本文主要是介绍Kafka-消费者-KafkaConsumer分析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
与KafkaProducer不同的是,KafkaConsumer不是一个线程安全的类。
为了便于分析,我们认为下面介绍的所有操作都是在同一线程中完成的,所以不需要考虑锁的问题。
这种设计将实现多线程处理消息的逻辑转移到了调用KafkaConsumer的代码中,可以根据业务逻辑使用不同的实现方式。
例如,可以使用“线程封闭”的方式,每个业务线程拥有一个KafkaConsumer对象,这种方式实现简单、快速。
还可以使用两个线程池实现“生产者—消费者”模式,解耦消息消费和消息处理的逻辑。
其中一个线程池中每个线程拥有一个KafkaConsumer对象,负责从Kafka集群拉取消息,然后将消息放入队列中缓存,而另一个线程池中的线程负责从队列中获取消息,执行处理消息的业务逻辑。
下面开始对KafkaConsumer的分析。
KafkaConsumer实现了Consumer接口,Consumer接口中定义了KafkaConsumer对外的API,其核心方法可以分为下面六类。
- subscribe()方法:订阅指定的Topic,并为消费者自动分配分区。
- assign()方法:用户手动订阅指定的Topic,并且指定消费的分区。此方法与subscribe()方法互斥。
- commit*()方法:提交消费者已经消费完成的offset。
- seek*()方法:指定消费者起始消费的位置。
- poll()方法:负责从服务端获取消息。
- pause()、resume()方法:暂停/继续Consumer,暂停后poll方法会返回空。
了解了Consumer接口定义的功能之后,我们下面就来分析KafkaConsumer的具体实现。首先,我们需要了解KafkaConsumer中重要的字段,如图所示。
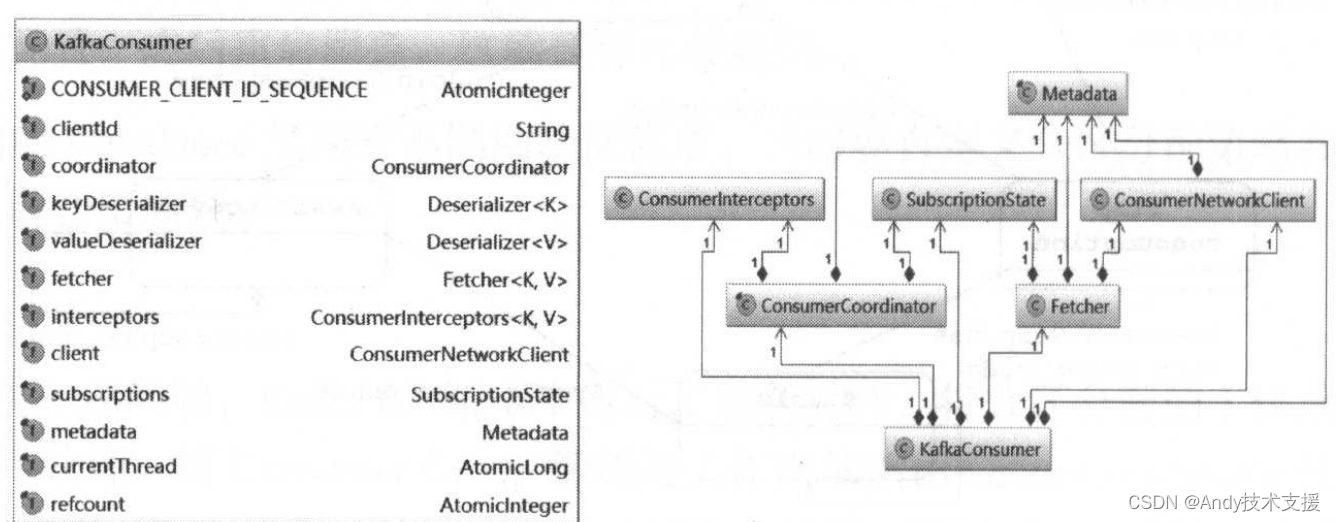
- PRODUCER_CLIENT_ID_SEQUENCE:clientld的生成器,如果没有明确指定client的Id,则使用字段生成一个ID。
- clientld:Consumer的唯一标示。
- coordinator:控制着Consumer与服务端GroupCoordinator之间的通信逻辑,可以将其理解成Consumer与服务端GroupCoordinator通信的门面。
- keyDeserializer和valueDeserializer:key反序列化器和value反序列化器。
- fetcher:负责从服务端获取消息。
- interceptors:Consumerlnterceptor集合,ConsumerInterceptor.onConsumer()方法可以在消息通过poll()方法返回给用户之前对其进行拦截或修改;ConsumerInterceptor.onCommit()方法也可以在服务端返回提交offset成功的响应时对其进行拦截或修改。
- client:负责消费者与Kafka服务端的网络通信。
- subscriptions:维护了消费者的消费状态。
- metadata:记录了整个Kafka集群的元信息。
- currentThread和refcount:分别记录了当前使用KafkaConsumer的线程Id和重入次数,KafkaConsumer的acquire()方法和release()方法实现了一个“轻量级锁”,它并非真正的锁,仅是检测是否有多线程并发操作KafkaConsumer而已。
在后面的分析过程中,我们会逐个分析KafkaConsumer依赖的组件的功能和实现。
这篇关于Kafka-消费者-KafkaConsumer分析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






