本文主要是介绍Embedding:数据的奇妙之变,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在深度学习的领域,Embedding是连接符号与连续的一座桥梁。它通过将高维离散数据映射到低维连续向量空间,为大模型提供了更好的处理能力。
在这一部分,我们将深入研究Embedding的基本概念、作用以及在深度学习中的广泛应用。
一、向量Embedding与ChatGPT大模型
ChatGPT 大模型是 OpenAI 开发的一种基于 Transformer 架构的预训练语言模型。它在大规模语料库上进行了训练,可以实现连贯且富有逻辑的对话生成。ChatGPT 能够理解上下文,生成自然流畅的回复,并且在多轮对话中保持语境的连贯性。
而对于Embedding技术,那么,什么是向量Embedding?简单地说,向量Embedding是可以表示许多类型数据的数字列表。
向量Embedding非常灵活,包括音频、视频、文本和图像都可以表示为向量Embedding。

简单来说,苹果,香蕉,橘子这样的数据,是不可能直接进入到神经网络的模型,需要转化为神经网络可以接受的形式。最开始的时候,我们使用的是One-hot编码格式,one-hot编码的原理举一个简单的例子:
考虑书籍类型:“小说”、“非小说”和“传记”。每一种体裁都可以编码成一个热向量,然而,这样的向量会非常稀疏,因为书籍通常只属于两个体裁。
下图显示了这种编码是如何工作的。注意这里0的数量是1的两倍。对于像图书类型这样的类别,随着更多的类型被添加到数据集中,这种稀疏性将会呈指数级恶化。
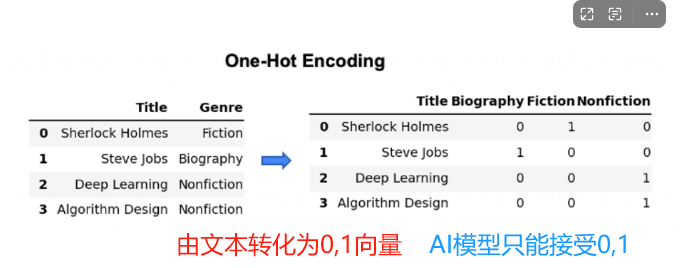
稀疏性会给机器学习模型带来挑战。对于每一种新的类型,编码表示的大小都会增长,因此数据集的计算成本会变得很高。
对于图书类型,或者任何具有相对较少类别的分类数据,我们可以使用简单的one-hot编码,但是,对于整个英语语言呢?对于这种规模的语料库,这种编码方法将变得不切实际。因此就进入我们的主题——向量Embedding
Embedding 在 ChatGPT 中的应用:
在 ChatGPT 中,Embedding 起到了将输入文本转换为向量表示的作用。当用户输入一段文本时,ChatGPT 首先会使用Embedding嵌入层将文本中的词语转换为对应的向量表示,然后输入这些向量表示到模型中进行处理。这样做有助于模型更好地理解语义和上下文,从而生成合理的回复。
二、向量Embedding的优势与原理
向量Embedding呈现固定大小的表示,不随数据中观测值的数量而增长。由模型创建的结果向量,通常是384个浮点值,比其他编码方法(如one-hot编码)的表示密度要高得多。这意味着在更少的字节中存在更多的信息,因此在计算上的利用成本更低。以下是一个Embedding的编码示意原理图。
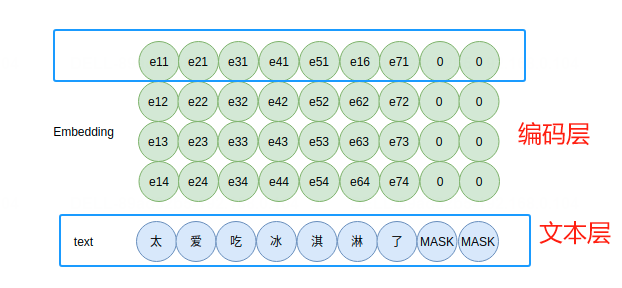
对于每一个字(实则是字ID)输入到Embedding组件中,输出一个表示该字的向量,如上图,“太”字对应的ID输入,输出为向量[e11,e12,e13,e14]。这个字(词)向量的每一维可以当做是隐含的主题,只不过这些主题并没有明显的现实语义。这就是Embedding的文本编码原理。
三、向量Embedding的实践应用
存在大量的预训练模型,可以很容易地用于创建向量Embedding。Huggingface Model Hub (https://huggingface.co/models)包含许多模型,可以为不同类型的数据创建Embedding。
例如,all-MiniLM-L6-v2模型是在线托管和运行的,不需要专业知识或安装。
像sentence_transformers这样的包,也来自HuggingFace,为语义相似度搜索、视觉搜索等任务提供了易于使用的模型。要使用这些模型创建Embeddings,只需要几行Python代码:
- 安装 sentence_transformers 编码包
!pip install sentence_transformers- 执行编码
在我们的查询向量和上图中的其他三个向量之间运行这个计算,我们可以确定句子之间的相似程度。
- 测试语义搜索的空间向量的判断
import numpy as np
from numpy.linalg import norm
from sentence_transformers import SentenceTransformer# Define the model we want to use (it'll download itself)
model = SentenceTransformer('sentence-transformers/all-MiniLM-L6-v2')
sentences = ["a very happy person","a happy dog","a sunny day"
]
embeddings = model.encode(sentences)
# query vector embedding
query_embedding = model.encode("a happy person")
# define our distance metric
def cosine_similarity(a, b):return np.dot(a, b)/(norm(a)*norm(b))
# run semantic similarity search
print("Query: a happy person\n")
for e, s in zip(embeddings, sentences):print(s, " -> similarity score = ",cosine_similarity(e, query_embedding))
四、Embedding在大模型中的价值
说到Embedding在大模型中的价值,不如我们先说说目前大模型还存在哪些问题?尽管目前GPT-4或者ChatGPT的能力已经很强大,但是目前它依然有很大的缺陷:
- 知识不足或信息丢失
- 训练数据是基于2021年9月之前的数据,缺少最新的数据
- 无法访问私有的文档
- 基于历史会话中获取信息
- 对输入的内容长度有限制
因此,OpenAI发布了这样一篇文档,说明如何使用两步搜索回答来增强GPT的能力:
- 搜索:搜索您的文本库以查找相关的文本部分。
- 请求:将检索到的文本部分插入到发送给GPT的消息中,并向其提出问题。
GPT可以通过两种方式学习知识:
- 通过模型权重(即在训练集上微调模型)
- 通过模型输入(即将知识插入到输入消息中)
尽管微调可能感觉更自然——毕竟,通过数据训练是GPT学习所有其他知识的方式——但OpenAI通常不建议将其作为教授模型知识的方式。微调更适合于教授专业任务或风格,对于事实回忆来说则不太可靠。
测试代码demo:
https://github.com/openai/openai-cookbook/blob/main/examples/Question_answering_using_embeddings.ipynb
此外,可以在大量文本数据上预训练Embedding,然后在小型数据集上进行微调,这有助于提高语言模型在各种自然语言处理应用程序中的准确性和效率。
五、Embedding让大模型解决长文本的输入
这里我们给一个案例来说明如何用Embedding来让ChatGPT回答超长文本中的问题。
如前所述,大多数大语言模型都无法处理过长的文本。除非是GPT-4-32K,否则大多数模型如ChatGPT的输入都很有限。假设此时你有一个很长的PDF,那么,你该如何让大模型“读懂”这个PDF呢?
首先,你可以基于这个PDF来创建向量embedding,并在数据库中存储(当前已经有一些很不错的向量数据库了,如Pinecone)。
接下来,假设你想问个问题“这个文档中关于xxx是如何讨论的?”。那么,此时你有2个向量embedding了,一个是你的问题embedding,一个是之前PDF的embedding。此时,你应该基于你的问题embedding,去向量数据库中搜索PDF中与问题embedding最相似的embedding。然后,把你的问题embedding和检索的得到的最相似的embedding一起给ChatGPT,然后让ChatGPT来回答。
当然,你也可以针对问题和检索得到的embedding做一些提示工程,来优化ChatGPT的回答。
六、Embedding技术的未来发展
模型的细粒度和多模态性:例如,字符级(Char-level)的嵌入、语义级的嵌入,以及结合图像、声音等多模态信息的嵌入。
更好的理解和利用上下文信息:例如,动态的、可变长度的上下文,以及更复杂的上下文结构。
模型的可解释性和可控制性:这包括模型的内部结构和嵌入空间的理解,以及对模型生成结果的更精细控制。
更大规模的模型和数据:例如,GPT-4、GPT-5等更大规模的预训练模型,以及利用全球范围的互联网文本数据。
这篇关于Embedding:数据的奇妙之变的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




