本文主要是介绍半监督学习 - 三元组学习(Triplet Learning),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
什么是机器学习
三元组学习(Triplet Learning)是半监督学习中一种用于学习有用表示的方法。它通常用于学习数据中的相似性关系,尤其在人脸识别、图像检索等领域中得到广泛应用。三元组学习是通过构造三元组(triplet)来训练模型,每个三元组包含一个锚点样本(anchor sample)、一个正样本(positive sample)和一个负样本(negative sample)。
三元组的构造
- 锚点样本(Anchor Sample): 是模型当前预测效果的样本。
- 正样本(Positive Sample): 与锚点样本相似的样本,即与锚点样本属于同一类别的样本。
- 负样本(Negative Sample): 与锚点样本不相似的样本,即与锚点样本属于不同类别的样本。
训练目标
通过构建这样的三元组并设计一个适当的损失函数,目标是使锚点样本与正样本的相似性大于与负样本的相似性。这样的训练过程使得模型更好地捕捉数据中的相似性关系。
三元组损失函数
通常使用的三元组损失函数是 margin-based(基于间隔的)形式,其中间隔是指锚点样本与负样本之间的距离减去锚点样本与正样本之间的距离。如果这个间隔小于某个预定的阈值(margin),则损失较小;否则,损失较大。
具体而言,三元组损失可以表示为:
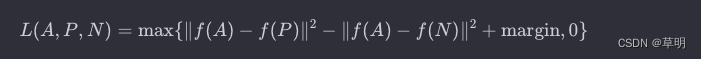
其中:
f(⋅)表示模型的嵌入函数∥⋅∥表示欧氏距离
优点和注意事项
- 学习相似性关系: 三元组学习可以帮助模型学习数据中的相似性关系,这对于任务如人脸识别、图像检索等非常有用。
- 选择合适的负样本: 选择合适的负样本对于三元组学习的效果至关重要,负样本应该足够接近锚点样本,但又不能太相似。
- 样本不平衡: 在实践中,样本的类别分布可能不平衡,因此需要谨慎设计损失函数和选择三元组以防止样本的类别不平衡导致的问题。
三元组学习是一种有效的半监督学习方法,特别适用于学习数据中的相似性关系。
这篇关于半监督学习 - 三元组学习(Triplet Learning)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








