本文主要是介绍跟踪指标预测代码(track eval),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
提示:本文将修改官网跟踪预测指标,以mot17为数据基准,构建一个简单使用的代码,可实现HOTA, MOTA, IDF1等指标预测。
代码链接:https://github.com/tangjunjun966/trackereval
文章目录
- 前言
- 代码模块
- 认识gt与predect数据格式
- 认识gt数据格式
- 认识predect数据格式
- 文件结构
- gt文件夹
- predect文件夹
- 运行参数解释
- 重点参数说明
- 自定义参数
- 运行命令
- 可视化工具
- 测试结果
前言
官方已有跟踪指标预测代码库,然代码整体较为复杂,不易读者上手使用。我将以官网代码作为基准,对代码进行了修改与解读,并以此文作为记录。主要贡献如下:
① 去除不必要脚本,给出简单上手代码;
②可将本仓库代码集成跟踪模型中,本人也是集成其它跟踪模型作为指标测试;
③本文将详细给出参数含义和使用方法,帮助读者直接理解与上手;
提示:以下是本篇文章正文内容,下面案例可供参考
代码模块
代码构成模块为:
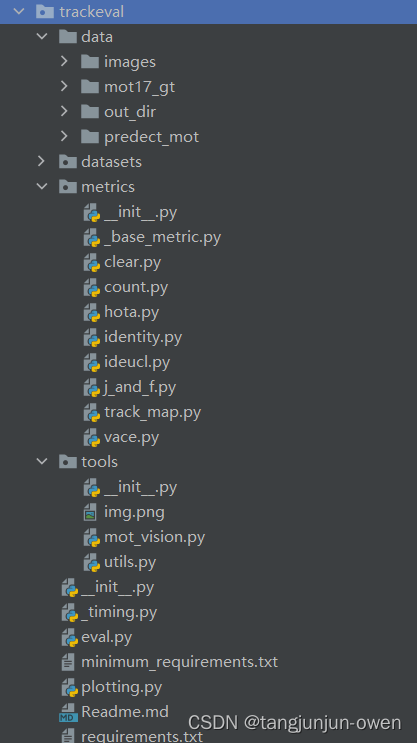
data:存放demo数据格式,以供读者直接运行,生成结果
datasets:处理数据相关代码
metrics:计算指标相关代码
tools:独立于仓库代码,用于可视化mot数据集工具代码
其代码库具体格式如下:
认识gt与predect数据格式
本仓库代码是以mot17为基准修改。gt.txt使用mot17的gt.txt格式,若想测试其它数据库文件,可先转换为gt.txt格式,方可使用此仓库代码。
认识gt数据格式
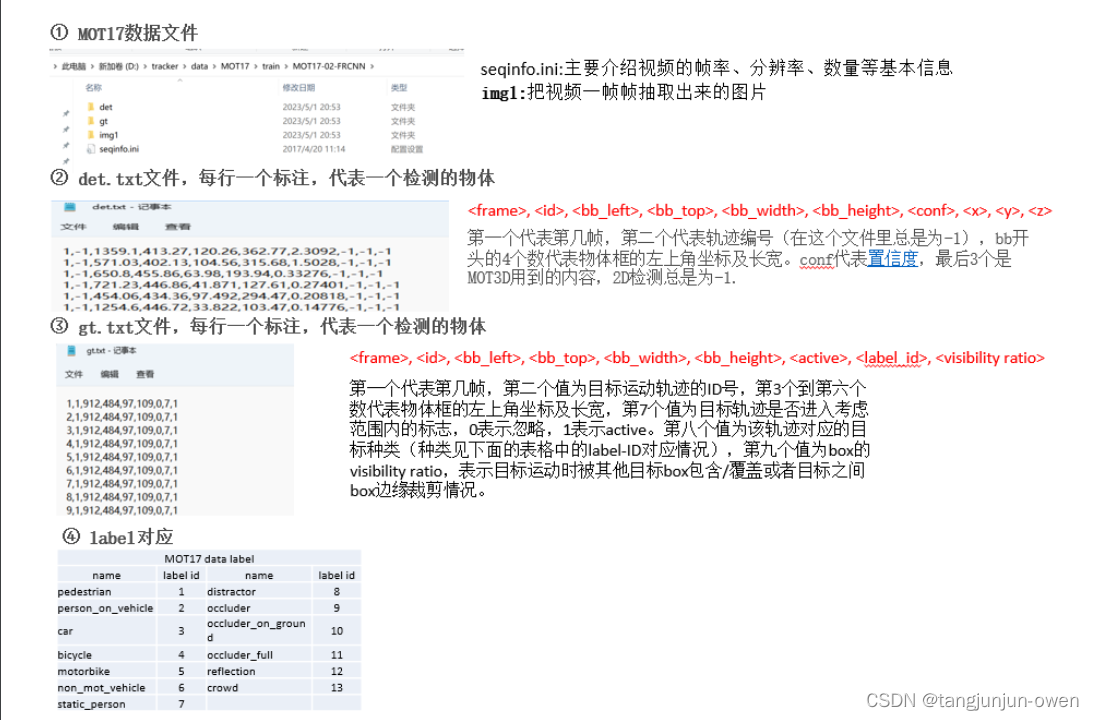
gt.txt数据格式:
frame, id, bb_left, bb_top, bb_width, bb_height, active, label_id, visibility ratio 第0个代表第几帧;
第1个值为目标运动轨迹的ID号;
第2个到第5个数代表物体框的左上角坐标及长宽;
第6个值为目标轨迹是否进入考虑范围内的标志,0表示忽略,1表示active;
第7个值为该轨迹对应的目标种类(种类见下面的表格中的label-ID对应情况);
第8个值为box的visibility ratio,表示目标运动时被其他目标box包含/覆盖或者目标之间box边缘裁剪情况。
特别说明:
第6个activate若为0表示该行目标不考虑计算。
第7个目标种类,目标名称和数字一定要对齐,依照数字指定为目标选择
如下:
"class_name_to_class_id":
{'pedestrian': 1, 'person_on_vehicle': 2, 'car': 3, 'bicycle': 4,
'motorbike': 5,'non_mot_vehicle': 6, 'static_person': 7,
'distractor': 8, 'occluder': 9, 'occluder_on_ground': 10,
'occluder_full': 11, 'reflection': 12, 'crowd': 13}
如图:
认识predect数据格式
*.txt预测文件结构
frame_id, id, bbox_left, bbox_top, bbox_w, bbox_h, -1, -1, -1, i
第0个的frame_id表示第几帧,没有0帧,只有第1帧开始,与gt.txt的帧对应;
第1个id表示跟踪id,由跟踪算法决定,实际为常说的track_id;
第2个到第5个数代表物体框的左上角坐标及长宽;
第9个i表示第frame_idx+1帧第几个目标id,也可以固定为-1,该参数不需要。
特别说明:
指标预测模型是第一帧到最后一帧by顺序一张一张图预测;
输出结果为预测txt保存结果,名称需和seq相同,如MOT17-02-FRCNN.txt
文件结构
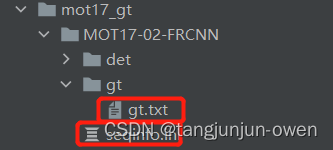
gt文件夹
主路径下是被测文件夹列表,每个列表文件(如:MOT17-02-FRCNN)下有一个gt.txt文件和seqinfo.ini文件,该路径可由config[‘GT_LOC_FORMAT’] = '{gt_folder}/{seq}/gt/gt.txt’参数控制。其中seqinfo.ini文件用于记录name=MOT17-02-FRCNN文件下相关信息,具体内容如下:
[Sequence]name=MOT17-02-FRCNNimDir=img1frameRate=30seqLength=600imWidth=1920imHeight=1080imExt=.jpg
然,seqinfo.ini只需提供seqLength信息,为此可简化如下:
[Sequence]seqLength=600
如图:
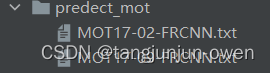
predect文件夹
主路径下只有对应txt文件,命名分别为gt文件对应的文件列表名称,MOT17-02-FRCNN.txt
具体方法如下图:
运行参数解释
在mot_challenge_2d_box.py文件夹下有类MotChallenge2DBox(_BaseDataset),用于处理相关数据,
而在该类中有一个默认default_config字典,我已做了修改,具体用法如下解释。
default_config = {'GT_FOLDER': os.path.join(code_path, 'data/'), # 真实标签路径Location of GT data'TRACKERS_FOLDER': os.path.join(code_path, 'data/predect_mot/'), # 预测标签路径 Trackers location'OUTPUT_FOLDER': None, # 指标保存路径,若为None将保存在TRACKERS_FOLDER文件下# 'TRACKERS_TO_EVAL': None, # Filenames of predect_mot to eval (if None, all in folder)'CLASSES_TO_EVAL': ['pedestrian'], # 规定哪些类别预测指标 Valid: ['pedestrian']'BENCHMARK': 'MOT17', # 用于显示名字,随便起名,我是以mot17为基准修改,因此默认为MOT17'PRINT_CONFIG': True, # Whether to print current config'DO_PREPROC': True, # Whether to perform preprocessing (never done for MOT15)'TRACKER_SUB_FOLDER': 'data', # Tracker files are in TRACKER_FOLDER/tracker_name/TRACKER_SUB_FOLDER'OUTPUT_SUB_FOLDER': '', # Output files are saved in OUTPUT_FOLDER/tracker_name/OUTPUT_SUB_FOLDER'TRACKER_DISPLAY_NAMES': None, # Names of predect_mot to display, if None: TRACKERS_TO_EVAL'SEQMAP_FOLDER': None, # Where seqmaps are found (if None, GT_FOLDER/seqmaps)'SEQMAP_FILE': None, # Directly specify seqmap file (if none use seqmap_folder/benchmark-split_to_eval)'SEQ_INFO': None, # 需要预测的列表,若为None则将GT_FOLDER文件均当做seq预测指标'GT_LOC_FORMAT': '{gt_folder}/{seq}/gt/gt.txt', # 能找到真实标签txt路径,gt_folder为GT_FOLDER,seq为seq_list遍历值'SKIP_SPLIT_FOL': False, # If False, data is in GT_FOLDER/BENCHMARK-SPLIT_TO_EVAL/ and in# TRACKERS_FOLDER/BENCHMARK-SPLIT_TO_EVAL/tracker/# If True, then the middle 'benchmark-split' folder is skipped for both."class_name_to_class_id": {'pedestrian': 1, 'person_on_vehicle': 2, 'car': 3, 'bicycle': 4, 'motorbike': 5,'non_mot_vehicle': 6, 'static_person': 7, 'distractor': 8, 'occluder': 9,'occluder_on_ground': 10, 'occluder_full': 11, 'reflection': 12, 'crowd': 13},'use_super_categories':False, # 决定是否合并类别为key类预测'super_categories' : {"FF": ['pedestrian', 'car']} # 表示将字典value类统一到key上,给出指标结果}
重点参数说明
①合并类指标测试方法
use_super_categories:参数为True将会将我们在super_categories指定合并类一起测试
'super_categories' :指定合并类,如将'pedestrian', 'car'合并为’FF‘,如: {"FF": ['pedestrian', 'car']}
②测试类指定方法
CLASSES_TO_EVAL:列表,指定gt.txt需要测试的类别,特别说明,它和gt.txt的第6个activate共同决定有效gt目标
③指定gt路径方法
GT_LOC_FORMAT:如{gt_folder}/{seq}/gt/gt.txt,确定gt路径
④指定测试方法
SEQ_INFO:指定gt_folder测试方法
⑤确定gt类别方法
class_name_to_class_id:指定名称和类别对应字典,gt.txt中的label id为对应数字,此为②提供依据
自定义参数
通过config字典,修改MotChallenge2DBox(_BaseDataset)中的默认参数,如下:
config={}config['TRACKERS_FOLDER'] = ROOT+'/data/predect_mot' # 预测路径config['GT_FOLDER'] = ROOT+'/data/mot17_gt' # 给出gt路径config['OUTPUT_FOLDER'] = ROOT+'/data/out_dir'# 确定文件内gt.txt的路径,gt_folder=config['GT_FOLDER'],seq为os.listdir(gt_folder)列表config['GT_LOC_FORMAT'] = '{gt_folder}/{seq}/gt/gt.txt'config['CLASSES_TO_EVAL'] = ['pedestrian'] # 确定预测指标的类别dataset = MotChallenge2DBox(config) # dataset_list是存放数据信息列表运行命令
按照以上参数修改,直接运行run_mot_challenge.py文件
可视化工具
mot_vision.py文件用于将gt.txt信息可视化图像上,效果如下图:

测试结果
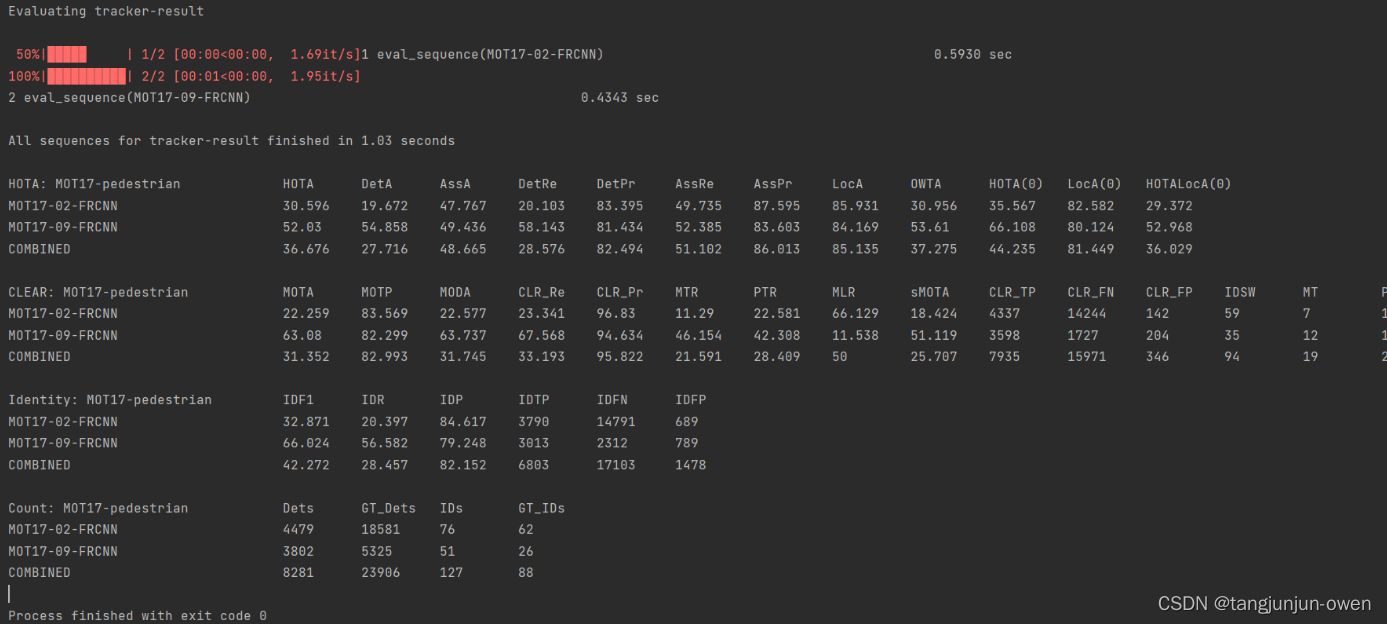
这篇关于跟踪指标预测代码(track eval)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





