本文主要是介绍【小笔记】用tsai库实现Rocket家族算法,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
2024.1.16
Rocket家族算法是用于时间序列分类的强baseline(性能比较参考【小笔记】时序数据分类算法最新小结),Rocket/MiniRocket/MultiRocket官方都有开源实现,相比较而言,用tsai来实现有三个好处:1是快速跑通模型;2是更简洁优雅;3是掌握一个框架能举一反三。

1.tsai简介
项目:https://github.com/timeseriesAI/tsai

简介:
用于处理时间序列的工具库,包含TCN、Rockert等众多时间序列处理算法
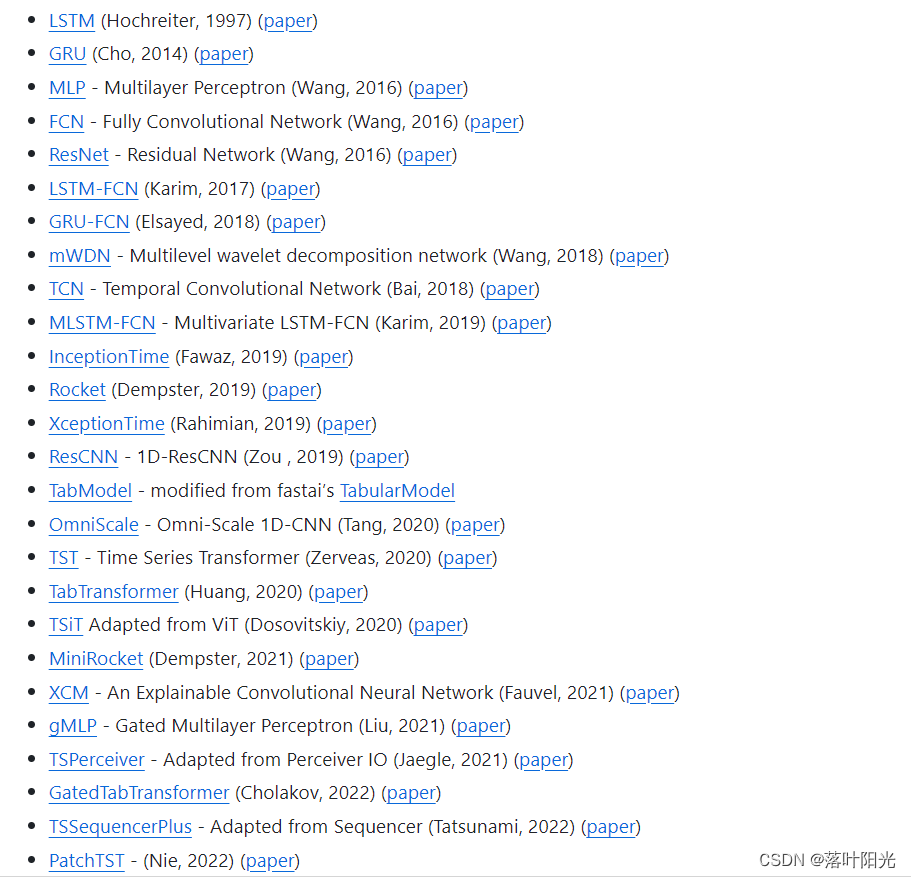
安装:
pip install tsai
2.Rocket:最优雅的实现
这个例子是基于UCR的Beef数据集,运行时,会自动下载数据集到项目的data路径下
from tsai.all import *
from sklearn.linear_model import RidgeClassifierCV
from dsets_build import get_my_dsetsdevice = 'cuda' if torch.cuda.is_available() else 'cpu'
print(device)# 加载UCR数据集
X, y, splits = get_UCR_data('Beef', return_split=False, on_disk=True, verbose=True)
tfms = [None, [Categorize()]]
batch_tfms = [TSStandardize(by_sample=True)]
dsets = TSDatasets(X, y, tfms=tfms, splits=splits)# 标准示例
dls = TSDataLoaders.from_dsets(dsets.train, dsets.valid, bs=768, drop_last=False, shuffle_train=False,device=device,batch_tfms=[TSStandardize(by_sample=True)])
model = create_model(ROCKET, dls=dls)
# model = model.to(device)print("构造特征...")
X_train, y_train = create_rocket_features(dls.train, model, verbose=False)
X_valid, y_valid = create_rocket_features(dls.valid, model, verbose=False)
print(X_train.shape, X_valid.shape)print("基于特征开始训练...")
ridge = RidgeClassifierCV(alphas=np.logspace(-8, 8, 17))
ridge.fit(X_train, y_train)
print(f'alpha: {ridge.alpha_:.2E} train: {ridge.score(X_train, y_train):.5f} valid: {ridge.score(X_valid, y_valid):.5f}')3.MiniRocket:(比Rocket更快)
待补充
4.MultiRocket:(比MiniRocket更强)
待补充
5.Hydra-MultiRocket:(Rocket家最强王者)
待补充
6.用自己的数据集训练模型
上面的例子都是用的UCR数据集,若要用自己的数据集进行训练怎么解决?
官方教程:
tsai-main\tutorial_nbs路径下的00c_Time_Series_data_preparation.ipynb
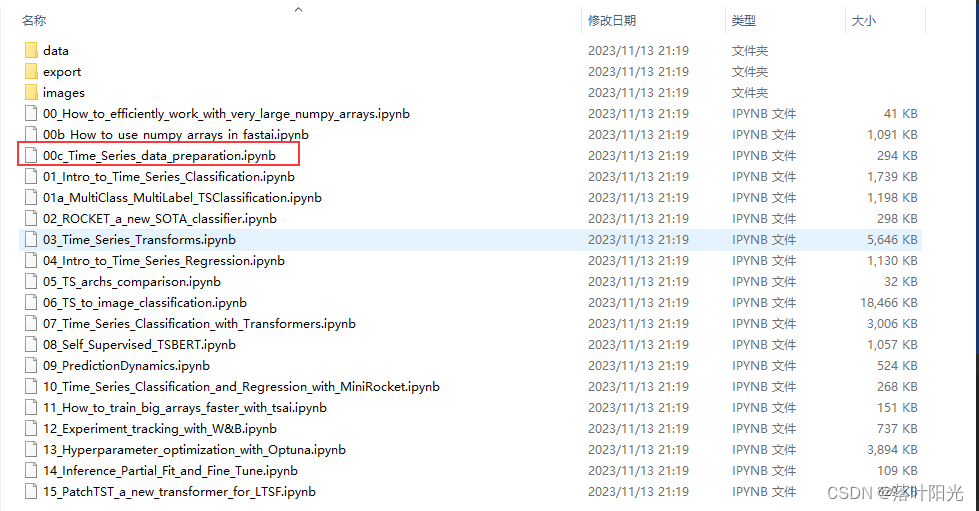
我总结了一下,基于单变量时间序列构建数据集就是下面这样:
dsets_build.py
from tsai.all import *
import numpy as np
import pandas as pddef get_my_dsets():# 导入数据集train_data, valid_data, test_data = [[], []], [[], []], [[], []]radio_train, radio_valid, radio_test = 0.6, 0.2, 0.2# !这是我的读取读取例子,读者需要进行替换----------------------------------path = "train.csc"data = pd.read_csv(path) train_data[0] = data['x'].tolist()train_data[1] = data['y'].tolist()# -----------------------------------------------------------------------# 将数据转换为np.array即可,剩下的都是通用了X_2d, y = np.array(train_data[0]), np.array(train_data[1])print(X_2d.shape, y.shape) # (4000, 4096) (4000,)splits = get_splits(y, valid_size=0.2, stratify=True, random_state=23, shuffle=True, show_plot=False)print(splits)tfms = [None, [Categorize()]]dsets = TSDatasets(X_2d, y, tfms=tfms, splits=splits, inplace=True)print(dsets)return dsets将数据集转换为tsai的dsets后,就可以直接用于训练模型了。
from tsai.all import *
from sklearn.linear_model import RidgeClassifierCV
from dsets_build import get_my_dsetsdevice = 'cuda' if torch.cuda.is_available() else 'cpu'
print(device)# 加载UCR数据集
# X, y, splits = get_UCR_data('Beef', return_split=False, on_disk=True, verbose=True)
# tfms = [None, [Categorize()]]
# batch_tfms = [TSStandardize(by_sample=True)]
# dsets = TSDatasets(X, y, tfms=tfms, splits=splits)# 加载自定义的数据集
dsets = get_my_dsets() # 和Rockert例子只有这里的区别# 标准示例
dls = TSDataLoaders.from_dsets(dsets.train, dsets.valid, bs=768, drop_last=False, shuffle_train=False,device=device,batch_tfms=[TSStandardize(by_sample=True)])
model = create_model(ROCKET, dls=dls)
# model = model.to(device)print("构造rocket特征...")
X_train, y_train = create_rocket_features(dls.train, model, verbose=False)
X_valid, y_valid = create_rocket_features(dls.valid, model, verbose=False)
print(X_train.shape, X_valid.shape)print("基于特征开始训练...")
ridge = RidgeClassifierCV(alphas=np.logspace(-8, 8, 17))
ridge.fit(X_train, y_train)
print(f'alpha: {ridge.alpha_:.2E} train: {ridge.score(X_train, y_train):.5f} valid: {ridge.score(X_valid, y_valid):.5f}')这篇关于【小笔记】用tsai库实现Rocket家族算法的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







