本文主要是介绍【Kafka】Kafka 1.0.1案例详解之Kafka Streams,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在这之前我们已经讲解了Kafka的安装部署和最核心的发布订阅功能,本次章节我们来介绍Kafka的新特性——Kafka Streams。
首先,要研究一样新东西,我们需要知道它是做什么的:
Kafka Streams is a client library for processing and analyzing data stored in Kafka. It builds upon important stream processing concepts such as properly distinguishing between event time and processing time, windowing support, and simple yet efficient management and real-time querying of application state.
大家仔细阅读上面一段话可以知道,Kafka Streams是一个用来处理Kafka消息的库,它包含了如下几个优势:
通过与现有的Java应用整合,我们可以设计出简单的、轻量级的客户端类库
只需要基于Kafka自身的消息系统,不需要额外的第三方系统,就可以很容易地实现水平扩展
通过可容错的状态管理,实现高效的窗口操作和聚合
支持 exactly-once语义
既支持基于时间窗口的操作,也支持每次单条数据的处理
既支持低阶的流处理接口,也支持高阶的流处理DSL(领域专用语言)
Kafka Streams处理剖析图
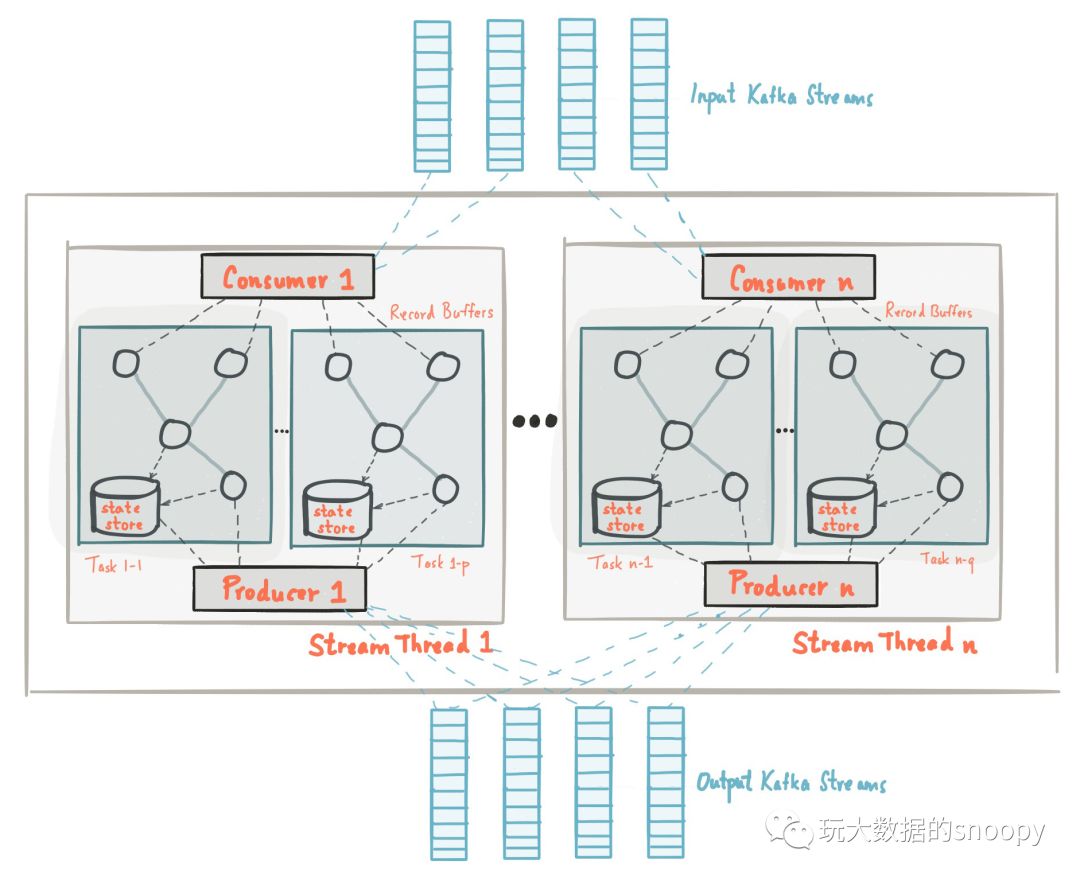
案例剖析
说了这么多理论知识,实际上用起来很简单,接下来我们通过一个简单的例子来熟悉这个新特性。
添加依赖
kafka-streams是一个单独的依赖包,并不存在于kafka-client中
<dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-streams</artifactId><version>1.0.1</version>
</dependency>属性配置
添加属性配置,application id相当于group id,bootstrap servers配置kafka的brokers地址,并配置key与value的序列化、反序列化实现类。这两个类均实现了
org.apache.kafka.common.serialization.Serde接口
Properties props = new Properties();
props.put(StreamsConfig.APPLICATION_ID_CONFIG, "streams-pipe");
props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());读取并处理输出
最后通过StreamsBuilder来创建KStream,进行数据处理转换后输出到一个新的topic或者其他外部存储器中。
builder.stream("streams-plaintext-input").to("streams-pipe-output");
final Topology topology = builder.build();
final KafkaStreams streams = new KafkaStreams(topology, props);退出机制
最后添加退出时的处理逻辑
// attach shutdown handler to catch control-c
Runtime.getRuntime().addShutdownHook(new Thread("streams-shutdown-hook") {@Overridepublic void run() {streams.close();latch.countDown();}
});我们可以在github中查看完整的程序代码:
https://github.com/lubinsu/new-kafka

生活
岂止于美

作者:苏鹭彬
长按二维码关注
这篇关于【Kafka】Kafka 1.0.1案例详解之Kafka Streams的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






