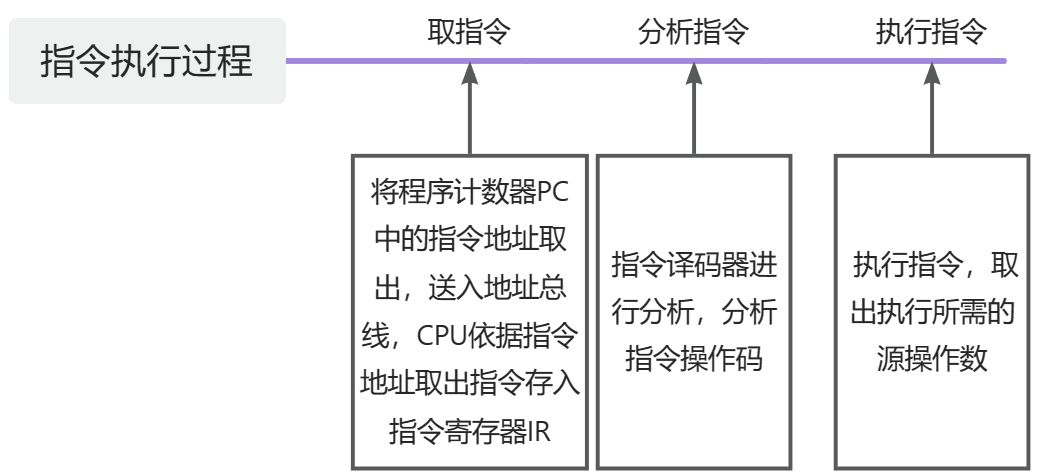
指令的寻址方式(怎么样找到操作数?)
指令组成
| 操作码字段 | 地址码字段 |
|---|
1、顺序寻址
当执行一段程序时,根据PC(程序计数器) 中指令,是一条指令接着一条指令地顺序执行
2、跳跃寻址
指下一条指令的地址码不是由程序计数器给出,而是由本条指令直接给出程 序跳跃后,按新的指令地址开始顺序执行。因此,程序计数器的内容也必须相应改变,以便及时跟 踪新的指令地址。
指令操作数的寻址方式(怎么样找到操作数?)
1、立即寻址方式
指令的地址码字段指出的不是地址,而是操作数本身
2、直接寻址方式
在指令的地址字段中直接指出操作数在主存中的地址
3、间接寻址方式
指令地址码字段所指向的存储单元中存储的是操作数的地址
4、寄存器寻址方式
指令中的地址码是寄存器的编号
5、*基址寻址方式
将基址寄存器的内容加上指令中的形式地址而形成操作数的有效地址,其优点是可以扩大寻址能力
6、*变址寻址方式
变址寻址方式将变址寄存器的内容加上指令中的形式地址而形成操作数的有效地址
指令系统的类型
1、复杂指令系统(CISC)
兼容性强,指令繁多,长度可变,微程序实现
2、精简指令系统(RISC)
兼容性弱,指令较少,主要靠硬件实现(通用寄存器、硬布线逻辑控制)
二者对比
| 指令系统类型 | 指令特点 | 寻址方式 | 实现方式 | 其他 |
|---|---|---|---|---|
| CISC(复杂) | 1、数量多 2、使用频率差别大 3、长度不固定 | 支持多种 | 微程序控制技术(微码) | 研发周期长 |
| RISC(精简) | 1、数量少 2、使用频率接近 3、定长格式 4、大部分为单周期指令 5、操作寄存器 6、只有Load/Store操作内存 | 支持方式少 | 1、增加了通用寄存器 2、硬布线逻辑控制为主 3、适合采用落水线 | 优化编译,能有效支持高级语言 |
指令流水线原理
将指令分成不同段,每段由不同的部分去处理,因此可以产生叠加的效果,所有的部件去处理指令的不同段
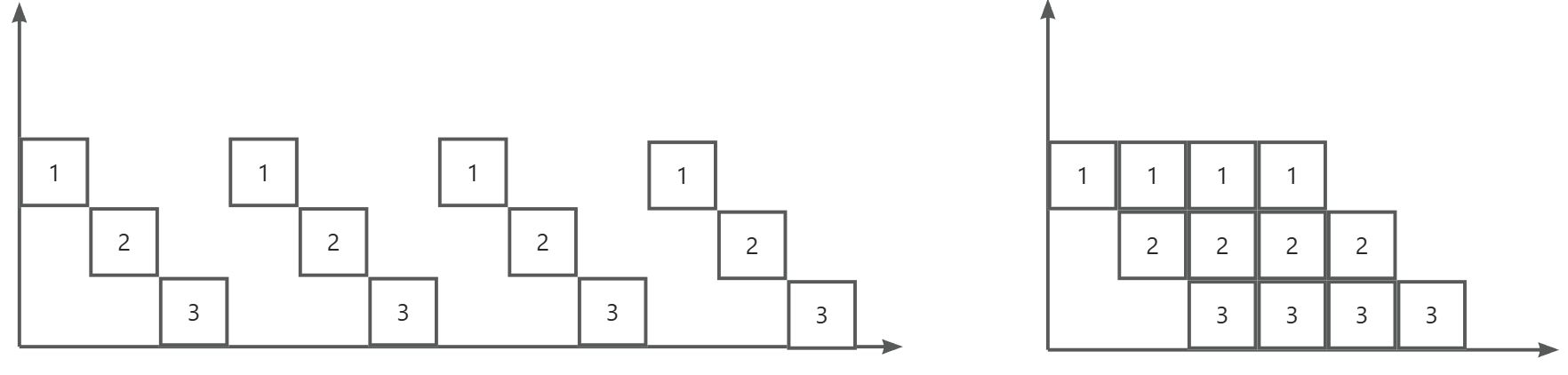
RISC中的流水线技术
超流水线( Super Pipe Line) 技术
它通过细化流水、增加级数和提高主频,使得在每个机器周期内能完成一个甚至两个浮点操作。其实质是以时间换取空间(划分成更多段数)
超标(Super Scalar) 技术
它通过内装多条流水线来同时执行多个处理,其时钟频率虽然与一般流水接近,却有更小的CPI。其实质是以空间换取时间(每一级别增加处理的部件)
超长指今字( Very Long InstructionWord,VLIW) 技术(未理解)
VLIW和超标量都是20世纪80年代出现的概念,其共同点是要同时执行多条指令,其不同在于超标量依靠硬件来实现并行处理的调度,VLIW则充分发挥软件的作用,而使硬件简化,性能提高。
流水线时间计算
1、流水周期
指令分成不同执行段,其中执行时间最长的段为流水线周期
2、流水线执行时间
流水线执行时间 = 1条指令总执行时间 + (总指令条数-1 ) * 流水线周期
3、流水线吞吐率计算
流水线吞吐率 = 指令条数 / 流水线执行时间
(吞吐率即单位时间内执行的指令条数)
4、流水线加速比计算
加速比 = 不使用流水线执行时间 /使用流水线执行时间
(加速比即使用流水线后的效率提升度,即比不使用流水线快了多少倍越高表明流水线效率越高)
注:一道题问一个流水线的最大加速比是多少的时候取最优方案然后求极限
存储系统和缓存
计算机采用分级存储体系的主要目的是为了解决存储容量 、成本和速度之间的矛盾问题(速度越快价格越高,要省钱)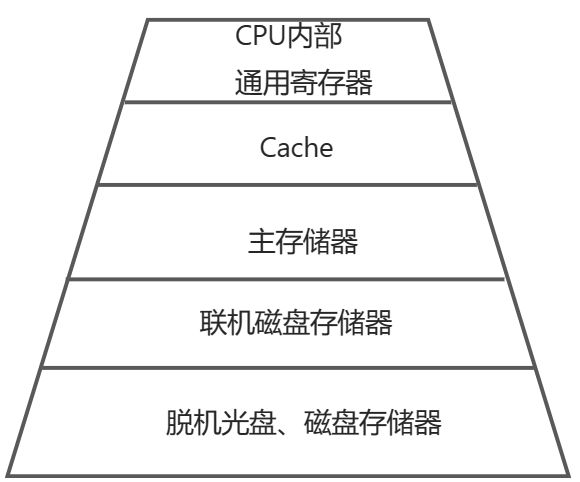
两级存储
1、Cache-主存
2、主存-辅存(虚拟存储体系)(未懂)
局部性原理
总的来说,在CPU运行时,所访问的数据会趋向于一个较小的局部空间地址内,包括下面两个方面
时间局部性原理
如果一个数据项正在被访问,那么在近期它很可能会被再次访问,即在相邻的时间里会访问同一个数据项
空间局部性原理
在最近的将来会用到的数据的地址和现在正在访问的数据地址很可能是相近的,即相邻的空间地址会被连续访问
Cache
高速缓存Cache用来存储当前最活跃的程序和数据,直接与CPU交互,位于CPU和主存之间,容量小,速度为内存的5-10倍,由半导体材料构成 。其内容 是主存内存的副本拷贝,对于程序员来说是透明的
Cache由控制部分和存储器组成,存储器存储数据,控制部分判断CPU要访问的数据是否在Cache中,在则命中,不在则依据一定的算法从主存中替换
地址映射
在CPU工作时,送出的是主存单元的地址,而应从Cache存储器中读 /写信息 。这就需要将主存地址转换为Cache存储器地址,这种地址的转换称为地址映射,由硬件自动完成映射,映射有三种形式
1、直接映射
将Cache存储器等分成块,主存也等分成块并编号 。主存中的块与Cache中的块的对应关系是固定的,也即二者块号相同才能命中 。
优点:地址变换简单
缺点:不灵活容易造成资源浪费。
2、全相联映射
同样都等分成块并编号。主存中任意一块都与Cache中任意一块对应。
优点:1、主存可以随意调入Cache任意位置
2、只有当Cache满了才会发生块冲突,是最不容易发生块冲突的映像方式
缺点:地址变换复杂,速度较慢。
3、组组相联映射
前面两种方式的结合,将Cache存储器先分块再分组,主存也同样先分块再分组,组间采用直接映像, 即主存中组号与Cache中组号相同的组才能命中,但是组内全相联映像,也即组号相同的两个组内的所有块可以任意调换
替换算法
目标:使Cache获得尽可能高的命中率
1、 随机替换算法
用随机数发生器产生一个要替换的块号将该块替换出去
2、先进先出算法
将最先进入Cache的信息块替换出去。
3、近期最少使用算法
将近期最少使用的Cache中的信息块替换出去
4、优化替换算法
这种方法必须先执行一次程序,统计Cache的替换情况。有了这样的先验信息,在第二次执行该程序时便可以用最有效的方式来替换
命中率
当CPU所访问的数据在Cache中时命中,直接从Cache中读取数据,设读取一次Cache时间为1ns,若CPU访问的数据不在Cache中,则需要从内存中读取,设读取一次内存的时间为1000ns,若在CPU多次读取数据过程中,有90%命中Cache,则CPU读取一次的平均时间为 ( 90%* 1+10%* 1000)ns(加权平均数)
磁盘
磁盘的结构和参数
磁盘有正反两个盘面,每个盘面有多个同心圆,每个同心圆是一个磁道,每个同心圆又被划分为多个扇区,数据就被存放在一个个扇区中
磁头首先要寻找到对应的磁道,然后等待磁盘进行周期旋转,旋转到指定的扇区才能读取到对应的数据,因此,会产生寻道时间和等待时间 。公式为:
存取时间 = 寻道时间+等待时间(平均定位时间+转动延迟)
(寻道时间是指磁头移动到磁道所需的时间;等待时间为等待读写的扇区转到兹头下方所用的时间)
磁盘调度算法
1、先来先服务FCFS
根据进程请求访问磁盘的先后顺序进行调度
2、最短寻道时间优先SSTF
请求访问的磁道与当前磁道最近的进程优先调度,使得每次的寻道时间最短。会产生“饥饿”现象,即远处进程可能永远无法访问
3、扫描算法SCAN
又称“电梯算法”磁头在磁盘上双向移动,其会选择离磁头当前所在磁道最近的请求访问的磁道,并且与磁头移动方向一致,磁头永远都是从里向外或者从外向里一直移动完才掉头,与电梯类似
4、单向扫描调度算法CSCAN
与SCAN不同的是,其只做单向移动,即只能从里向外或者从外向里
这篇关于【计算机硬件】2、指令系统、存储系统和缓存的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








