本文主要是介绍【python爬取中央气象台每日预报结果】 selenium=4.12.0,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
爬取中央气象台每日预报结果
目录
- 爬取中央气象台每日预报结果
- 1、数据网站介绍
- 2、python爬取代码 - 有界面
- 3、python爬取代码 - 无界面headless
- 4、执行结果
1、数据网站介绍
中央气象台网站提供了1-7天的各要素预报信息(这里以降水信息为例)。该网站通过气象观测数据和数值模型分析,提供了全国范围内各地区未来几天的降水情况预报。用户可以通过该网站获取准确的降水预报,以便做出相应的气象决策和安排。无论是个人还是专业人士,都可以在中央气象台网站上获取可靠的降水预报信息,以帮助其日常生活或工作中的气象需求。
2、python爬取代码 - 有界面
- 使用的selenium版本为4.12.0,selenium4之前的版本,方法名称有所更改,无法使用当前代码执行
- selenium4之前的版本参考博文【python爬取中央气象台每日预报结果】 selenium=3.141.0
"""
selenium==4.12.0
"""
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
import urllib# 创建浏览器操作对象
s = Service(r"D://Downloads//chromedriver-win64-117.0.5938.88//chromedriver.exe")
browser = webdriver.Chrome(service=s)# 打开网站
browser.get('http://www.nmc.cn/publish/precipitation/1-7day-precipitation.html')
day_str = ['24小时', '48小时', '72小时', '96小时', '120小时', '144小时', '168小时']
for day in day_str:browser.find_element(By.LINK_TEXT, value=day).click()imgpath = browser.find_element(By.XPATH, '//*[@id="imgpath"]')imgsrc = imgpath.get_attribute('src')full_name = imgsrc.split('/', -1)[-1].split('_')[-1].split('?')[0]img_name = full_name[:8] + "-" + full_name[12:15] + full_name[-4:]# 下载图片urllib.request.urlretrieve(url=imgsrc, filename='./中央气象台/'+img_name)print("{}下载完成".format(img_name))
3、python爬取代码 - 无界面headless
"""
selenium==4.12.0
"""
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
import urllib# 创建浏览器操作对象
s = Service(r"D://Downloads//chromedriver-win64-117.0.5938.88//chromedriver.exe")# 设置无界面打开浏览器 后台运行 无浏览器模式 注释则是浏览器模式
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')# 创建浏览器对象
browser = webdriver.Chrome(service=s, options=chrome_options)# 打开网站
browser.get('http://www.nmc.cn/publish/precipitation/1-7day-precipitation.html')
day_str = ['24小时', '48小时', '72小时', '96小时', '120小时', '144小时', '168小时']
for day in day_str:browser.find_element(By.LINK_TEXT, value=day).click()imgpath = browser.find_element(By.XPATH, '//*[@id="imgpath"]')imgsrc = imgpath.get_attribute('src')full_name = imgsrc.split('/', -1)[-1].split('_')[-1].split('?')[0]img_name = full_name[:8] + "-" + full_name[12:15] + full_name[-4:]# 下载图片urllib.request.urlretrieve(url=imgsrc, filename=img_name)print("{}下载完成".format(img_name))
4、执行结果
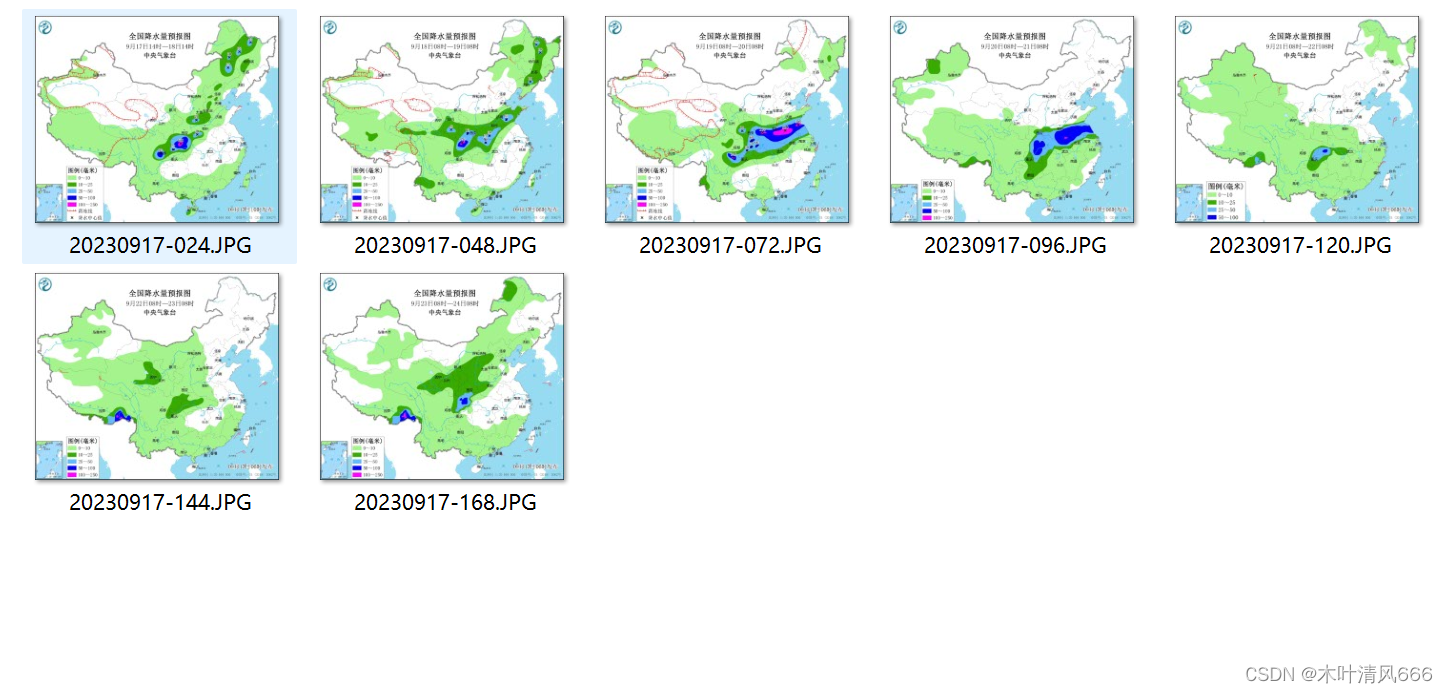
这篇关于【python爬取中央气象台每日预报结果】 selenium=4.12.0的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








