本文主要是介绍探索 SOFARegistry(一)|基础架构篇,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

简 介
SOFARegistry
SOFARegistry 是蚂蚁集团在生产大规模使用的服务注册中心,经历了多年大促的考验,支撑蚂蚁庞大的服务集群,具有分布式可水平扩容、容量大、推送延迟低、高可用等特点。
蚂蚁生产集群 — SOFARegistry 支撑 1000 万服务发布者、4000 万服务订阅者,在业务应用大规模变更触发千万级别推送量的场景下,推送延迟的 p99 依然能够保持在 7s 以下。
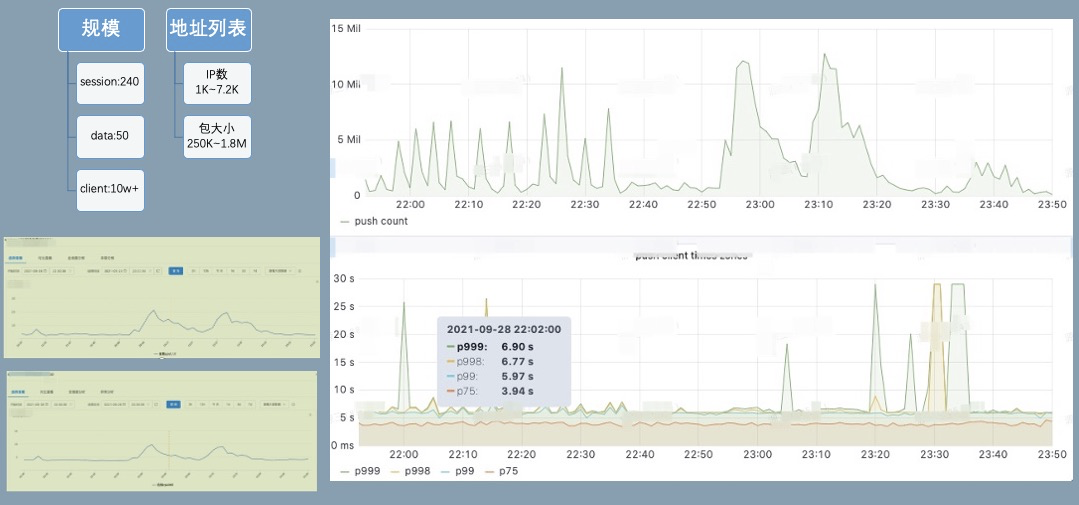
《认识 SOFARegistry》 这一系列文章将会基于 SOFARegistry 新版本 (v6) 的代码,讲解注册中心在超大规模集群场景下落地的解析与实践,同时介绍 SOFARegistry 的各项功能,方便业务落地。
#01 部署架构
SOFARegistry
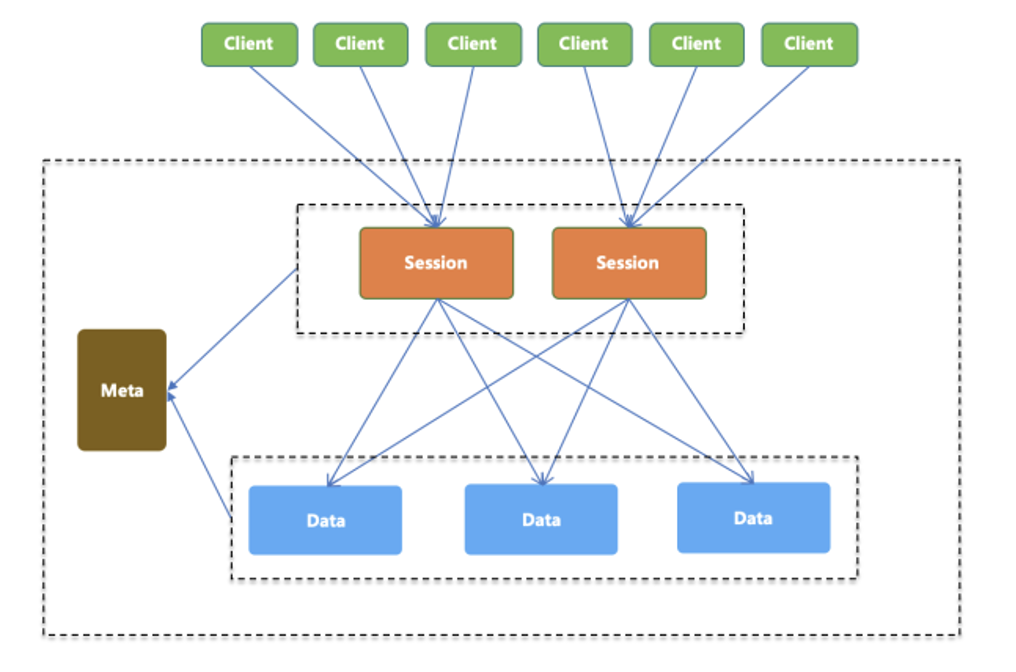
SOFARegistry 现有的架构设计:采用双层存储架构,外加一个负责内部元数据管理的 meta 组件。
SOFARegistry 的角色分为 4 个: client、session、data、meta。角色分工如下:
Client
提供应用接入服务注册中心的基本 API 能力,通过编程方式调用服务注册中心的服务订阅和服务发布能力。
SessionServer|会话服务器
负责接受 Client 的服务发布和服务订阅请求,并作为一个中间层将操作转发 DataServer 层。SessionServer 这一层可随业务机器数的规模增长而扩容。
DataServer|数据服务器
负责存储具体的服务数据,数据按 dataInfoId 进行分片存储,支持多副本备份,保证数据高可用。可随服务数据量的规模增长而扩容。
MetaServer|元数据服务器
负责维护集群 SessionServer 和 DataServer 的一致列表,作为 SOFARegistry 集群内部的地址发现服务,在 SessionServer 或 DataServer 节点变更时可以通知到整个集群。
借助双层数据分片的架构,SOFARegistry 具有了支撑海量数据的基石。
- 支持海量数据:每台 DataServer 只存储一部分的分片数据,随数据规模的增长,只要扩容 DataServer 服务器即可。
- 支持海量客户端:连接层的 SessionServer 只负责跟 Client 打交道,SessionServer 之间没有任何通信或数据复制,所以随着业务规模的增长,SessionServer 可以较轻量地扩容,不会对集群造成额外负担。
#02 数据结构
SOFARegistry
作为注册中心的基础功能,SOFARegistry 提供发布订阅的接口:Subscriber、Publisher。
在服务发现场景下,Subscriber 需要通过服务名称从注册中心订阅到多个服务方的地址,进行负载均衡的访问。
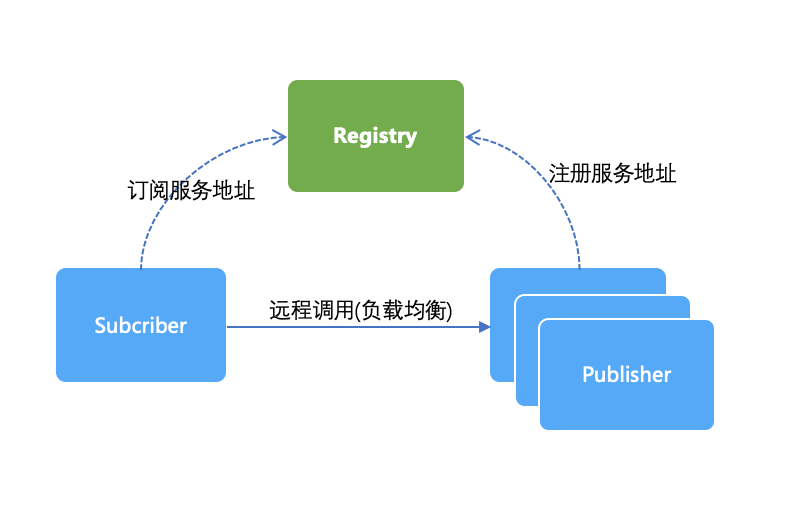
当存在服务方机器宕机时,注册中心通知所有的订阅方从服务列表中摘除这个 IP 地址,这样就不会再访问宕机的机器。

下面给出简化后的发布者和订阅者的字段,贴合上述服务发现的需求。
class Subscriber{String dataId; // 服务名称String group; // 业务类型,比如RPC、MSG等等String instanceId; // 租户名称String zone; // 所在分区,结合scope实现逻辑隔离ScopeEnum scope; // 订阅范围: zone、dataCenter、global
}class Publisher{String dataId;String group;String instanceId;String zone;List<String> dataList; // 发布的数据, sofarpc 用法中常见url
}
常见用法(JAVA SDK)
发布者
// 构造发布者注册表
PublisherRegistration registration = new PublisherRegistration("com.alipay.test.demo.service:1.0@DEFAULT");
registration.setGroup("TEST_GROUP");
registration.setAppName("TEST_APP");// 将注册表注册进客户端并发布数据
Publisher publisher = registryClient.register(registration, "10.10.1.1:12200?xx=yy");// 如需覆盖上次发布的数据可以使用发布者模型重新发布数据
publisher.republish("10.10.1.1:12200?xx=zz");订阅者
// 创建 SubscriberDataObserver
SubscriberDataObserver subscriberDataObserver = new SubscriberDataObserver() {@Overridepublic void handleData(String dataId, UserData userData) {System.out.println("receive data success, dataId: " + dataId + ", data: " + userData);}
};// 构造订阅者注册表,设置订阅维度,ScopeEnum 共有三种级别 zone, dataCenter, global
String dataId = "com.alipay.test.demo.service:1.0@DEFAULT";
SubscriberRegistration registration = new SubscriberRegistration(dataId, subscriberDataObserver);
registration.setGroup("TEST_GROUP");
registration.setAppName("TEST_APP");
registration.setScopeEnum(ScopeEnum.global);// 将注册表注册进客户端并订阅数据,订阅到的数据会以回调的方式通知 SubscriberDataObserver
Subscriber subscriber = registryClient.register(registration);更详细的用法文档参考官方文档:
https://www.sofastack.tech/projects/sofa-registry/java-sdk/#03 特点与优势
SOFARegistry
从 SOFARegistry 和其他注册中心产品的特性对比,可以看出相比其他产品,SOFARegistry 的主要优势还是在于支撑超大规模集群,目前比较贴合蚂蚁对服务注册中心容量与性能的要求。
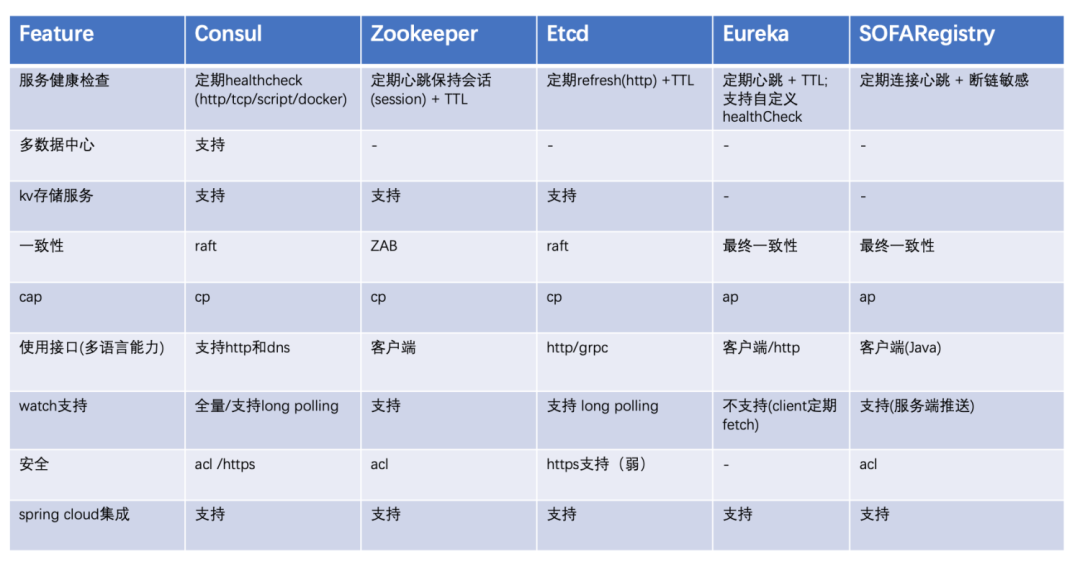
SOFARegistry 在功能特性方面还是不足(未来 SOFARegistry 在特性方面会进行完善)。
最终一致性
在服务发现场景下,强一致性并不一定是最合适的。服务发现的要求是发布方的变更能够在最快速的广播到整个集群,收敛时长确定的最终一致性同样能满足此要求。
基于 CAP 原理,在满足一致性 C 的场景下,AP 只能选择一个,但作为一个分布式高可用要求的系统,注册中心是不能舍弃 AP 的。
SOFARegistry 选择了 AP 模型,采用内存对数据进行存储,增量搭配全量的数据同步方式,使得能够满足超大规模集群服务发现的需求。
支持海量数据
部分的服务注册中心系统,每台服务器都是存储着全量的服务注册数据,服务器之间依靠一致性协议(paxos/raft)实现数据的复制,或者只保证最终一致性的异步数据复制。
“每台服务器都存储着全量的服务注册数据”,在一般规模下是没问题的。但是在蚂蚁集团庞大的业务规模下,服务注册的数据总量早就超过了单台服务器的容量瓶颈。
SOFARegistry 对数据进行了分片,每台 DataServer 只存储一部分的分片数据。随数据规模的增长,只要扩容 DataServer 服务器即可应对,这是相对其他服务发现领域的竞品来说最大的特点。
我们在线上验证了横向扩展能力,集群尝试最大扩容到 session*370、data*60、meta*3。按照一个 data 节点的安全水位支撑 200w pub,一个 pub 大概 1.5K 开销,考虑容忍 data 节点宕机 1/3 仍然有服务能力(需要保留 pub 上涨的 buffer),该集群可支撑 1.2 亿的 pub,如果配置双副本则可支撑 6kw 的 pub。
支持海量客户端
SOFARegistry 集群内部使用分层的架构,分别为连接会话层(SessionServer)和数据存储层(DataServer)。
SessionServer 功能很纯粹,只负责跟 Client 打交道,SessionServer 之间没有任何通信或数据复制,所以随着业务规模(即 Client 数量)的增长,SessionServer 可以很轻量地扩容,不会对集群造成额外负担。
高可用
各个角色都有 FailOver 机制:
- MetaServer 集群部署
内部基于数据库选举,只能存在任意运行中机器,就可以对外服务。
- DataServer 集群部署
基于自研的 Slot 分片算法进行数据分片,数据分片拥有多个副本,一个主副本和多个备副本。如果 DataServer 宕机,MetaServer 能感知,并通知所有 DataServer 和 SessionServer,MetaServer 会快速提升备副本的 DataServer 成为主副本,减少宕机影响时长。
- SessionServer 集群部署
任何一台 SessionServer 宕机时,Client 会自动 FailOver 到其他 SessionServer,并且 Client 会拿到最新的 SessionServer 列表,后续不会再连接这台宕机的 SessionServer。
秒级的服务上下线通知
对于服务的上下线变化,SOFARegistry 使用推送机制,快速地实现端到端的传达。SOFARegistry 能通过断链事件和心跳快速检测出来服务宕机的状况。
无损运维
SOFARegistry 基于内存存储和分布式的特点,自身在运维的时候势必带来数据迁移。
通过自研的 Slot 分片迁移算法和数据回放功能,使得 SOFARegistry 实现了自身运维期间依然能够对外提供服务,服务零损失。
#04 业务能力
SOFARegistry
发布订阅
发布订阅是 SOFARegistry 最基础的功能。
按 IP 下线
对于没有服务流量 goaway 和重试功能的场景下,借助注册中心实现服务流量的 zero down 运维是一个比较重要的需求。
SOFARegistry 提供 HTTP 接口进行指定 IP 的 Publisher 下线,可以在业务代码无侵入的场景下实现在一个机器下线,管控端先从注册中心下线这个 IP 对应的所有 Publisher。
应用级服务发现
SOFARegistry 内部集成了一个基于数据库的元数据中心,参考 Dubbo3 的应用级服务发现方案,实现了和 MOSN 配合的应用级服务发现方案,大幅度减少注册中心的数据量与对客户端的推送量,该特性已经在蚂蚁大规模上线,能够降低注册中心数据量一个数量级以上。
#05 数据架构
SOFARegistry
SOFARegistry 分为多个角色,多个角色之间进行数据同步实现了高可用。
Slot 分片
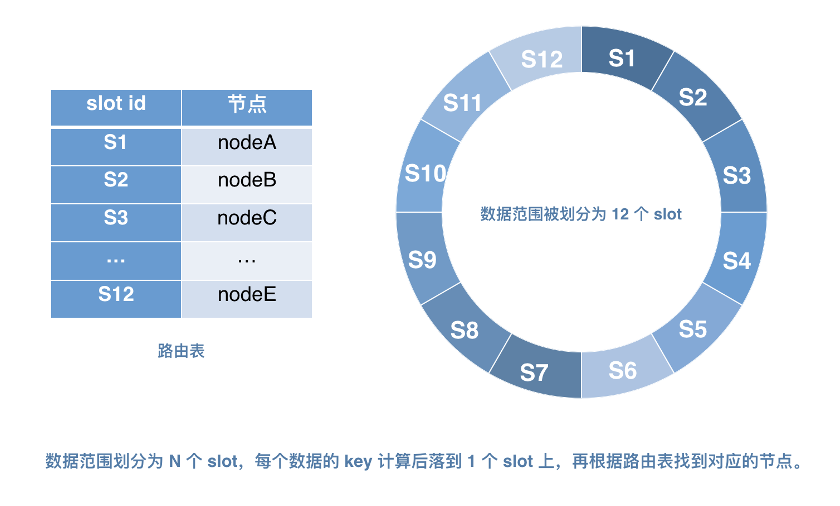
我们从逻辑上将数据范围划分成 N 个大小相等的 Slot,并且 Slot 数量后续不可再修改。然后,还需要引进“路由表”SlotTable 的概念,SlotTable 负责存放这每个节点和 N 个 Slot 的映射关系,并保证尽量把所有 Slot 均匀地分配给每个节点。
Session 在进行路由的时候,根据 DataInfoId 的 Hash 值确定数据所在 Slot,再从路由表中拿到数据对应的 Data 节点进行数据拉取,每个 Slot 都会有一个主节点和多个副本节点,从而实现主节点宕机的时候,副本节点能快速提升为主节点。
分配算法的主要逻辑是:
- 主节点和副本节点不能分配在同一个 Data 上;
- Slot 对应主节点 Data 宕机时,优先提升副本节点为主节点,减少不可服务时间;
- 新节点先作为副本节点进行数据同步;
- 主要目标在于减少节点变更时,尽可能缩短注册中心数据的不可用时长。
流程
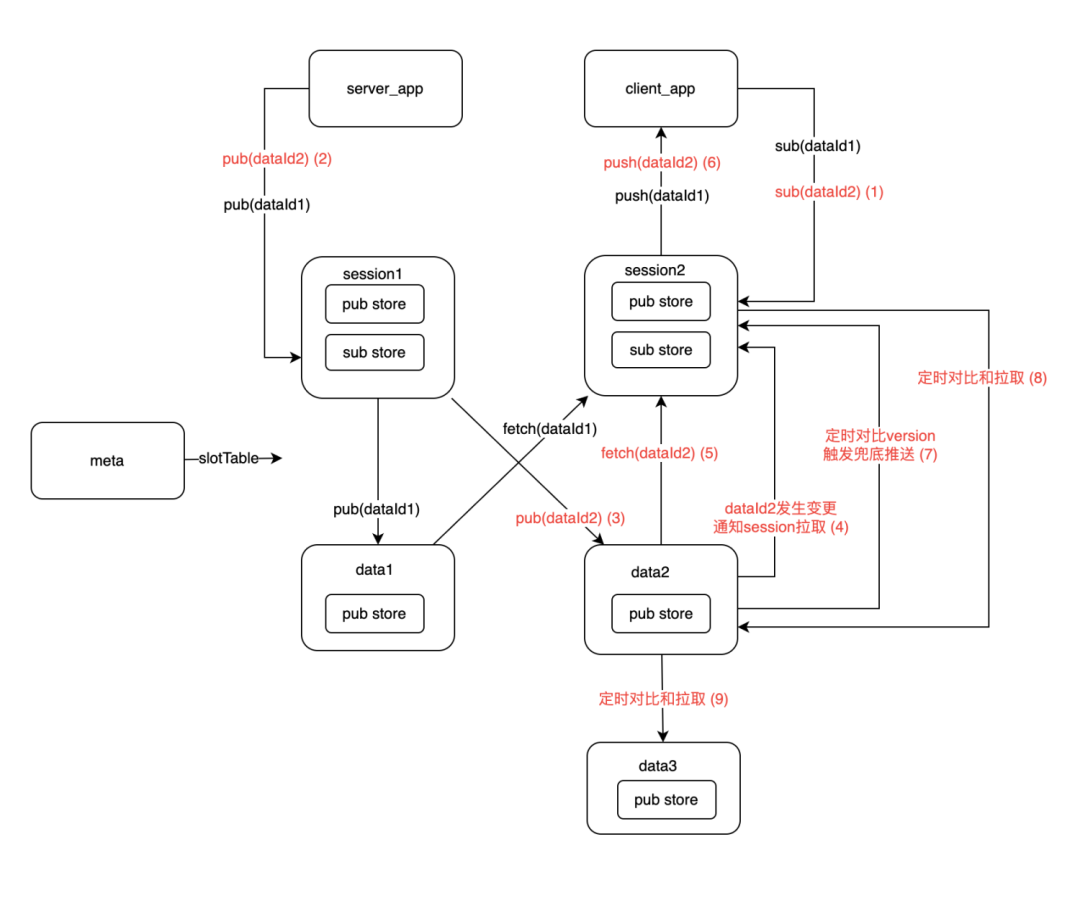
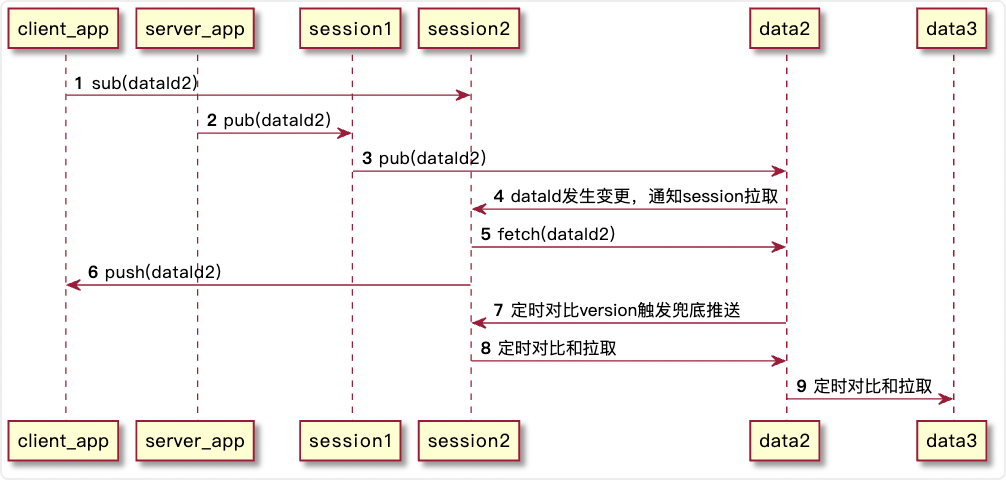
源码导航
| 1 | 接收 Subscriber | https://github.com/sofastack/sofa-registry/blob/723ddd9a8f43438793427f87814016d13b243a58/server/server/session/src/main/java/com/alipay/sofa/registry/server/session/remoting/handler/SubscriberHandler.java#L35 |
| 2 | 接收 Publisher | https://github.com/sofastack/sofa-registry/blob/723ddd9a8f43438793427f87814016d13b243a58/server/server/session/src/main/java/com/alipay/sofa/registry/server/session/remoting/handler/PublisherHandler.java#L36 |
| 3 | Data 接收 Session 的数据写入 | https://github.com/sofastack/sofa-registry/blob/723ddd9a8f43438793427f87814016d13b243a58/server/server/data/src/main/java/com/alipay/sofa/registry/server/data/remoting/sessionserver/handler/BatchPutDataHandler.java#L137 |
| 4 | Session 接收 Data 的数据变更通知 | https://github.com/sofastack/sofa-registry/blob/723ddd9a8f43438793427f87814016d13b243a58/server/server/session/src/main/java/com/alipay/sofa/registry/server/session/remoting/handler/DataChangeRequestHandler.java#L77 |
| 5 | Session 从 Data 拉取数据 | https://github.com/sofastack/sofa-registry/blob/723ddd9a8f43438793427f87814016d13b243a58/server/server/session/src/main/java/com/alipay/sofa/registry/server/session/cache/SessionCacheService.java#L87 |
| 6 | Session 推送给 Client | https://github.com/sofastack/sofa-registry/blob/723ddd9a8f43438793427f87814016d13b243a58/server/server/session/src/main/java/com/alipay/sofa/registry/server/session/push/PushProcessor.java#L337 |
| 7 | 对比 Session 推送版本和 Data 的数据版本,触发兜底推送 | https://github.com/sofastack/sofa-registry/blob/723ddd9a8f43438793427f87814016d13b243a58/server/server/session/src/main/java/com/alipay/sofa/registry/server/session/registry/SessionRegistry.java#L412 |
| 8 | Data 定时从 Session 批量拉取数据 | https://github.com/sofastack/sofa-registry/blob/723ddd9a8f43438793427f87814016d13b243a58/server/server/data/src/main/java/com/alipay/sofa/registry/server/data/slot/SlotDiffSyncer.java#L310 |
| 9 | Data Follower 定期从 Leader 批量拉取数据 | https://github.com/sofastack/sofa-registry/blob/723ddd9a8f43438793427f87814016d13b243a58/server/server/data/src/main/java/com/alipay/sofa/registry/server/data/slot/SlotDiffSyncer.java#L339 |
数据一致性
- client 对于每个 publisher 都会维护一个 version,每次 pub/unpub 都会自增,会带着 version 一起发送到 session
- session 通过 version 的判断来避免并发场景下高低版本的覆盖问题
- data 通过 version 的判断来避免并发场景下高低版本的覆盖问题
数据推送
- session 接收到 client 的数据写入时,会发送到指定的 data 上
- session 通过断链事件和心跳来检测 client 的宕机
- 当 data 内发生服务变更(比如接受到了新的 pub),data 会通知所有的 session 触发对应 dataId 推送
数据同步兜底
- session 会把 client 注册的 pub 和 sub 都存储在内存中,data 会定时和所有的 session 同步对比数据,确保数据能在短时间内达到最终一致
- session 定时对比内存中 sub 的推送完成的版本和 data 上数据的最新判断,判断是否需要触发推送
- data 包含多个 Slot,拥有 follower Slot 的 data 会定时和对应的 Slot leader 对比同步数据
本文主要介绍 SOFARegistry 自身的基础功能与优势,以及数据架构的大致介绍。
下一篇将会开始介绍如何开发 SOFARegistry 以及各个代码模块的介绍,欢迎大家继续关注 SOFARegistry ~
对中间件感兴趣的话
👏 等你加入我们!
本周推荐阅读

下一个 Kubernetes 前沿:多集群管理

降本提效!注册中心在蚂蚁集团的蜕变之路

我们做出了一个分布式注册中心

稳定性大幅度提升:SOFARegistry v6 新特性介绍

这篇关于探索 SOFARegistry(一)|基础架构篇的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









