本文主要是介绍【sql/python】表中某列值以列表聚合,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
需求背景:
有一个表含有两个字段
“ID”,“VALUE”
1,香蕉
1,苹果
2,橘子
3,香蕉
3,苹果
3,橘子
目标要求:将每个ID的VALUE列聚合成一个字符串列表
“ID”,“VALUE”
1,[香蕉,苹果]
2,[橘子]
3,[香蕉,苹果,橘子]
一、SQL使用 LISTAGG函数聚合方式
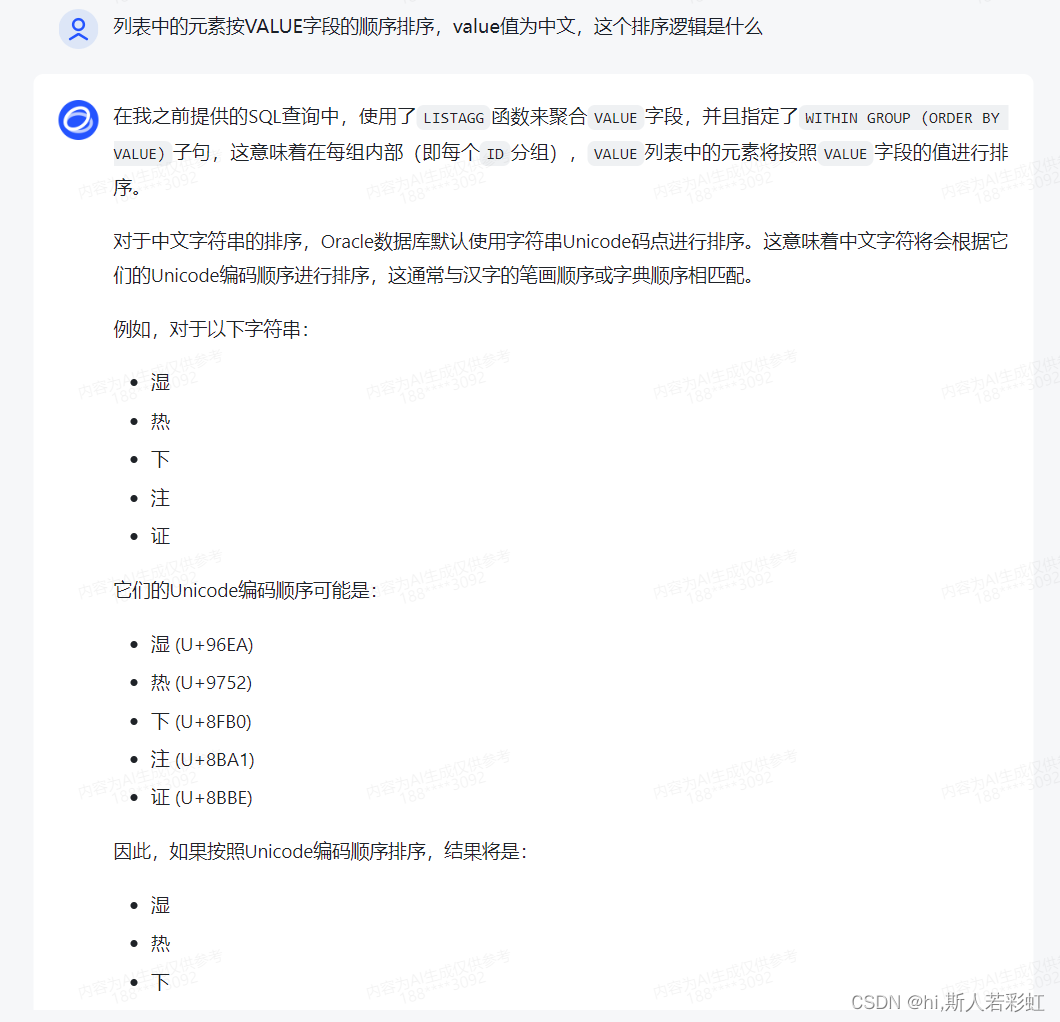
---将使用了LISTAGG函数来将每个ID的VALUE列聚合成一个字符串列表,列表中的元素按VALUE字段的顺序排序。
SELECT ID, LISTAGG(VALUE, ',') WITHIN GROUP (ORDER BY VALUE) AS VALUE_LIST
FROM XXX表名
GROUP BY ID
关于排序的逻辑,想了解的见下回答
二、python连接远程数据库的方式,结果以JSON文件存在本地
也可以在pycharm客户端使用其他工具(如Python、JSON库等)来聚合数据并生成JSON,将数据导出到外部文件,然后给出代码如下:
import cx_Oracle
# 连接到Oracle数据库
dsn = cx_Oracle.makedsn('YOUR_HOST', 'YOUR_PORT', service_name='YOUR_SERVICE_NAME')
conn = cx_Oracle.connect(user='YOUR_USERNAME', password='YOUR_PASSWORD', dsn=dsn)
# 查询SQL
query = "select {number_column}, {value_column} FROM {table_name} where rownum<=5"
# 执行查询
cursor = conn.cursor()
cursor.execute(query)# 初始化一个字典来聚合同一ID的所有VALUE
id_value_map = {}
# 遍历查询结果并填充字典
for row in cursor:# print(row)id, value = rowif id in id_value_map:id_value_map[id].append(value)#同一个ID的VALUE值追加else:id_value_map[id] = [value]# 转换为所需的JSON格式
json_data = [{"ID": k, "VALUE": v} for k, v in id_value_map.items()]
# 写入JSON文件
with open('output.json', 'w', encoding='utf-8') as json_file:json.dump(json_data, json_file, ensure_ascii=False, indent=4)
# 关闭数据库连接
cursor.close()
conn.close()
注意:表是普表,以上两种方法这么执行没有问题!但是,如果表中含有LOB类型字段(large object),即超长文本字段,方法一 二 就会报错 !!! 如果遇到“目标缓冲区太小,无法容纳字符集转换之后的 CLOB 数据”的错误,这通常意味着在执行LISTAGG函数时,生成的CLOB数据超出了数据库允许的缓冲区大小。
我们可以通过优化方法二中的部分代码来解决这个问题:
import cx_Oracle
# 连接到Oracle数据库
dsn = cx_Oracle.makedsn('YOUR_HOST', 'YOUR_PORT', service_name='YOUR_SERVICE_NAME')
conn = cx_Oracle.connect(user='YOUR_USERNAME', password='YOUR_PASSWORD', dsn=dsn)
# 查询SQL
query = "select {number_column}, {value_column} FROM {table_name} where rownum<=5"
# 执行查询
cursor = conn.cursor()
cursor.execute(query)# 初始化一个字典来聚合同一ID的所有VALUE
id_value_map = {}
# 遍历查询结果并填充字典
for row in cursor:# print(row)id, lob_value = row# 假设我们想要读取整个LOB数据if lob_value is not None:#lob_value中存在空值,如果没有不需要加这个判断#使用lob_value.read()来读取LOB对象中的全部数据lob_value_str = lob_value.read()if id in id_value_map:id_value_map[id].append(lob_value_str)else:id_value_map[id] = [lob_value_str]# 转换为所需的JSON格式
json_data = [{"ID": k, "NOTE": v} for k, v in id_value_map.items()]
# 写入JSON文件
with open('output_note_ydy.json', 'w', encoding='utf-8') as json_file:json.dump(json_data, json_file, ensure_ascii=False, indent=4)
# 关闭数据库连接
cursor.close()
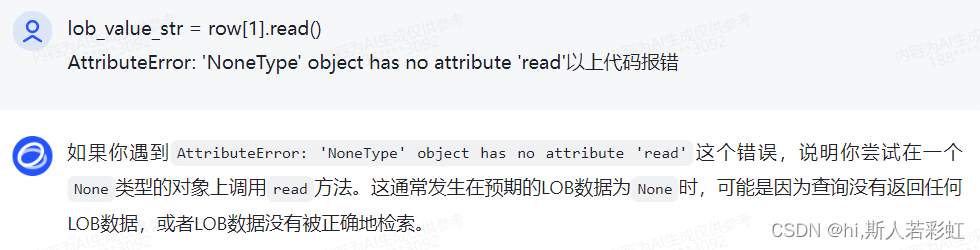
conn.close()if lob_value is not None:
因为我的表中lob_value中存在空值,所以需要加这个判断,不然就会报如下错误。
这篇关于【sql/python】表中某列值以列表聚合的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








