本文主要是介绍gunicorn日志系列2-日志格式配置,docker logs 控制台,输出接口入参,出参详细信息,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
参考:
python日志:https://docs.python.org/3/library/logging.html#logrecord-objects
supervisor + gunicorn + flask:日志服务管理
将Flask 日志整合到Gunicorn日志并输出:https://blog.csdn.net/EDS95/article/details/82598274
gunicorn部署flask的log处理:http://pythonic.zoomquiet.top/data/20190516215732/index.html
配合flask输出日志
class SimilarityRec(Resource):"""pass"""def get(self):return {'task': Todos.get('task')}def post(self):args = parser.parse_args()results = similarity_vec.simi_search(args['question'],args['top_k'],args['simi_thr'],args['business_code'],common['key_1'])app.logger.info('input:{}'.format(str(args)) + '\n' + 'output:{}'.format(str(results)))return results, 200
导出日志参考
docker logs 命令,跟踪容器的日志并且输出日志的时间
docker logs --since 50m chat-bot-client-qa &>file.txt笔记参考
docker logs -f 内部输出控制台的日志存储和大小现在,通过docker配置文件控制
docker标准输出日志存储位置,设置docker日志文件大小:https://blog.csdn.net/qq_39218530/article/details/109718891
位置
在Linux系统中docker启动后日志存储在/var/lib/docker/containers/容器ID/目录中,启动一个容器后,容器ID目录中会生成如
控制大小
新建/etc/docker/daemon.json,若有就不用新建了。添加log-dirver和log-opts参数,如下:
# vim /etc/docker/daemon.json{"registry-mirrors": ["http://f613ce8f.m.daocloud.io"],"log-driver":"json-file","log-opts": {"max-size":"500m", "max-file":"3"}
}
docker容器里面的日志输出的方式,以及日志文件大小通过python本身的logging模块handlers控制
"handlers": {"error_file": {"class": "logging.handlers.RotatingFileHandler","maxBytes": 1024 * 1024 * 50, # 打日志的大小,我这种写法是50M"backupCount": 1, # 备份多少份,经过测试,最少也要写1,不然控制不住大小"formatter": "generic", # 对应下面的键# "mode": "w+","filename": "./logs/error.log" # 打日志的路径},"error_console": {"class": "logging.StreamHandler","formatter": "generic","stream": "ext://sys.stderr"},"access_file": {"class": "logging.handlers.RotatingFileHandler","maxBytes": 1024 * 1024 * 50,"backupCount": 1,"formatter": "generic","filename": "./logs/access.log",}
linux中的&&和&,|和||
在linux中,&和&&,|和||介绍如下:
& 表示任务在后台执行,如要在后台运行redis-server,则有 redis-server &
&& 表示前一条命令执行成功时,才执行后一条命令 ,如 echo '1‘ && echo ‘2’
| 表示管道,上一条命令的输出,作为下一条命令参数,如 echo ‘yes’ | wc -l
|| 表示上一条命令执行失败后,才执行下一条命令,如 cat nofile || echo “fail”
表示任意几个字符串,其他具体的参考如下:
1. > 重定向输出符号。
2. >>重定向输出符号,但有追加的功能。
3. 2>错误重定向输出符号,覆盖原文件内容。
4. 2>>错误重定向输出符号,有文件内容追加的功能。重定向:I/O。Linux Shell 环境中支持输入输出重定向,用符号<和>来表示。0、1和2分别表示标准输入、标准输出和标准错误信息输出,可以用来指定需要重定向的标准输入或输出,比如 2>a.txt 表示将错误信息输出到文件a.txt中。
5. * 代表0个或者多个特殊字符
6. ?匹配任意一个字符。
7. | 管道符号。解释:command1|command2,将command1的输出作为command2的输入,比如ls -al|less,表示将ls -al的输出作为less的输入,即将la -al的输出分页。管道命令只接受标准输入(standoutput)。
8. & 后台进程符。
9. &&l逻辑与符号。用法:命令1 && 命令2 表示如果命令1执行成功,继续执行命令2。
10.|| 逻辑或符号。用法:命令1 | | 命令2 表示如果命令1执行成功,不执行命令2;但如果命令1执行失败才执行命令2。
&&与||,命令执行是顺序进行的,没有优先级
11.!逻辑非符号。排除指定范围。例:ls a[!0-9]
12.[x-y]表示一定的范围。
13.# 注释符;符合替换文字最短的那一个。
14.” ” 双引号表示把它所包含的内容作为普通字符,但 $ \ ‘ ‘ 几个符号除外。
15.’ ’ 单引号表示把它所包含的内容作为普通的字符,无特殊例外。
16.$ 变量符,提取变量,如echo $HOME,查看变量;正则表达式中表示行首。
17.\ 转义字符,就是将特殊字符转换成其本来的普通字符的意思。
18.``反单引号,表示它所包含的内容。一般作为嵌入的命令使用,此命令将先执行。
19.;命令分隔符。
20.< 重定向输入符。
21.()表示整体执行命令。
22.^反向选择符,例:grep -n ‘[a-zA-Z]’ wokao.txt,[]内的叫反向选择符,[]外的则表示定位在行首。查找行首不是英文字母的行。
23. . 点该表任意字符串
nohup
nohup 英文全称 no hang up(不挂起),用于在系统后台不挂断地运行命令,退出终端不会影响程序的运行。
nohup 命令,在默认情况下(非重定向时),会输出一个名叫 nohup.out 的文件到当前目录下,如果当前目录的 nohup.out 文件不可写,输出重定向到 $HOME/nohup.out 文件中。
nohup /root/runoob.sh > runoob.log 2>&1 &
2>&1 解释:
将标准错误 2 重定向到标准输出 &1 ,标准输出 &1 再被重定向输入到 runoob.log 文件中。
0 – stdin (standard input,标准输入)
1 – stdout (standard output,标准输出)
2 – stderr (standard error,标准错误输出)
python的logging
python logging 配置理解
propagate,配置启动后,日志会被打印两次
propagate 可以基于每个记录器控制该传播。 如果您不希望特定记录器传播到其父项,则可以关闭此行为。
propagete参数 :propagete=0,表示输出日志,但消息不传递;propagate=1是输出日志,同时消息往更高级别的地方传递。root为最高级别。
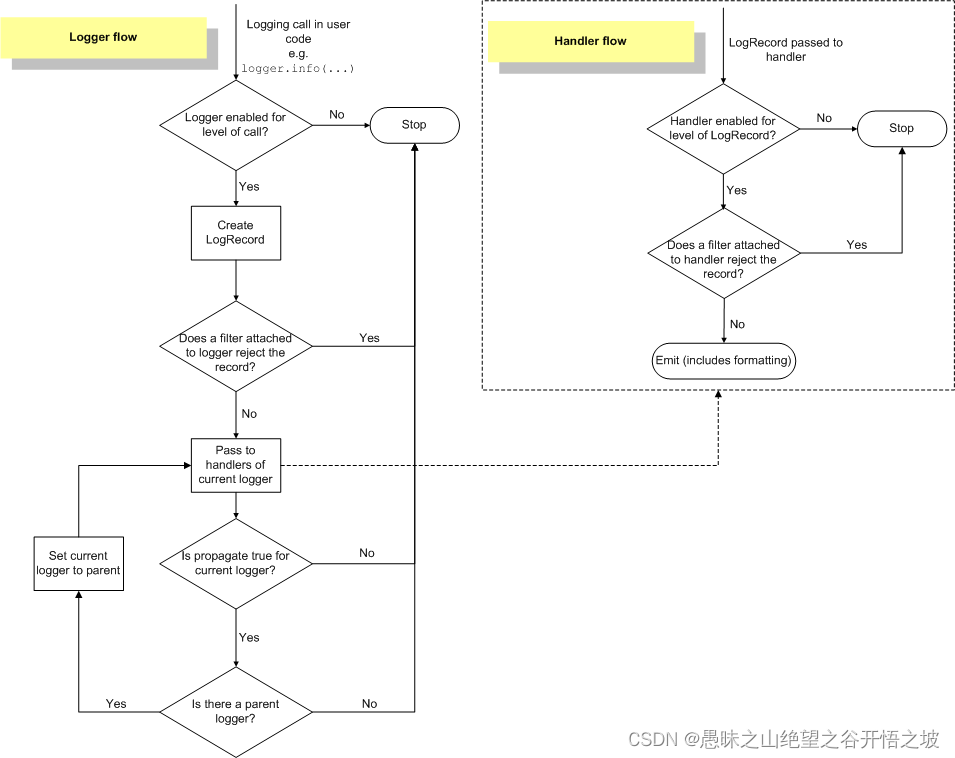
从官方文档中提供的流程图可以看出,propagate会把当前的logger设置为其parent, 并将record传入parent的Handler, 这就会导致一个有趣的现象:我们的child logger 是没有Handler的, 但是我们的record还是被发送到了终端, 这就是propagate的作用, 它把子代的所有record都发送给了父代, 循环往复, 最终到达root, 如果我们在子代中设置了hander, 那么一个record就会被发送两次:
在python中,logging由logger,handler,filter,formater四个部分组成
在python中,logging由logger,handler,filter,formater四个部分组成,logger是提供我们记录日志的方法;handler是让我们选择日志的输出地方,如:控制台,文件,邮件发送等,一个logger添加多个handler;filter是给用户提供更加细粒度的控制日志的输出内容;formater用户格式化输出日志的信息。
python中配置logging有三种方式
第一种:基础配置,logging.basicConfig(filename=“config.log”,filemode=“w”,format=“%(asctime)s-%(name)s-%(levelname)s-%(message)s”,level=logging.INFO)。
第二种:使用配置文件的方式配置logging,使用fileConfig(filename,defaults=None,disable_existing_loggers=Ture )函数来读取配置文件。
第三种:使用一个字典方式来写配置信息,然后使用dictConfig(dict,defaults=None, disable_existing_loggers=Ture )函数来瓦按成logging的配置.
文件
log_format = "[%(asctime)s][%(levelname)s]: %(message)s"fname = time.strftime(fname_ + '_%Y%m%d.log', time.localtime())level = logging.INFOlogging.basicConfig(level=level, format=log_format)# 创建RotatingFileHandler对象,满1MB为一个文件,共备份3个文件log_file_handler = RotatingFileHandler(filename=fname, maxBytes=1024 * 1024, backupCount=3)# 设置日志打印格式formatter = logging.Formatter(log_format)log_file_handler.setFormatter(formatter)self.logger.addHandler(log_file_handler)
控制台
# 创建一个StreamHandler,用于输出到控制台log_print = logging.StreamHandler()log_print.setLevel(logging.ERROR) # error级别的控制台才输出log_print.setFormatter(formatter)self.logger.addHandler(log_print)
这篇关于gunicorn日志系列2-日志格式配置,docker logs 控制台,输出接口入参,出参详细信息的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





